

张量计算,计算机体系结构,编译器与编译优化
张量计算
简单地说,张量可以理解为是数字的一类阵列,例如
- 零阶张量是标量
- 一阶张量是向量 (行、列)
- 二阶张量是矩阵 (表格)
- 三阶张量是一种长方体排列形式的阵列 (立体)
深度学习中的绝大部分计算都可以表示为张量计算的形式,下面给出的例子中数学公式部分将主要用矩阵形式介绍,代码部分张量的阶数视情况而定
全连接层(线性层)
设输入 , 代表样本个数, 代表每一个样本的数据通道维度。线性层可以用一个线性映射表示,设权重 ,偏置 ,则线性层的输出为
这里 不直接采用 的形式是因为,当只有单个样本 作为输入时,对应输出可以表示为
这个形式更加符合数学上的习惯。
在 PyTorch 中,线性层是作用在张量 的最后一个维度上,即其权重矩阵只与最后一个维度相乘,输入张量其他维度的形状大小保持不变,得到输出
# PyTorch 中线性层的权重形状也是按照 (out_features, in_features) 的形式存储的
linear = nn.Linear(5, 10)
print(linear.weight.shape) # weight 形状 (10, 5)
X = torch.ones(4, 3, 5, 5) # X 形状 (4, 3, 5, 5)
Y = linear(X)
print(Y.shape) # Y 形状 (4, 3, 5, 10)卷积层
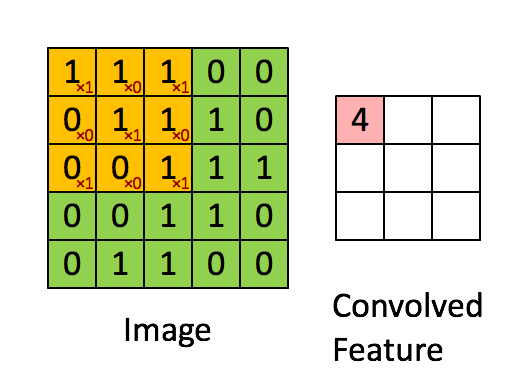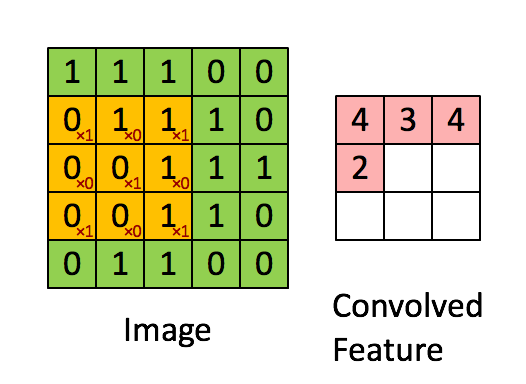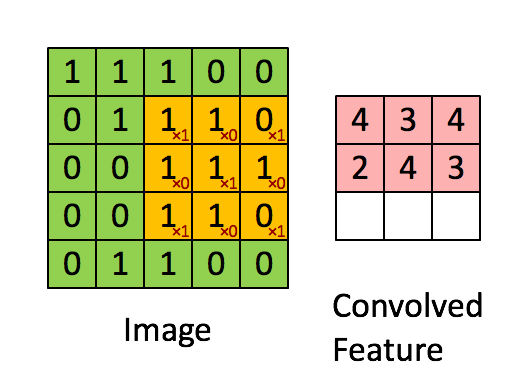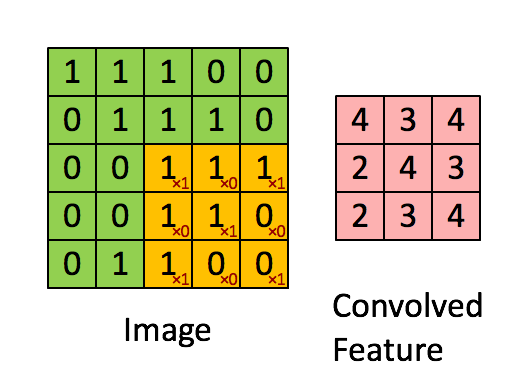
设输入 ,其中 是批量大小, 是输入通道数, 和 分别是输入特征图的高度和宽度。卷积核 ,其中 是输出通道数, 和 分别是卷积核的高度和宽度。则二维卷积的输出 可以表示为
上式假设使用了适当的填充(padding)使输出尺寸与输入相同。实际应用中,输出尺寸还受步长(stride)和填充(padding)参数的影响,
在 PyTorch 中,卷积层可以如下使用:
# 创建一个卷积层,输入通道3,输出通道16,卷积核尺寸3x3
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
print(conv.weight.shape) # 形状 (16, 3, 3, 3)
X = torch.randn(32, 3, 28, 28) # 批量大小32,3通道,28x28图像
Y = conv(X)
print(Y.shape) # 形状 (32, 16, 28, 28)卷积运算也可以表示成矩阵运算的形式,通过重组输入张量,卷积计算可以被转换成矩阵乘法
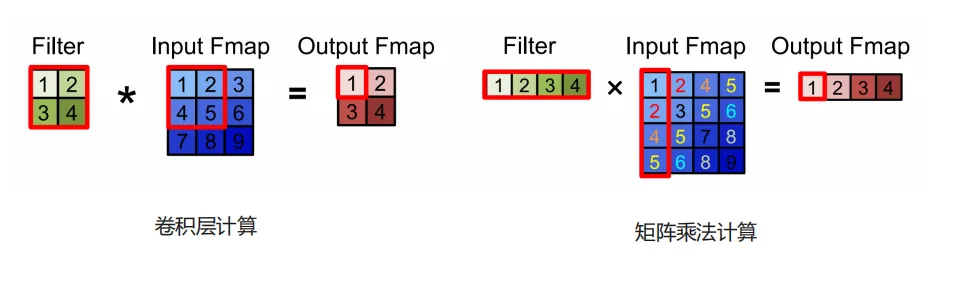
在硬件上的卷积实现也是采用的矩阵形式,通过将输入特征图的局部感受野展开称列(如图,各列存在元素的重叠),将卷积核展开成行的形式,就能够使用高效的矩阵乘法得到卷积后的结果。(显然行列的长度不可能没有限制,因此计算是有分块的)
Attention 机制
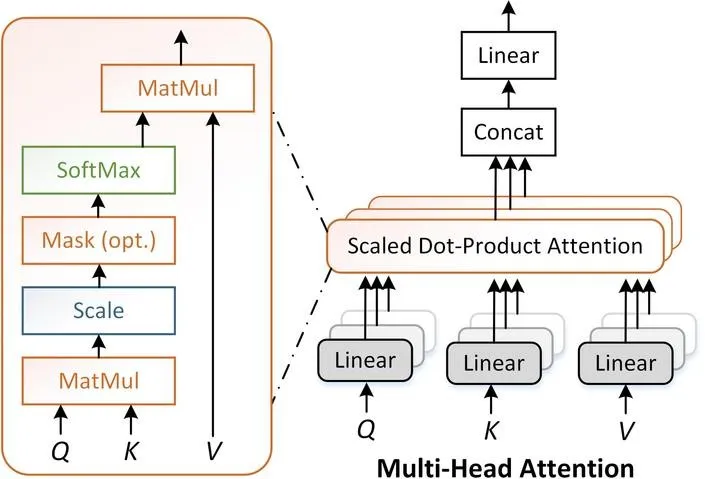
Attention 机制是现代深度学习模型中的关键组件,特别是在 Transformer 架构中。设输入序列 ,其中 是序列长度, 是每个元素的维度。Attention 的计算过程如下:
首先,将输入 线性映射为查询 (Query)、键 (Key) 和值 (Value) 三个矩阵:
其中,,, 是可学习的参数矩阵。
然后,计算注意力权重并应用于值矩阵:
其中 是缩放因子,用于稳定梯度。
在 PyTorch 中,自注意力机制可以如下实现:
# 实现自注意力机制
class SelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.attention = nn.MultiheadAttention(embed_dim, num_heads)
def forward(self, x):
# x 形状: (seq_len, batch_size, embed_dim)
attn_output, _ = self.attention(x, x, x)
return attn_output
# 使用示例
seq_len, batch_size, embed_dim = 10, 32, 512
x = torch.randn(seq_len, batch_size, embed_dim) # 形状 (10, 32, 512)
attention = SelfAttention(embed_dim, num_heads=8)
output = attention(x)
# 在完整的多头注意力模块实现中,还含有一个线性投影层,用于把中间的输出 O 的通道维度再转换成和输入一致的形状的输出
print(output.shape) # 形状 (10, 32, 512)多头注意力机制则是将注意力机制重复多次并将结果拼接,以捕获不同子空间中的信息。
体系结构与矩阵运算
CPU 体系结构
中央处理器(CPU)是计算机系统的核心组件,负责执行指令和处理数据。现代CPU架构通常包含以下关键部分
核心架构
- 多核设计:现代CPU通常拥有2-64个处理核心,每个核心可以独立执行指令
- 缓存层次结构:
- L1缓存:最快、容量最小(几十KB),通常分为指令缓存和数据缓存
- L2缓存:中等速度和容量(几百KB到几MB)
- L3缓存:较大容量(几MB到几十MB),在多核间共享
- 指令流水线:将指令执行拆分为多个阶段(取指、译码、执行、访存、写回等)
数据处理能力
- SIMD指令集:单指令多数据并行处理能力
- x86架构:SSE、AVX、AVX2、AVX-512等
- ARM架构:NEON、SVE等
- 内存访问:支持乱序执行和预取机制,减少内存访问延迟
CPU与矩阵计算
CPU执行矩阵计算时面临以下挑战:
- 内存带宽限制:大型矩阵数据传输可能成为瓶颈
- 缓存局部性:矩阵计算需要优化内存访问模式以利用缓存
- 并行度有限:与GPU相比,CPU的SIMD单元和核心数量较少
CPU核心优势
顺序执行效率:
- 高单线程性能和复杂的分支预测
- 大缓存设计优化顺序代码执行
- 较低的指令延迟,适合串行任务
条件控制流处理:
- 高效的分支预测器,减少条件判断开销
- 支持复杂的控制逻辑和不规则代码路径
- 适合具有大量条件判断和异常处理的算法
混合工作负载处理:
- 平衡的设计适合同时处理计算、IO和系统任务
- 灵活性强,可处理多样化任务而非单一计算模式
这些特性使CPU在需要复杂决策逻辑的AI推理任务、迭代算法开发和混合工作负载中保持优势。

# 利用NumPy在CPU上高效执行矩阵乘法
import numpy as np
import time
# 创建两个大矩阵
A = np.random.rand(1000, 1000)
B = np.random.rand(1000, 1000)
start = time.time()
C = np.matmul(A, B) # NumPy自动使用优化的BLAS库
end = time.time()
print(f"CPU矩阵乘法耗时: {end - start:.4f}秒")优化的CPU库(如Intel MKL、OpenBLAS)通过充分利用SIMD指令和多核心,仍能高效处理中小规模矩阵计算。
CPU 的执行流程如下图所示 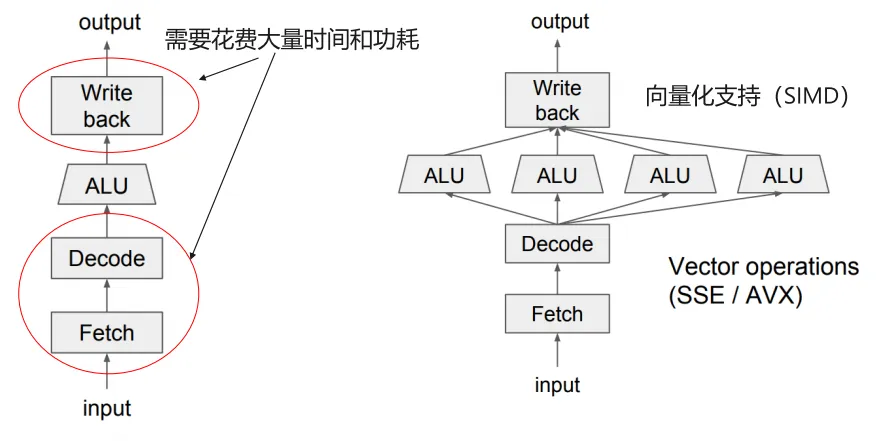 其中访存步骤花费的时间相对是最多的
其中访存步骤花费的时间相对是最多的
案例:如何在 CPU 上高效计算矩阵乘法?
矩阵乘法是张量计算的基础操作,对于两个矩阵 和 ,其乘积 的计算公式为
直接实现与性能瓶颈
最简单的实现方式是使用三重循环
for (int i = 0; i < M; i++)
for (int j = 0; j < N; j++) {
C[i][j] = 0;
for (int k = 0; k < K; k++)
C[i][j] += A[i][k] * B[k][j];
}但是这种实现存在严重的性能问题
- 缓存不友好:对矩阵B的访问是按列进行的,而在内存中数据是按行存储的
- 频繁访存:每次计算都需要从内存加载数据,导致CPU大部分时间在等待数据
- 访存次数:对于每个元素C[i][j]的计算,需要读取K个A的元素和K个B的元素
分块矩阵乘法优化
分块矩阵乘法的核心思想是减少访存操作,提高缓存利用率:
// 分块大小根据缓存大小选择
int BM = 64, BN = 64, BK = 64;
// 初始化C矩阵为0
for (int i = 0; i < M; i++)
for (int j = 0; j < N; j++)
C[i][j] = 0;
// 分块矩阵乘法
for (int i = 0; i < M; i += BM)
for (int j = 0; j < N; j += BN)
for (int k = 0; k < K; k += BK) {
// 计算子矩阵乘法并累加结果
for (int i1 = i; i1 < min(i+BM, M); i1++)
for (int j1 = j; j1 < min(j+BN, N); j1++) {
float temp = 0; // 局部累加器
for (int k1 = k; k1 < min(k+BK, K); k1++)
temp += A[i1][k1] * B[k1][j1];
C[i1][j1] += temp; // 累加到C
}
}性能提升原理:
- 减少访存次数:一次将一个块加载到缓存中,多次复用这些数据
- 改善局部性:小块矩阵能完全放入L1/L2缓存,大幅减少缓存未命中
- 计算访存比优化:每个缓存块加载一次后可执行多次计算操作
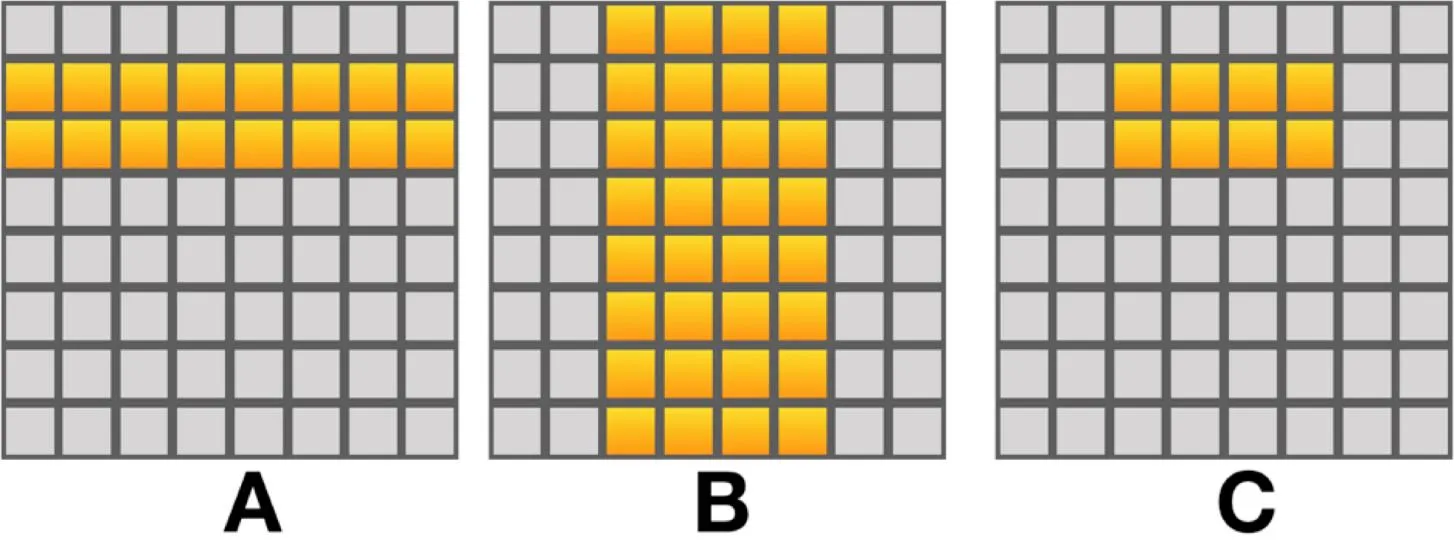
通过优化,分块矩阵乘法可将访存次数从 降低到 ,其中B是块大小。当B较大时,访存开销显著降低,性能可提升5-10倍。
除分块外,进一步优化还包括:
- 循环重排序
- 向量化指令(SIMD)
- 多线程并行化
- 内存对齐和预取技术
GPU 体系结构
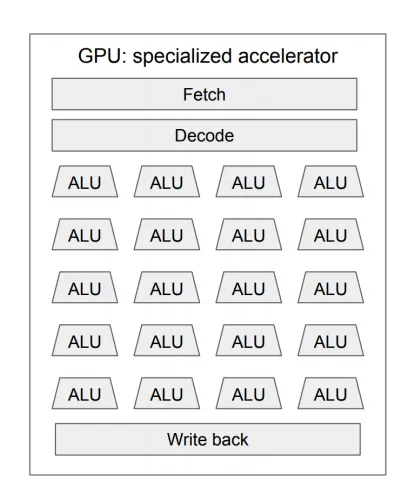
相较于 CPU,GPU 更擅高密度简单暴力计算。GPU由上千个简单的核心 (core) 组成,每个 core 可以同时执行简单的加减乘除逻辑计算等任务。GPU 特点有
- 较高的计算密度
- 计算与访存比率 较高 (相较于 CPU,可以在一起访存后进行更大规模的计算)
- 擅长处理高度并行的计算,如图像处理,矩阵计算
- 不擅长处理控制逻辑复杂的程序
GPU 执行模型
单指令多线程 (SIMT) 是GPU并行处理的核心执行模型
- 原理:同一指令被多个线程同时执行,但每个线程拥有独立的程序计数器和寄存器状态
- 组织结构:
- 线程被组织为线程束(warp/wavefront),典型大小为32/64线程
- 同一线程束 (warp) 内的线程执行相同指令路径时性能最优
- 多个线程束组成线程块(block),多个线程块组成网格(grid)
- 分支处理:
- 当线程束内出现分支时,不同分支路径被序列化执行
- 执行某分支时,不走该路径的线程被暂时屏蔽
- 分支散布(divergence)会显著降低性能
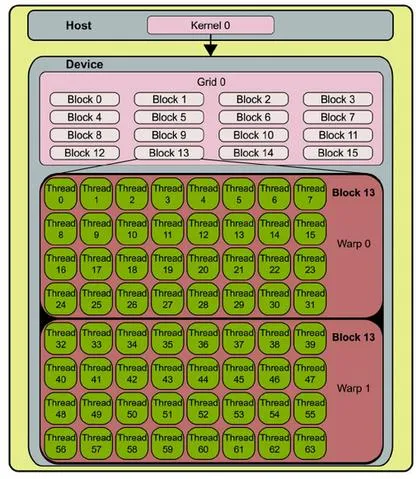
- 线程层次结构:
- 线程束(Warp/Wavefront):GPU执行的基本单位,通常为32线程(NVIDIA)或64线程(AMD)
- 线程块(Block):共享本地内存的线程集合,可包含多个warp
- 网格(Grid):整个GPU计算任务,由多个块组成
这种执行模型使GPU能高效处理规整的并行计算任务,如矩阵运算,但在分支条件复杂时性能下降。
GPU 访存延迟
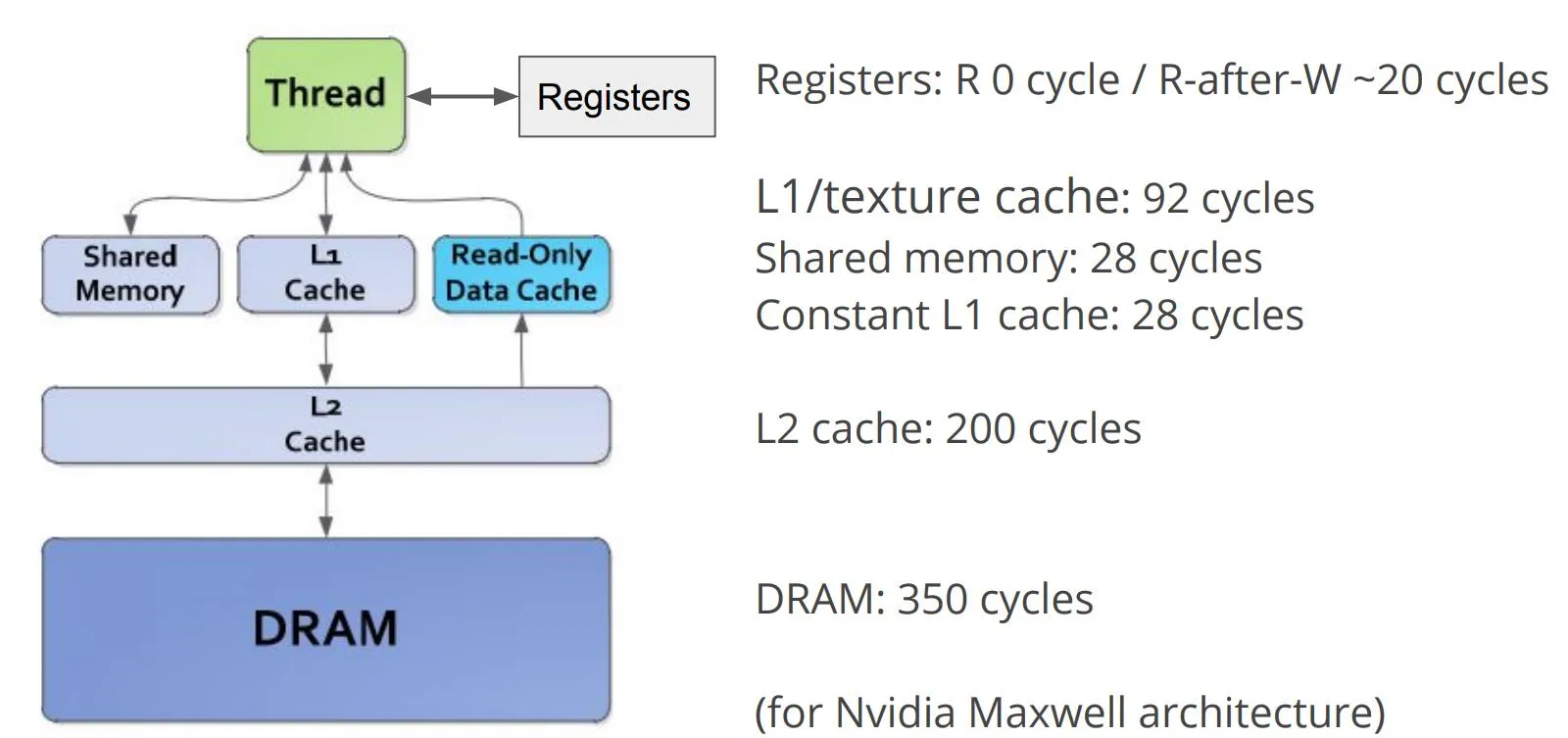
如何在 GPU 上高效计算矩阵乘法?
在GPU上高效实现矩阵乘法涉及多层次的优化策略,主要围绕着如何充分利用GPU的并行架构和内存层次结构。
基本线程映射
最简单的实现是每个线程计算结果矩阵的一个元素:
__global__ void matrixMul(float *A, float *B, float *C, int M, int N, int K) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if(row < M && col < N) {
float sum = 0.0f;
for (int k = 0; k < K; k++) {
sum += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}这种实现存在的主要问题是:
- 全局内存访问频繁,存在高延迟
- 缺乏数据复用,相同数据被重复从全局内存加载
共享内存优化
使用共享内存可以显著减少全局内存访问:
__global__ void matrixMulShared(float *A, float *B, float *C, int M, int N, int K) {
__shared__ float As[TILE_SIZE][TILE_SIZE];
__shared__ float Bs[TILE_SIZE][TILE_SIZE];
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
int row = by * TILE_SIZE + ty;
int col = bx * TILE_SIZE + tx;
float sum = 0.0f;
for (int t = 0; t < (K-1)/TILE_SIZE + 1; t++) {
// 协作加载A和B的tile到共享内存
if(row < M && t*TILE_SIZE+tx < K)
As[ty][tx] = A[row*K + t*TILE_SIZE+tx];
else
As[ty][tx] = 0.0f;
if(t*TILE_SIZE+ty < K && col < N)
Bs[ty][tx] = B[(t*TILE_SIZE+ty)*N + col];
else
Bs[ty][tx] = 0.0f;
__syncthreads();
// 计算当前tile的乘积
for (int k = 0; k < TILE_SIZE; k++) {
sum += As[ty][k] * Bs[k][tx];
}
__syncthreads();
}
if(row < M && col < N)
C[row*N + col] = sum;
}Thread Block Tile 与 Warp Tile
为进一步优化性能,可以采用多级分块策略:
Thread Block Tile:即整个线程块处理的矩阵子区域
- 利用共享内存在线程块内共享数据
- 通常大小为32×32或64×64
Warp Tile:即单个warp处理的矩阵子区域
- 利用warp内线程的协作和寄存器
- 通常大小为16×16或8×8
这种多级分块策略能够:
- 最大化寄存器和共享内存的数据复用
- 减少同步开销
- 提高指令级并行性
- 更好地利用GPU计算资源
从 GEMM 到 BLAS 再到 cuBLAS
在实际应用中,通常使用高度优化的库如cuBLAS:
# 使用cuBLAS的矩阵乘法示例
import torch
# 创建GPU上的张量
A = torch.rand(1024, 1024, device="cuda")
B = torch.rand(1024, 1024, device="cuda")
# PyTorch会自动调用cuBLAS
C = torch.matmul(A, B)cuBLAS内部实现了多种优化技术:
- 自动选择最佳算法和参数
- 利用共享内存和寄存器优化
- 数据预取和重叠计算
- 针对特定GPU架构的调优
编译器与编译优化
传统编译器
编译器是一种计算机程序,用于将高级程序语言编写的源代码转换为计算机能够理解和执行的机器语言代码。整个从编译到装在的程序创建过程可以描述为
编译器主要负责编译部分,由前端、优化器和后端三个部分组成。
- 前端: 负责词法和语法分析,会检查源程序代码是否符合正确的语法和语义,然后将源代码转为抽象语法树
- 优化器: 对前端输出的中间代码进行优化,使代码更加高效
- 后端: 将已经优化的中间代码转化为针对各自平台的机器代码
传统编译器主要有两大类,分别是 GCC 和 LLVM
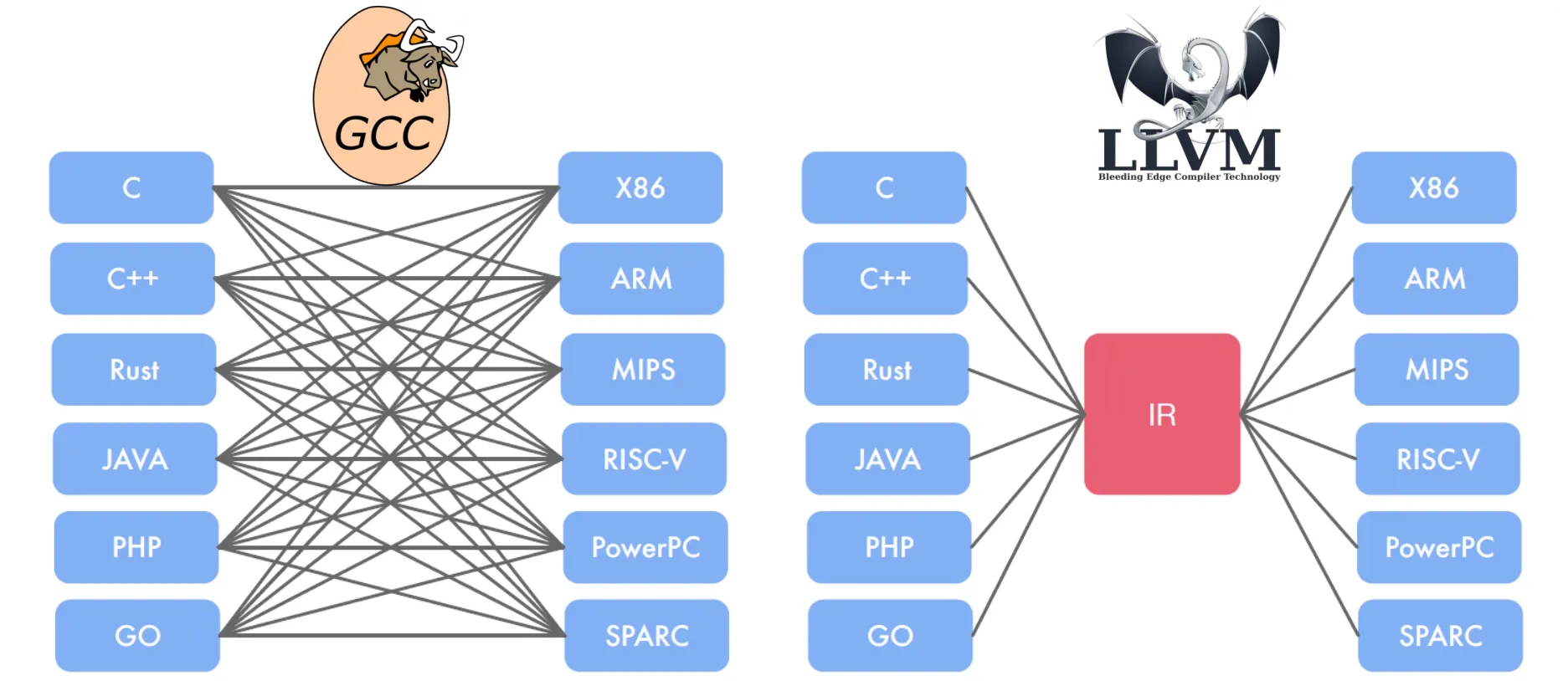
图中左侧描述的是 GCC 的编译模式,特点是 GCC 为不同的高级语言和汇编指令平台的组合分别构建一个编译链接,链接复杂度是 ;而图中右侧描述的 LLVM 编译模式的特点则是通过构建一个中间表示 IR,链接复杂度是 ,实现了高级语言和汇编平台更加方便的链接和扩展。
以 LLVM 为例,LLVM 的编译过程图如下所示
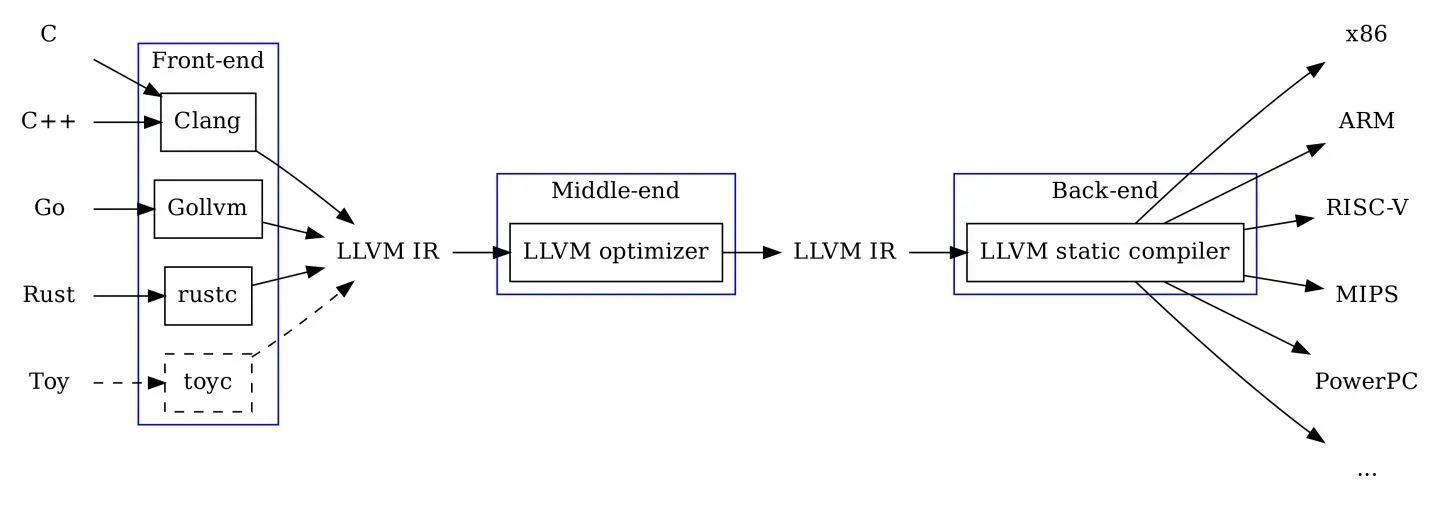
可以看到 C、C++ 的前端是 Clang,经过 LLVM IR 表示后,在中间的优化器部分经过多次优化(一个 pass 表示对源程序的一次完整扫描与优化处理),然后通过后端变成汇编指令
AI 编译器
深度学习的计算主要涉及前向反向传播的计算模式,这与传统计算有着很大的区别。因此,需要新的 AI 编译器优化这个计算模式。
AI 编译器的挑战
- 不同厂商提供的专用加速芯片导致性能的可移植性称为一种刚需
- 新的算子层出不穷,算子库的开发、维护、优化和测试工作量越来越大,需要有更加通用和自动化的能对程序进行优化和代码生成的编译器
AI编译器与传统编译器的区别
计算模型差异
- 传统编译器:针对通用计算,处理控制流复杂的程序,如条件、循环和函数调用
- AI编译器:优化张量计算和数据流图,主要处理大规模并行的矩阵运算,计算模式相对固定
优化目标
- 传统编译器:注重通用性能提升、代码大小和内存使用
- AI编译器:专注于张量计算的吞吐量、内存效率和硬件利用率,如最大化计算密度和优化数据移动
编译流程
- 传统编译器:源代码→IR→机器代码,优化主要在IR级别
- AI编译器:计算图→高级IR→硬件特定IR→代码生成,通常有多级IR转换和更复杂的优化流水线 (IR 层级相较于传统编译器较高)
硬件适配
- 传统编译器:主要针对CPU架构优化
- AI编译器:需支持异构计算环境(GPU/TPU/NPU),每种硬件都有不同的内存层次和计算单元
自动调优
- 传统编译器:主要使用固定的启发式规则和分析算法
- AI编译器:大量使用自动搜索和机器学习方法优化参数(如TVM的AutoTVM和Ansor)
典型代表
- 传统编译器:GCC、LLVM、Clang等
- AI编译器:TVM、XLA、MLIR、Glow、PyTorch 2.0(TorchScript/TorchDynamo)等
领域知识
- 传统编译器:利用程序分析和系统架构知识
- AI编译器:需要深度学习算法、硬件加速器架构和并行计算等多领域知识
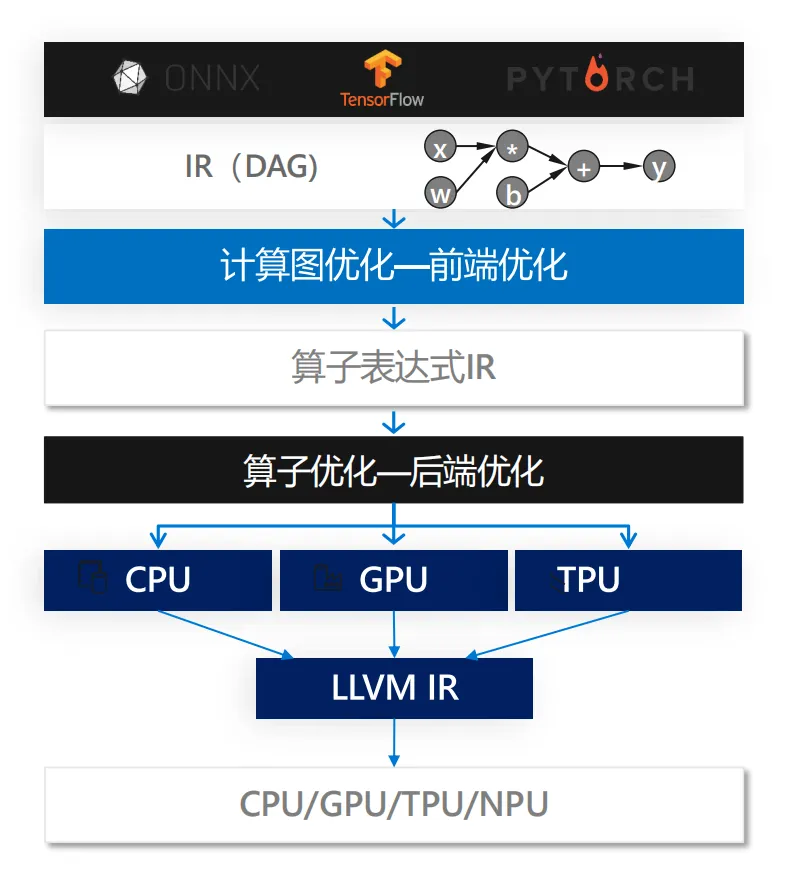
AI编译器实质上是结合了传统编译优化、并行计算、深度学习和硬件架构等多个领域的专门化编译系统,为深度学习工作负载提供高性能、可移植的解决方案。
前端优化
前端优化就是通过计算图的等价变换化简计算图,从而降低计算复杂度或内存开销。 前端优化与硬件无关。
通常的优化方法包括 算术表达式化简、公共子表达式消除、死代码消除、常量折叠、算子融合、布局转换、内存分配等
算术表达式化简
通过代数运算等价变换计算图,如
利用交换律、结合律等规律调整图中的算子执行顺序,或者删除不必要的算子
- e.g. ,其中 是逐元素乘法, 是矩阵乘法
公共子表达式消除
目的是通过找到程序中等价的计算表达式,然后通过复用结果的方式消除其他冗余表达式的计算
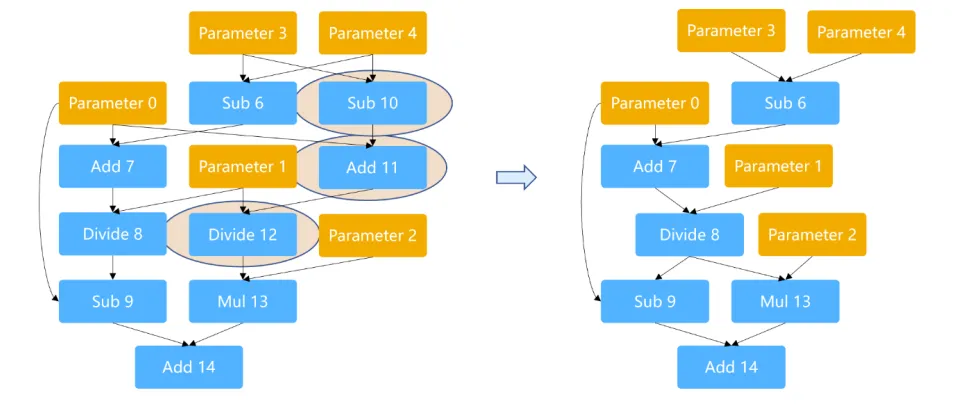 这里的数字只是算子和参数的标号,不是加7减6之类的含义
这里的数字只是算子和参数的标号,不是加7减6之类的含义
死代码消除
移除对程序执行结果没有任何影响的代码,例如一些在训练阶段会使用但在推理时不会执行的计算,可以被消除 (Dropout 操作)
常量折叠
折叠多余的常量计算,例如 a = 320 * 200 * 32 直接变成 a = 2_048_000。这个道理非常的显然,但是常量折叠具有较好的优化作用,因为在模型的修改调试阶段,用户可能会因为调试而编写了很多非折叠的常量,如果不折叠,这在后续的训练优化中会很消耗性能。此外,模型训练阶段时,模型的参数是变化的,而当训练结束后,在推理阶段,模型的参数可以视作一个个常量,此时可以使用常量折叠进行优化。
一个具体的例子是 BatchNorm。BatchNorm操作在训练阶段的计算公式为:
其中:
- 是输入特征
- 是批次均值
- 是批次方差
- 是可学习的缩放和偏移参数
- 是防止除零的小常数
在推理阶段, 和 通常使用训练过程中累积的移动平均值,且这些值与 和 都是固定的。此时可以通过常量折叠优化:
# 原始BatchNorm推理计算
def batch_norm_inference(x, gamma, beta, mean, var, epsilon=1e-5):
return gamma * (x - mean) / torch.sqrt(var + epsilon) + beta
# 常量折叠后的计算
def batch_norm_folded(x, scale, shift):
return x * scale + shift
# 参数折叠过程
scale = gamma / torch.sqrt(var + epsilon)
shift = beta - scale * mean
# 将原始BatchNorm替换为简单的缩放和平移操作这种优化将BatchNorm从包含除法的复杂操作简化为单一的缩放和平移(乘加操作),减少了计算量并提高了推理效率。在实际部署中,常量折叠可以将BatchNorm层与相邻的卷积层进一步融合,完全消除BatchNorm的额外计算开销。

在高效的推理引擎实现中,这种折叠通常是自动完成的,显著提升了模型的执行速度,尤其在边缘设备上更为明显。
算子融合
将向量化的多个算子操作合并成一个算子操作。这种优化的想法是,CPU 内核的启动是有时间开销的,这样做可以减少内存的读取,提高计算密度。例如,可以将 c = mul(a, b) 和 e = add(c, d) 合并成 e = mla(a, b, d),从而减少一次 c 写入的访存和一次 c 读取的访存。
另外一个具体的例子是实现矩阵乘法的自动融合,例如同时有两个张量 x 和 y 都需要有与张量 z 相乘计算后的结果,可以把 x 和 y 进行拼接再与 z 相乘,从而减少访存的操作和内核启动时间
布局转换
Tensor 是一个多维阵列,但是在存储中的排列存储方式确是“向量化”的形式,因此如何布局排布对计算 cache 的读取是具有影响的。假设有一个形状为 (2, 3) (行编号, 列编号) 的矩阵 ,通常排布有
- 行优先:排布成 存储
- 列优先:排布成 存储
在深度学习中,图像张量的形状有两种常用的排布方式
(B, C, H, W)型:各个张量维度依次表示 (批次大小, 通道数, 高度, 宽度),这是输入卷积层的特征图的形状。同一个通道的数据值连续排布,更适合需要对每个通道单独运算的操作,如 MaxPooling,适合 GPU、大带宽的计算模式(B, H, W, C)型:各个张量维度依次表示 (批次大小, 高度, 宽度, 通道数)。不同通道中同一位置元素顺序存储,更适合需要跨通道计算的操作如 卷积(注意卷积可以用 NHWC 形式下存储的张量和线性层实现,这样比 NCHW 加卷积层的模式更高效)。这种计算模式更适合多核 CPU 执行,计算控制灵活且复杂
内存分配
在深度学习训练和推理过程中,内存分配与管理是影响性能和效率的关键因素。内存复用技术可以显著降低内存开销,尤其是在处理大型模型时。
# 使用torch.cuda.memory_stats()查看当前GPU内存使用情况
import torch
# 在不优化的情况下执行操作
def unoptimized():
x = torch.randn(10000, 10000, device='cuda')
y = torch.randn(10000, 10000, device='cuda')
z = x @ y # 矩阵乘法
return z
# 使用内存前后对比
torch.cuda.empty_cache()
before = torch.cuda.memory_allocated()
result = unoptimized()
after = torch.cuda.memory_allocated()
print(f"内存增长: {(after - before) / 1024**2:.2f} MB")这里没有进行优化,导致内存增长为 390.12 MB
内存复用的基本原理
在计算图执行过程中,不同操作产生的中间结果通常只在特定阶段有用。一旦这些中间结果被消费后,其占用的内存空间可以被释放并重新用于存储其他中间结果。
原地操作 (Inplace Operation): 如果一块内存不再需要,且下一个操作是 element-wise 的,就可以做原地操作覆盖内存,而无需新内存。例如,PyTorch 的激活函数可以设置采用
torch.nn.ReLU(inplace=True)内存共享 (Memory Sharing): 两个数据共享同一块内存空间,其中有一个数据参与计算后不再需要,后一个数据可以覆盖前一个数据,只要这两个数据的生命周期无重叠即可(不过这对反向传播是有影响的)。
PyTorch中提供了多种内存优化机制
- 梯度检查点(Checkpoint)
对于大型模型,可以使用梯度检查点技术在反向传播时重新计算中间激活值,而不是存储所有激活值
import torch.utils.checkpoint as checkpoint
class LargeModel(torch.nn.Module):
def __init__(self):
super().__init__()
# 定义一个包含多个层的大型模型
self.layers = torch.nn.ModuleList([
torch.nn.Linear(1024, 1024) for _ in range(10)
])
def forward(self, x):
for layer in self.layers:
# 使用checkpoint包装层的前向传播
x = checkpoint.checkpoint(layer, x)
return x
# 这种方式会在反向传播时重新计算中间结果,降低内存使用但增加计算量- 释放未使用的Tensor
# 明确释放不再需要的张量
x = torch.randn(10000, 10000, device='cuda')
y = torch.randn(10000, 10000, device='cuda')
z = x @ y
del x, y # 显式释放不再需要的大张量
torch.cuda.empty_cache() # 释放缓存的未使用内存- 使用inplace操作
当可能时,使用原地操作可以避免额外的内存分配:
# 非原地操作
x = torch.ones(1000, 1000)
x = x + 1 # 创建新张量
# 原地操作
x = torch.ones(1000, 1000)
x.add_(1) # 直接修改x,不创建新张量- 自动垃圾回收优化
PyTorch 2.0引入了更智能的内存管理机制,包括通过编译优化内存使用:
# 使用torch.compile优化内存使用
@torch.compile
def optimized_function(x, y):
intermediate1 = x * 2
intermediate2 = y * 3
result = intermediate1 @ intermediate2
return result
# 编译后的函数会优化内存使用模式- 流水线并行和模型分片
对于特别大的模型,可以使用PyTorch的分布式训练工具实现模型并行化:
# 使用torch.distributed进行模型并行示例
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
# 初始化分布式环境
dist.init_process_group(backend="nccl")
# 将模型的不同部分分配到不同设备
model_part1 = Model1().to(f'cuda:{dist.get_rank() % 2}')
model_part2 = Model2().to(f'cuda:{(dist.get_rank()+1) % 2}')
# 每个设备只存储部分模型参数通过这些技术,深度学习框架可以在有限内存条件下处理更大的模型和数据集,提高训练和推理效率。
后端优化
后端优化主要关注算子节点内部的具体实现,目标是让算子的性能达到最优。常用的优化方式有循环展开,循环分块,循环融合等。
循环展开
循环展开是一种通过减少循环控制开销和提高指令级并行性来优化循环执行的技术。
基本原理:将循环体内的代码复制多次,减少循环迭代次数,同时增加每次迭代中的计算量。
// 原始循环
for (int i = 0; i < N; i++) {
sum += array[i];
}
// 循环展开(展开因子为4)
for (int i = 0; i < N; i += 4) {
sum += array[i];
sum += array[i+1];
sum += array[i+2];
sum += array[i+3];
}优化效果:
- 减少循环控制开销(分支预测、条件检查)
- 提高指令级并行性
- 增加寄存器利用率
- 减少内存操作的延迟影响
在深度学习计算如卷积或矩阵乘法中,循环展开通常与向量化指令(如SIMD)结合使用,显著提高计算密度。
循环分块
循环分块(Loop Tiling)通过改变数据访问模式来提高缓存效率,对于矩阵和张量运算尤为重要。
基本原理:将大循环划分为小块,使每块数据能够完全放入CPU缓存中。
// 原始矩阵乘法
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++) {
float sum = 0;
for (int k = 0; k < N; k++)
sum += A[i][k] * B[k][j];
C[i][j] = sum;
}
// 分块优化后的矩阵乘法
for (int i0 = 0; i0 < N; i0 += B)
for (int j0 = 0; j0 < N; j0 += B)
for (int k0 = 0; k0 < N; k0 += B)
for (int i = i0; i < min(i0+B, N); i++)
for (int j = j0; j < min(j0+B, N); j++) {
float sum = (k0 == 0) ? 0 : C[i][j];
for (int k = k0; k < min(k0+B, N); k++)
sum += A[i][k] * B[k][j];
C[i][j] = sum;
}优化效果:
- 提高缓存命中率
- 减少内存带宽需求
- 增加数据局部性
- 降低TLB缺失率
分块策略在深度学习编译器中广泛应用,特别是在GPU计算中,将数据分块到不同层次的内存(共享内存、寄存器)可以显著提升性能。
循环融合
循环融合是将多个循环合并成一个循环的优化技术,可减少循环开销并提高数据局部性。
基本原理:当多个循环具有相同的迭代范围且无数据依赖时,可以将它们融合为一个循环。
// 融合前
for (int i = 0; i < N; i++)
A[i] = B[i] * scalar1;
for (int i = 0; i < N; i++)
C[i] = A[i] + D[i];
// 融合后
for (int i = 0; i < N; i++) {
A[i] = B[i] * scalar1;
C[i] = A[i] + D[i];
}优化效果:
- 减少循环控制开销
- 提高指令缓存效率
- 减少数据在不同循环间的移动
- 提高数据局部性和缓存命中率
在深度学习计算中,循环融合通常用于合并element-wise操作,如将激活函数计算与前一层的线性操作融合,减少中间结果的内存访问。许多现代AI编译器(如TVM、XLA)会自动执行这类融合优化。
循环融合与算子融合密切相关,但更专注于底层循环实现而非图层面的优化。在实际应用中,两者通常结合使用,先在计算图层面融合算子,再在代码生成阶段优化具体循环实现。
循环拆分
循环拆分
循环拆分(Loop Splitting)是将单个循环拆分为多个连续执行的循环的优化技术,有助于提高执行效率和并行性。主要是针对含有条件分支的语句进行的优化方法。
基本原理:将循环按照某种条件分成多个部分,每部分处理原循环的不同情况或执行不同的优化策略。
// 原始循环(包含条件判断)
for (int i = 0; i < N; i++) {
if (i < M)
A[i] = B[i] * 2;
else
A[i] = C[i] + D[i];
}
// 拆分后
for (int i = 0; i < M; i++) {
A[i] = B[i] * 2; // 第一部分
}
for (int i = M; i < N; i++) {
A[i] = C[i] + D[i]; // 第二部分
}优化效果:
- 消除循环内的条件分支,减少分支预测失误
- 简化循环体,使编译器能应用更多优化
- 为不同循环部分应用不同的优化策略
- 提高向量化和并行化机会
在深度学习计算中,循环拆分常用于处理边界条件、对齐问题或特殊情况,例如将卷积操作中填充(padding)区域和非填充区域的计算分开处理,使主计算循环能够被更好地优化。这种技术也可以与循环展开、向量化等其他优化相结合,进一步提升性能。
参考资料: