

深度学习基础
深度学习是什么
深度学习是通过深度神经网络的机器学习方法。简单来说,深度学习是对一个含有可学习参数 的神经网络 ,利用梯度下降的方法优化损失函数 ,从而实现对数据集 的拟合。
下面是一个图像分类任务上的 LeNet 网络,使用 PyTorch 搭建
import torch
from torch import nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 卷积层1
self.conv2 = nn.Conv2d(6, 16, 5) # 卷积层2
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层1
self.fc2 = nn.Linear(120, 84) # 全连接层2
self.fc3 = nn.Linear(84, 10) # 全连接层3,实现10分类
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = out.view(out.size(0), -1) # 展平
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out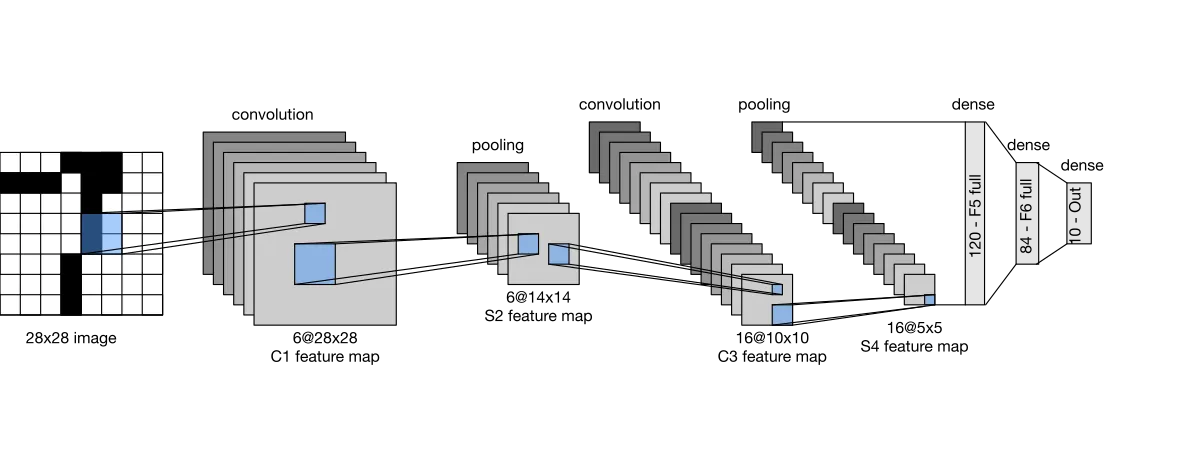
深度学习的应用的典型领域
- 计算机视觉
- 图像分类
- 图像分割
- 语义分割
- 实例分割
- 全景分割
- 目标检测
- 图像生成
- 图像超分辨率
- 姿态估计
- 自然语言处理
- 机器翻译
- 文本分类
- 情感分析
- 问答系统
- 文本生成
- 语言模型
- 语音处理
- 语音识别
- 语音合成
- 声纹识别
- 音乐生成
- 多模态学习
- 图像描述
- 视觉问答
- 文本到图像生成
- 深度强化学习
- 游戏智能体
- 机器人控制
- 自动驾驶
机器学习系统的组成部分
深度学习系统本质上仍然是机器学习系统,在定义了机器学习系统后,就可以用数据集对模型进行训练从而拟合出一个函数出来。一般地,机器学习系统的组成部分如下
- 假设空间,即模型的集合,一般会满足某种架构
- 损失函数
- 优化器
例如,线性模型
设。为了方便进行矩阵计算,设有个batch,,于是
损失函数通常有如下形式:
L2损失(均方误差):
Cross-Entropy:
其中表示第个样本的第个真实标签,表示模型对第个样本的第个标签的预测值。
为了使得损失函数最小,这也是我们期望模型所能做到的,即能够拟合一个函数出来,我们需要一个优化器来进行参数的更新。通常采用的方法是梯度下降法(Gradient Descent)。
Gradient Descent:
其中为学习率,为损失函数对参数的梯度。
由于一次性计算对全部样本的损失以及对应的梯度会消耗大量的计算内存,因此我们通常采用mini-batch的方法来进行训练。即每次只计算一个batch的样本的损失和梯度。对应的梯度下降的方法为随机梯度下降(Stochastic Gradient Descent)。
Stochastic Gradient Descent:
其中为对单个样本,即第个样本的损失函数。
对于深度学习的系统,在定义好模型、损失函数和优化器后,就可以用下面的深度学习框架进行拟合了。
深度学习框架
深度学习的基本计算流程涉及到前向传播(计算预测结果)、反向传播(计算损失函数梯度) 和 优化参数三个部分,因此一个成熟的深度学习框架也主要就负责这三个部分的处理,通过构建一个计算图实现。
此外,由于深度学习的函数通常是多维张量计算,具有较高的数据并行性,因此深度学习框架也需要具有和高并行处理单元如 GPU、NPU 等有很好的接口结合。
- 前端:面向用户,应能够简便且灵活的定义深度神经网络模型
- 算子:用于执行计算,如卷积算子
- 求导:用于更新参数,需要提供自动求导的计算方式
- 后端:需要将算子部署在不同的加速设备上
反向传播计算梯度是由框架自行完成的,称为自动微分(Automatic Differentiation,AD)。这是一种通过将复杂函数分解为基本操作,并利用链式法则来计算导数的方法。这里直接通过数值方法计算梯度是不可行的,一方面是存在数值误差问题,另一方面是计算复杂度过高。但是,数值梯度的作用也是有的,在当前的深度学习框架中,为了验证反向传播算法的正确性,框架通常还会使用数值梯度(Numerical Gradient)来自动进行验证。
框架的具体的两种极端的实现方式
1.高灵活性(高复杂性)
import numpy as np
N, D = 3, 4
def mla(x: np.ndarray, y: np.ndarray, z: np.ndarray):
# 前向传播
a = x * y
b = a + z
c = np.sum(b)
# 反向传播
grad_c = 1.0
grad_b = grad_c * np.one_like(b)
grad_a = grad_b.copy()
grad_z = grad_b.copy()
grad_x = grad_a * y
grad_y = grad_a * x
return c, grad_x, grad_y, grad_z2.高效性(低修改性)
import torchvision.models as models
x, y = load_data()
model = models.resnet152(pretrained=True) # 模型是提前打包好的
outputs = model(x)一个好的深度学习框架应该可以
- 提供灵活的编程模型和接口
- 提供高效和可扩展性的计算能力
早期深度学习框架的局限
层的实现不灵活
每当出现一个新的层时,都需要专门编写它的前向传播和反向传播的函数,限制了编程的灵活性。也就是说,早期的深度学习框架用基于层的方式实现计算。
而现代深度学习框架则是通过构建计算图的方式实现计算流程,计算图的基本单元是一个个基础运算(加减乘除等)的门电路,灵活性更高。
优化器的实现不灵活
对于早期框架,新的优化器出现需要定义新的参数更新范式,不灵活。
简单的 “前向 + 后向” 的计算模式限制了新的训练范式
当前的神经网络的训练范式中往往会夹杂一些特定的模式,如强化学习需要与外界交互收集经验数据、对抗网络需要 Generator 和 Discriminator 交替训练,简单的 前向 + 后向 无法满足。
现代深度学习框架的特点
计算图的实现方式
- 基本的数据结构是 阶 Tensor
- 基本的运算单元是操作子
| 操作子类别 | 具体操作子 | 功能描述 | 典型应用 |
|---|---|---|---|
| 数学运算操作 | 加法(Add) | 对两个张量执行元素级加法 | 残差连接、特征融合 |
| 减法(Subtract) | 对两个张量执行元素级减法 | 特征差异计算 | |
| 乘法(Multiply) | 对两个张量执行元素级乘法 | 注意力机制、门控机制 | |
| 除法(Divide) | 对两个张量执行元素级除法 | 归一化计算 | |
| 幂运算(Power) | 计算张量的幂 | 特征变换 | |
| 矩阵乘法(MatMul) | 执行矩阵乘法 | 全连接层、线性变换 | |
| 神经网络操作 | 卷积(Convolution) | 执行N维卷积操作 | CNN网络、图像处理 |
| 转置卷积(TransposedConv) | 执行转置卷积 | 上采样、生成网络 | |
| 最大池化(MaxPool) | 执行最大池化 | 特征降维、空间不变性 | |
| 平均池化(AvgPool) | 执行平均池化 | 特征降维、平滑处理 | |
| 批归一化(BatchNorm) | 对批次数据进行归一化 | 稳定训练、加速收敛 | |
| 层归一化(LayerNorm) | 对层数据进行归一化 | Transformer模型 | |
| 激活函数 | ReLU | 线性整流函数 | 引入非线性,防止梯度消失 |
| Sigmoid | S形激活函数 | 二分类输出层 | |
| Tanh | 双曲正切函数 | RNN、早期网络 | |
| Softmax | 将向量归一化为概率分布 | 多分类输出层 | |
| GELU | 高斯误差线性单元 | Transformer模型 | |
| 形状操作 | 重塑(Reshape) | 改变张量形状 | 数据预处理 |
| 转置(Transpose) | 交换张量维度 | 矩阵运算准备 | |
| 连接(Concat) | 沿指定维度连接张量 | 特征融合 | |
| 展平(Flatten) | 将张量展平成向量 | 连接卷积层与全连接层 | |
| 切片(Slice) | 提取张量的子集 | 特征选择 | |
| 梯度与优化 | 梯度计算(Gradient) | 计算函数对输入的梯度 | 反向传播 |
| 随机丢弃(Dropout) | 随机置零部分神经元 | 正则化、防止过拟合 | |
| 损失函数 | 交叉熵(CrossEntropy) | 计算预测与真实标签的交叉熵 | 分类问题 |
| 均方误差(MSE) | 计算预测值与真实值的平方差 | 回归问题 |
- 计算图的节点是操作子
- 计算图的边是 Tensor
计算图的实现方式有动态数据流图和静态数据流图两种,其中 TensorFlow 是静态数据流图, PyTorch 主要是动态数据流图(其实也有 jit 等工具可以实现静态数据流图)
- 静态数据流图就是先定义好计算图后才执行计算,优点是能全局优化、内存利用效率高,缺点是调试困难
- 动态数据流图则是边定义边运行,每次编译时都需要构建一个新的计算图,在运行中数据流图是变化的 (例如引入了分支指令),优点是代码简洁灵活性好,缺点是无法全局优化
深度学习框架实践——PyTorch
神经网络模型搭建的核心在于要把输入进模型的张量和各个中间张量的形状要把握清楚
图像分类
图像分类是深度学习中最基础也最重要的任务之一,其目标是为输入图像分配给预定义的类别标签。这个任务广泛应用于人脸识别、医学诊断、自动驾驶等领域。图像分类的评价指标包括
准确率(Accuracy) :
- 最直观的评价指标,表示正确预测的样本数占总样本数的比例
- 公式:
- PyTorch实现:
accuracy = (predicted == labels).sum().item() / labels.size(0)
精确率(Precision)与召回率(Recall) :
- 精确率:在所有被预测为正类的样本中,真正为正类的比例
- 召回率:在所有真正为正类的样本中,被正确预测的比例
- 公式:
F1分数 :
- 精确率和召回率的调和平均数
- 公式:
多层感知机 (MLP) 与 MNIST
多层感知机是一种前馈神经网络,由多层全连接层组成。
class MLP(nn.Module):
def __init__(self, input_size=784, hidden_sizes=[512, 256], output_size=10):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_sizes[0]) # 隐藏层1
self.fc2 = nn.Linear(hidden_sizes[0], hidden_sizes[1]) # 隐藏层2
self.output_layer = nn.Linear(hidden_sizes[1], output_size) # 输出层
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
x = torch.relu(x)
x = self.output_layer(x)
return xMNIST数据集是机器学习领域中最经典和广泛使用的数据集之一,特别适合作为深度学习入门的基准测试。它包含了60,000张训练图像和10,000张测试图像,每张图像为28×28像素的手写数字(0-9)灰度图像。
- 下载实践代码:在MNIST手写数字数据集上训练MLP分类器
卷积神经网络 (CNN) 与 CIFAR10
卷积神经网络是一种专门用于处理网格结构数据(如图像)的神经网络。下面是一个使用PyTorch实现的简单CNN模型,用于CIFAR-10图像分类任务。
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) # 第一个卷积层 (输入通道3, 输出通道32, 3x3卷积核)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # 第二个卷积层 (输入通道32, 输出通道64, 3x3卷积核)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1) # 第三个卷积层 (输入通道64, 输出通道128, 3x3卷积核)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2) # 池化层
self.fc1 = nn.Linear(128 * 4 * 4, 512) # 全连接层1
self.fc2 = nn.Linear(512, 10) # 全连接层2 (输出层)
self.dropout = nn.Dropout(0.5) # Dropout层
def forward(self, x):
x = self.conv1(x)
x = torch.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = torch.relu(x)
x = self.pool(x)
x = self.conv3(x)
x = torch.relu(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = torch.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return xCIFAR-10数据集包含10个类别的32x32彩色图像,共50,000张训练图像和10,000张测试图像。上述CNN模型包含三个卷积层和两个全连接层。每个卷积层后跟ReLU激活函数和最大池化操作,以减小特征图的空间尺寸并提取重要特征。最后,通过全连接层实现分类,并使用Dropout技术防止过拟合。
- 下载实践代码: 在CIFAR10上训练CNN分类器
图像分割
图像分割的目标是将图像划分为多个有意义的区域或对象。与图像分类不同,分割需要在像素级别上进行预测,为每个像素分配一个类别标签。图像分割在医学图像分析、自动驾驶、遥感图像处理等领域有广泛应用。根据任务的性质,图像分割可以分为以下几类
- 语义分割(Semantic Segmentation):为图像中的每个像素分配一个类别标签,但不区分同一类别的不同实例。
- 实例分割(Instance Segmentation):不仅识别像素所属的类别,还区分同一类别的不同实例。
- 全景分割(Panoptic Segmentation):结合语义和实例分割,为每个像素分配类别和实例ID。
图像分割的评价指标有
像素准确率(Pixel Accuracy) :
- 被正确分类的像素数量与总像素数的比值
- 公式:
- 其中是被预测为类别但实际属于类别的像素数
平均像素准确率(Mean Pixel Accuracy) :
- 每个类别的像素准确率的平均值
- 公式:
交并比(IoU, Intersection over Union) :
- 也称为Jaccard指数,衡量预测分割与真实分割的重叠度
- 公式:
- 对于特定类别:
平均交并比(mIoU, Mean Intersection over Union) :
- 所有类别IoU的平均值
- 公式:
- 是图像分割任务中最常用的评价指标之一
Dice系数(Dice Coefficient) :
- 衡量两个样本集的相似度,也称为F1分数
- 公式:
- 与IoU密切相关:
U-Net 与 Oxford Pet
U-Net是一种经典的用于图像分割的卷积神经网络架构,特别适合医学图像分割等任务。下面是一个使用PyTorch从头实现的U-Net模型:
# 定义U-Net模块
class DoubleConv(nn.Module):
"""(卷积 => BN => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""下采样:最大池化 + 双卷积"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""上采样:转置卷积 + 拼接 + 双卷积"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# 可以选择双线性插值或转置卷积进行上采样
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# 处理输入size不匹配的问题
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# 拼接两个特征图
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
"""输出卷积层"""
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
# 完整的U-Net模型
class UNet(nn.Module):
def __init__(self, n_channels=3, n_classes=3, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
# 编码器部分
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
# 解码器部分
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
# 编码路径
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
# 解码路径 + 跳跃连接
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logitsU-Net是一种专为医学图像分割设计的卷积神经网络架构,由Olaf Ronneberger等人在2015年提出。它的特点是具有对称的U形结构,包含一个下采样的编码路径和一个上采样的解码路径,以及在对应层之间的跳跃连接(skip connections)。这些跳跃连接能够将编码阶段的高分辨率特征直接传递到解码阶段的相应层,有效地保留空间信息,对精确分割边界非常重要。
Oxford-IIIT Pet数据集包含约7,400张猫和狗的图像,来自37个不同品种。每张图像都有对应的像素级分割标注,将图像分为前景(宠物)、背景和边界三个类别。这个数据集是用于语义分割任务的,因为它为每个像素分配类别标签(前景/背景/边界),但不区分同一类别的不同实例。这个数据集非常适合训练和评估像U-Net这样的分割网络。数据集的难点在于目标对象(宠物)的姿势、大小和背景变化多样,为图像分割模型提供了很好的挑战。
 图像分割是一个比较困难的任务
图像分割是一个比较困难的任务
- 下载实践代码: 在Oxford Pet数据集上训练Unet分割网络
图像生成
图像生成是一项旨在创建新的、逼真的图像的任务。它是生成式人工智能的一个重要分支,近年来随着深度学习技术的发展取得了显著进展。图像生成模型可以从随机噪声、文本描述、条件输入或已有图像创建全新的视觉内容。
常见的图像生成模型包括:
- 生成对抗网络(GANs):通过生成器和判别器的对抗训练生成逼真图像
- 变分自编码器(VAEs):学习数据的潜在分布并从中采样生成新图像
- 自回归模型:像素级别的条件生成,如PixelRNN和PixelCNN
- 扩散模型:如DDPM和Stable Diffusion,通过逐步去噪过程生成图像
- 流模型:如Glow,通过可逆变换学习数据分布
图像生成的评价指标
评估生成图像的质量是一个具有挑战性的问题,因为”好”的图像往往是主观的。然而,研究者已经开发出一系列客观指标:
Inception Score (IS) :
- 衡量生成图像的多样性和质量
- 高IS分数表示生成的图像既清晰(每个图像的类别分布有较高的置信度)又多样(不同图像的类别分布各不相同)
- 公式:
Fréchet Inception Distance (FID) :
- 测量生成图像与真实图像分布之间的距离
- 较低的FID表示生成的图像更接近真实分布
- 公式:
- 其中分别是真实和生成图像特征的均值,是对应的协方差矩阵
结构相似性指数(SSIM) :
- 比较两幅图像在亮度、对比度和结构上的相似程度
- 适用于条件图像生成(如图像转换、超分辨率等)
- 范围在[-1,1]之间,1表示完全相同
峰值信噪比(PSNR) :
- 衡量重建图像与原始图像的对应像素差异
- 主要用于图像重建和修复任务
- 单位为分贝(dB),值越高表示重建质量越好
Learned Perceptual Image Patch Similarity (LPIPS) :
- 基于深度特征的感知相似度度量
- 比像素级指标更符合人类视觉感知
- 值越低表示感知相似度越高
人类评估:
- 人类评价者对生成图像的质量进行主观评分
- 通常采用均值意见得分(MOS)或AB测试
- 最直接但成本高且难以大规模实施
评估图像生成模型时,最好结合多个指标,因为每种指标都有其优缺点和适用场景。例如,FID在评估无条件生成模型时很流行,而PSNR和SSIM则更适合条件生成任务。
变分自编码器 与 MNIST
变分自编码器(VAE)是一种生成式模型,它可以学习数据的概率分布,并生成与原始数据相似的新样本。条件变分自编码器(CVAE)通过添加条件信息(如类标签)来控制生成过程。
以下是一个使用PyTorch实现的条件变分自编码器(CVAE),用于MNIST数字图像的条件生成。
# 条件变分自编码器模型
class CVAE(nn.Module):
def __init__(self, latent_dim, num_classes):
super(CVAE, self).__init__()
self.img_size = 28 # 图像大小和条件信息
self.latent_dim = latent_dim
self.num_classes = num_classes
self.encoder = nn.Sequential( # 编码器网络
nn.Conv2d(1 + num_classes, 32, kernel_size=3, stride=2, padding=1), # 14x14
nn.LeakyReLU(0.2),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 7x7
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), # 7x7
nn.LeakyReLU(0.2),
nn.Flatten()
)
self.flat_size = 128 * 7 * 7 # 计算展平后的特征大小
self.fc_mu = nn.Linear(self.flat_size, latent_dim) # 均值和方差预测层
self.fc_logvar = nn.Linear(self.flat_size, latent_dim)
self.decoder_input = nn.Linear(latent_dim + num_classes, 128 * 7 * 7) # 解码器输入层
self.decoder = nn.Sequential( # 解码器网络
nn.Unflatten(1, (128, 7, 7)),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # 14x14
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1), # 28x28
nn.LeakyReLU(0.2),
nn.Conv2d(32, 1, kernel_size=3, stride=1, padding=1),
nn.Sigmoid() # 输出像素值在[0,1]之间
)
def encode(self, x, c):
c = c.view(-1, self.num_classes, 1, 1).expand(-1, -1, self.img_size, self.img_size) # 将条件信息嵌入到输入中
x_c = torch.cat([x, c], dim=1) # 在通道维度上拼接
h = self.encoder(x_c) # 编码器前向传播
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar) # 重参数化技巧
eps = torch.randn_like(std)
z = mu + eps * std
return z
def decode(self, z, c):
z_c = torch.cat([z, c], dim=1) # 将条件信息与潜在表示拼接
h = self.decoder_input(z_c) # 解码器前向传播
x_recon = self.decoder(h.view(-1, 128, 7, 7))
return x_recon
def forward(self, x, c):
c_onehot = F.one_hot(c, self.num_classes).float() # 将类标签转换为one-hot向量
mu, logvar = self.encode(x, c_onehot) # 编码
z = self.reparameterize(mu, logvar) # 采样潜在表示
x_recon = self.decode(z, c_onehot) # 解码
return x_recon, mu, logvar
def sample(self, num_samples, c):
"""
给定条件c,生成样本
c: (num_samples,) 类标签
"""
c_onehot = F.one_hot(c, self.num_classes).float() # 将类标签转换为one-hot向量
z = torch.randn(num_samples, self.latent_dim).to(device) # 从标准正态分布采样潜在向量
samples = self.decode(z, c_onehot) # 解码生成样本
return samples插值实验

生成的手写数字
![]()
- 下载实践代码: 在MNIST数据集上训练VAE生成网络
PyTorch使用小结
自定义数据集
在 PyTorch 中,只需继承 torch.utils.data.Dataset 并实现以下两个方法,即完成了一个数据集的定义
__len__:返回样本总数__getitem__:根据索引返回单个样本(通常是(数据, 标签))
示例代码:
import os
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class MyImageDataset(Dataset):
def __init__(self, img_dir, labels, transform=None):
"""
img_dir: 存放图片的文件夹路径
labels: dict, { 'img1.jpg': 0, 'img2.jpg': 1, ... }
transform: torchvision.transforms.Compose
"""
self.img_dir = img_dir
self.labels = labels
self.transform = transform
self.filenames = list(labels.keys())
def __len__(self):
return len(self.filenames)
def __getitem__(self, idx):
fname = self.filenames[idx]
img_path = os.path.join(self.img_dir, fname)
image = Image.open(img_path).convert('RGB')
label = self.labels[fname]
if self.transform:
image = self.transform(image)
return image, label
# 使用方式
transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5]*3, std=[0.5]*3),
])
# 假设有一个字典 labels_map
dataset = MyImageDataset(img_dir='data/images', labels=labels_map, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)模型训练范式
PyTorch 的模型训练范式通常是如下形式
import torch
def train_one_epoch(model, dataloader, optimizer, criterion, device):
model.train()
total_loss = 0
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item() * inputs.size(0)
avg_loss = total_loss / len(dataloader.dataset)
print(f"Train Loss: {avg_loss:.4f}")
return avg_loss
def evaluate(model, dataloader, criterion, device):
model.eval()
total_loss = 0
correct = 0
with torch.no_grad():
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
total_loss += loss.item() * inputs.size(0)
pred = outputs.argmax(dim=1)
correct += (pred == targets).sum().item()
avg_loss = total_loss / len(dataloader.dataset)
accuracy = correct / len(dataloader.dataset)
print(f"Val Loss: {avg_loss:.4f}, Acc: {accuracy:.4f}")
return avg_loss, accuracy
# 主训练循环
for epoch in range(1, epochs+1):
train_loss = train_one_epoch(model, train_loader, optimizer, criterion, device)
val_loss, val_acc = evaluate(model, val_loader, criterion, device)
# 如果使用学习率调度器,可在此处 step
# scheduler.step(val_loss)Profiler 工具
PyTorch Profiler 是一个内置的性能分析工具,可以帮助识别模型训练和推理过程中的训练瓶颈。Profiler 会收集 GPU 或 CPU 的详细运行实践统计信息,从而提供深入的性能分析和可视化。
基本使用
经典形式
def profile(model, device, data_loader):
dataiter = iter(data_loader)
data, target = next(dataiter)
data, target = data.to(device), target.to(device)
# use_cuda=False,是只分析GPU
with torch.autograd.profiler.profile(use_cuda=False) as prof:
model(data[0].reshape(1,1,28,28))
print(prof)更现代的API形式
from torch import profiler
def profile(model, device, data_loader):
with profiler.profile(
activities=[
profiler.ProfilerActivity.CPU,
profiler.ProfilerActivity.CUDA,
],
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
# 需要分析的代码
data, target = next(iter(data_loader))
data, target = data.to(device), target.to(device)
model(data)
print(prof.key_averages().table(sort_by='cuda_time_total', row_limit=10))与训练循环集成的形式
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./profiler_logs'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, (inputs, labels) in enumerate(dataloader):
if step >= (1 + 1 + 3) * 1:
break
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
prof.step() # 必须调用,与 schedule 配合使用服务器使用
服务器登录
服务器一般可以通过 vscode 等 IDE 使用 ssh 进行连接,具体使用方式可以参考相关资料(例如知乎上的讲解)。除了使用 IDE 连接外,本地的终端也是可以连接服务器的。在终端中输入下列指令后
ssh ada@10.184.16.88 # 服务器账号名@服务器ip地址即可登录服务器,连接到服务器的终端。如果账号设有密码,终端会提示输入密码。
Vim
服务器代码编辑一般是使用 vscode 等 IDE。不过当使用终端登录时,也可以使用 vim 等编辑器编辑代码。使用 Vim 打开代码脚本的指令为
vim train.py # 打开 train.py 文件常用 Vim 指令
| 命令 | 作用 |
|---|---|
i | 在光标处进入插入模式 |
a | 在光标后进入插入模式 |
I | 在行首进入插入模式 |
A | 在行尾进入插入模式 |
o | 在当前行下方新开一行并进入插入模式 |
O | 在当前行上方新开一行并进入插入模式 |
<Esc> | 退出插入模式 |
h/j/k/l | 光标左/下/上/右移动 |
w | 跳到下一个单词开头 |
b | 跳到当前/上一个单词开头 |
e | 跳到当前/下一个单词末尾 |
0 | 跳到行首 |
^ | 跳到本行第一个非空字符 |
$ | 跳到行尾 |
G | 跳到文件末尾 |
gg | 跳到文件开头 |
:数字 | 跳到指定行 |
f<char> | 当前行向右查找并跳到下一个 <char> |
t<char> | 当前行向右查找并跳到 <char> 之前的位置 |
F<char> | 当前行向左查找并跳到下一个 <char> |
t<char> | 当前行向左查找并跳到 <char> 之后的位置 |
cw | 删除从光标到单词末尾并进入插入 |
cc | 删除整行并进入插入 |
C | 删除从光标到行尾并进入插入 |
r<char> | 替换光标下单个字符为 <char> |
R | 进入替换模式(Overwrite) |
u | 撤销上一步操作 |
Ctrl+r | 重做(撤销的反向操作) |
. | 重复上一次编辑操作 |
yy | 复制(yank)当前行 |
yw | 复制从光标到单词末尾 |
p | 在光标后粘贴 |
P | 在光标前粘贴 |
dd | 删除(剪切)当前行 |
d<number>d | 删除从当前行起连续多行(如 3dd 删除 3 行) |
df<char> | 删除到并包含下一个 <char> |
d$ | 删除到行尾 |
v | 进入可视模式(按字符选区) |
V | 进入可视行模式 |
Ctrl+v | 进入可视块模式 |
:s/old/new/g | 全文替换 old 为 new |
:%s/old/new/gc | 全文替换并交互确认 |
:set number | 显示行号 |
:set nonumber | 关闭行号显示 |
:set hlsearch | 高亮搜索结果 |
:set nohlsearch | 取消高亮 |
:tabnew [file] | 新建选项卡并打开文件 |
:tabnext/:tabprev | 切换到下一个/上一个选项卡 |
:split [file] | 水平分屏打开文件 |
:vsplit [file] | 垂直分屏打开文件 |
Ctrl+w h/j/k/l | 在分屏间移动光标 |
qa | 开始录制宏到寄存器 a |
q | 停止录制宏 |
@a | 播放寄存器 a 中的宏 |
@@ | 重复上一个宏播放 |
:w | 保存当前文件 |
:q | 退出 Vim |
:wq 或 :x | 保存并退出 |
ZZ | 保存并退出(在普通模式下输入) |
:q! | 不保存强制退出 |
:qa | 退出所有打开的文件 |
:qa! | 强制退出所有,无需保存 |
:w filename | 将当前缓冲区另存为 filename |
:e filename | 打开或切换到 filename |
NVIDIA 环境查看
在深度学习服务器上,我们常用下面的命令来检查 GPU、驱动和 CUDA 环境是否就绪
# 查看 NVIDIA 驱动与 GPU 状态
nvidia-smi
# 查看 CUDA 工具包版本
nvcc --version
# 查看已安装的 PyTorch 是否支持 CUDA
python -c "import torch; print('CUDA 可用:', torch.cuda.is_available())"CUDA (Compute Unified Device Architecture) 是一种由 NVIDIA 退出的通用并行计算架构,该架构使用 GPU 解决复杂的计算问题,包含 CUDA 指令集架构 (ISA) 以及 GPU 内部的并行计算引擎。
训练过程可视化
TensorBoard
在 PyTorch 中可以非常方便地集成 TensorBoard,以实时监控训练过程中的指标、可视化网络结构和图像。
1. 安装
pip install tensorboard2. 在训练脚本中添加 SummaryWriter
from torch.utils.tensorboard import SummaryWriter
# 指定日志目录
writer = SummaryWriter(log_dir='runs/exp1')
for epoch in range(1, epochs+1):
# 训练循环
train_loss, train_acc = train_one_epoch(...)
val_loss, val_acc = evaluate(...)
# 记录标量
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Loss/val', val_loss, epoch)
writer.add_scalar('Acc/train', train_acc, epoch)
writer.add_scalar('Acc/val', val_acc, epoch)
# 可视化参数分布或梯度
for name, param in model.named_parameters():
writer.add_histogram(f'Param/{name}', param, epoch)
writer.add_histogram(f'Grad/{name}', param.grad, epoch)
# 第一次记录时可添加网络结构图
if epoch == 1:
dummy_input = torch.randn(1, 3, 224, 224).to(device)
writer.add_graph(model, dummy_input)
# 训练结束后关闭
writer.close()3. 启动 TensorBoard
tensorboard --logdir='./runs' --port 6006然后在浏览器打开 http://localhost:6006 ,即可看到实时更新的训练曲线、直方图和网络结构。
如果是在服务器上运行的训练过程,需要使用 端口映射 才能在本地网页查看。
# 本地端口 7007 转发到服务器的 localhost:6006
ssh -L 7007:localhost:6006 ada@10.184.16.88然后在浏览器打开 http://localhost:7007 即可查看。
4. 使用 TensorBoard 可视化 Profiler 结果
tensorboard --logdir=./profiler_logsWeights & Biases (W&B)
Weigths & Biases(简称 W&B)是一款流行的实验管理与可视化平台,能够帮助你在云端实时跟踪、可视化训练指标、超参、模型权重和数据集版本,并自动生成对比报告。
1. 安装与登录
pip install wandb
wandb login # 首次运行后按提示粘贴 API key2. 在训练脚本中集成 W&B
import wandb
from torch.utils.tensorboard import SummaryWriter
# 1 初始化一个 run,project 名称可自定义
wandb.init(project="my-deeplearning-project", config={
"epochs": epochs,
"batch_size": batch_size,
"lr": learning_rate,
"latent_dim": latent_dim,
})
# 2 自动追踪模型、梯度和超参
wandb.watch(model, log="all", log_freq=100)
for epoch in range(1, epochs+1):
train_loss, train_acc = train_one_epoch(...)
val_loss, val_acc = evaluate(...)
# 3 记录标量
wandb.log({
"epoch": epoch,
"loss/train": train_loss,
"loss/val": val_loss,
"acc/train": train_acc,
"acc/val": val_acc,
})
# 4 保存最佳模型到 W&B Artifacts
torch.save(model.state_dict(), "best_model.pth")
wandb.save("best_model.pth")
# 5 结束 run
wandb.finish()3. 在 W&B 仪表盘查看
- 浏览器打开 https://wandb.ai
- 进入你所在的 project,即可查看训练曲线、超参对比、模型参数直方图、图片和对比报告。
- 支持自动对比多个 runs,以及与团队成员共享结果。
参考资料: