

分布式算法与分布式训练
并行计算加速定律
并行计算加速定律有两个
1. Amdahl 定律
假设程序执行总运行时间为不可并行部分与可并行部分之和, 即 。设共有 个并行执行单元,并行加速后的执行时间为,,这里取大于号是因为并行执行单元之间通信存在时间开销。定义加速比为
令 为 中可并行部分的占比,则
此时加速比为 ,这意味着即使 无限大, 也不会超过 。
Amdahl 定律说明了并行计算的加速存在上限。
2. Gustafson定律
Amdahl 假设问题的规模是固定的,具有局限性。实际上随着并行度的增加,可解的问题的规模也在增加。假设在拥有 个并行执行单元的机器上,总的执行时间为 , 则在单处理器上,相同规模问题的执行时间为 , 加速比为
这里假设的是问题的规模随着并行的增加也在增加。此时得到的加速比是关于 的线性函数,随着 的增加而增加。
Gustafson 定律则是揭示了线性加速比的可能性,在问题的规模足够大的时候。
分布式计算的意义
深度学习训练耗时与训练数据规模、单步计算量、计算速率有关
而其中计算速率则受单设备计算速率、设备数和并行效率影响
为例降低深度学习的训练耗时,其中最容易改变的因子是设备数和并行效率,因为其他因素要么与模型本身相关,不便于改变,要么受到 Moore 定律的限制,难以大幅提升。从此也就得出并行计算的意义所在。
分布式算法
分布式算法是指在多个处理器上运行且没有非常严格的中心控制的算法。
分布式系统是指有一系列独立计算设备组成的一个在用户眼里看起来就像是一个设备的协同系统。
并行化的方案可以分为两大类
算子内并行: 在单个算子内部进行并行化计算,将一个算子的计算任务分解到多个处理器单元上同时执行。例如一个卷积可以使用不同的 GPU 核心共同完成计算
算子间并行
- 模型并行: 将一个模型的各个部分拆分到不同的设备上,每个处理器并行计算自己需要处理的部分
- 数据并行: 将相同的模型复制到多个设备上,每个设备并行处理不同的数据批次
算子内并行的部分在计算机体系结构部分已经阐述。下面主要讲述算子间并行
模型并行:将模型计算图划分至不同的设备上执行

Naïve 模型并行
# 模型并行的AlexNet实现
class ModelParallelAlexNet(nn.Module):
def __init__(self):
super(ModelParallelAlexNet, self).__init__()
# 第一部分放在cuda:0上
self.features_0 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
).to('cuda:0')
# 第二部分放在cuda:1上
self.features_1 = nn.Sequential(
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
).to('cuda:1')
# 分类器部分也放在cuda:1上
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 1000),
).to('cuda:1')
def forward(self, x):
# 假设输入x在cuda:0上
x = self.features_0(x)
# 将x从cuda:0传输到cuda:1
x = x.to('cuda:1')
# 继续在cuda:1上进行计算
x = self.features_1(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
# 训练示例
def train_model_parallel(model, data_loader, criterion, optimizer):
model.train()
for inputs, labels in data_loader:
inputs = inputs.to('cuda:0') # 将输入数据放在第一个GPU上
labels = labels.to('cuda:1') # 将标签放在输出所在的GPU上
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()事实上,该模型并行的实现方式并不一定能让训练时间减少为一半,这种方法的时间开销甚至会比不并行训练的时间更长,因为在任何时刻总有一块设备处于空闲状态,但是在 GPU 之间传播张量的通信却有额外耗时开销。

当数据 batch 在 cuda:0 时,cuda:1 中尚没有数据 batch 可供运行;而当 cuda:0 完成计算,数据 batch 传到 cuda:1 时,cuda:0 需等待这个数据 batch 运行结束后,才能有新的数据 batch 传入供 cuda:0 处理。显然这种实现没有充分利用两个 GPU 的并行能力。
流水线 (Pipeline) 的实现方式
GPipe 算法
若想高效利用多块 GPU 间的并行能力,流水线无疑是一个解决方案。切分 batch,当前一个 split 经 cuda:0 处理好后进入 cuda:1 时,下一个 split 就可以进入 cuda:0 运行。这种实现方法叫 Gpipe 算法。其特点是所有 splits 前向传播结束后才能进行反向传播,因此在前向传播和后向传播之间存在大量 bubbles 。
class GPipeAlexNet(nn.Module):
def __init__(self, split_size):
super().__init__()
self.split_size = split_size
self.features_0 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
).to('cuda:0')
self.features_1 = nn.Sequential(
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
).to('cuda:1')
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 1000),
).to('cuda:1')
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_prev = self.features_0(next(splits)).to('cuda:1') # 初始化计算
results = []
for s_next in splits:
s_prev = self.features_1(s_prev)
results.append(self.classifier(s_prev.view(s_prev.size(0), -1)))
s_prev = self.features_0(s_next).to('cuda:1')
s_prev = self.features_1(s_prev) # 尾部处理
results.append(self.classifier(s_prev.view(s_prev.size(0), -1)))
# 将所有分割结果连接起来,保持与单卡输出格式一致
return torch.cat(results, dim=0)Gpipe 算法仅首尾循环中存在 bubbles,大多数迭代过程中两块 GPU 是可以并行执行的。切分的越细这种空洞自然也会越小,但是 splits 不是越多越好,因为传输复制也是耗时的。
- Gpipe 测试代码: Gpipe.py
PipeDream 算法
PipeDream 算法的特点是人为制造反向传播的 bubbles,然后在反向传播的 bubbles 中穿插计算前向计算,从而改进 GPipe 算法前向和反向传播间有大量 Bubles 的不足。
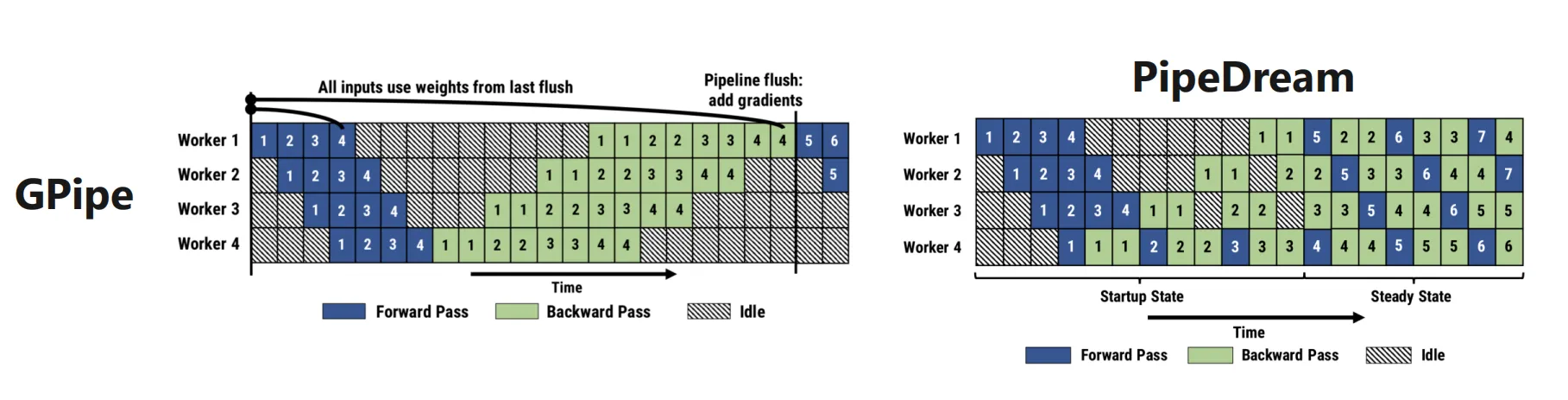
PipeDream 与 GPipe不同,不需要等待所有前向传播完成才开始反向传播,而是采用更灵活的 1F1B (one-forward-one-backward) 调度策略,即在前向处理了一个微批次后就可以开始处理该微批次的反向传播。这种策略能更好地填满 bubbles,提升设备利用率。
数据并行: 将数据划分至不同的设备上执行
数据并行的实现方式是将数据划分至不同的设备上执行相同的计算图。每个设备上都有一份模型参数,前向传播时每个设备上都执行相同的计算图,最后将每个设备上的梯度进行聚合。然后利用聚合后的梯度更新模型。

数据并行比模型并行更为高效且更加常用。
集合通信 (Collective Communication)
集合通信是分布式深度学习中多设备间协同工作的基础,指的是在多个计算节点之间同时进行的数据交换操作。不同于点对点通信(只涉及两个节点),集合通信同时涉及多个节点共同参与的通信模式。
集合通信的主要特点:
- 多个节点同时参与通信过程
- 通常有特定的通信模式和语义
- 为分布式训练提供高效的数据传输方式
- 支持跨设备、跨机器的数据同步
在分布式深度学习中,集合通信主要用于
- 梯度聚合和参数同步
- 模型分片和结果合并
- 同步不同工作节点的状态
- 实现高效的数据并行和模型并行
这里介绍一些集合通信的 primitives(原语)
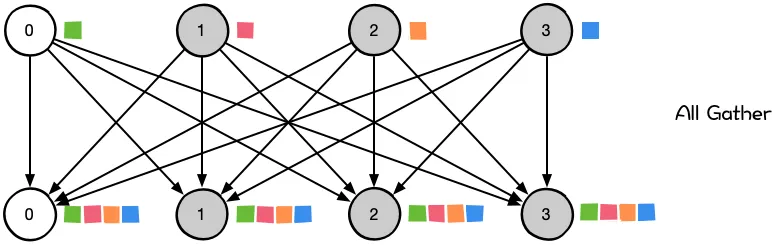
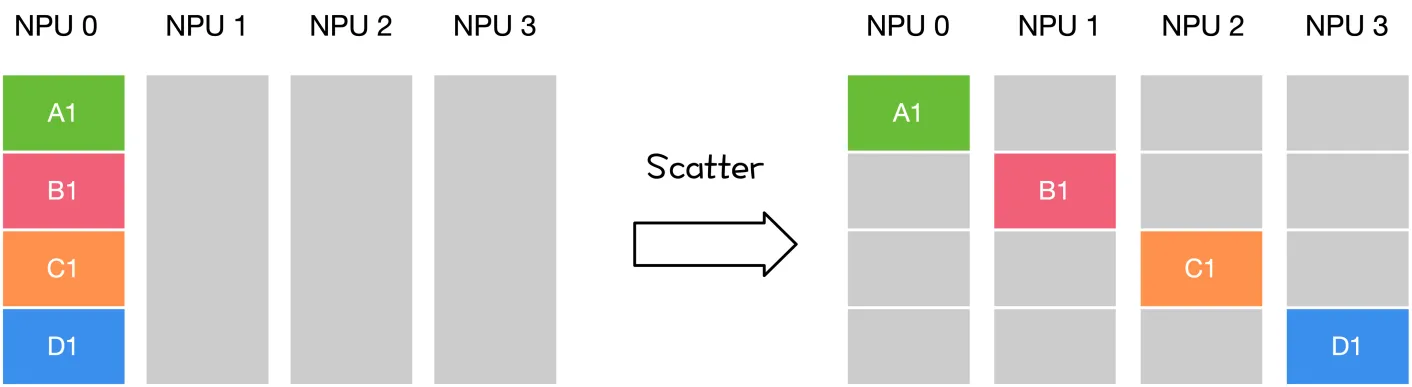
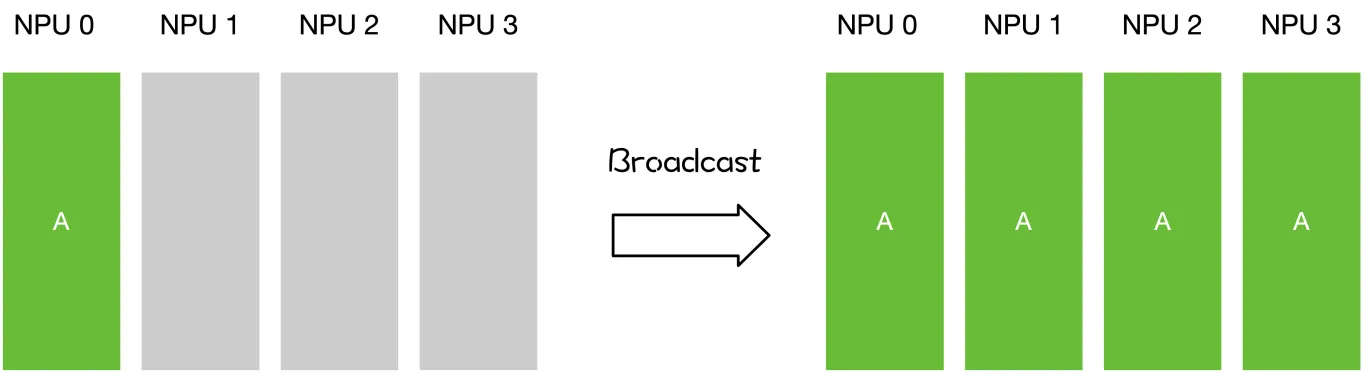
- 一对多:Scatter, Broadcast
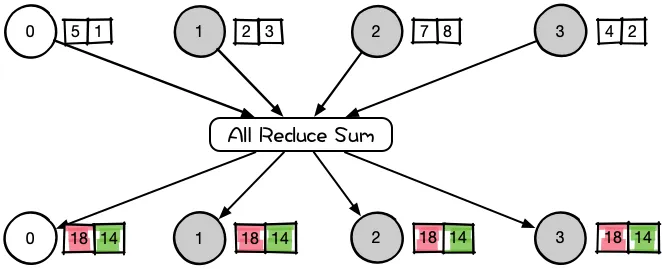
- 多对一:Gather,Reduce
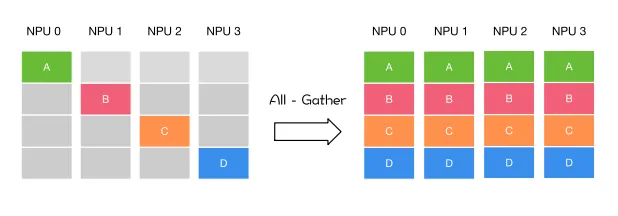
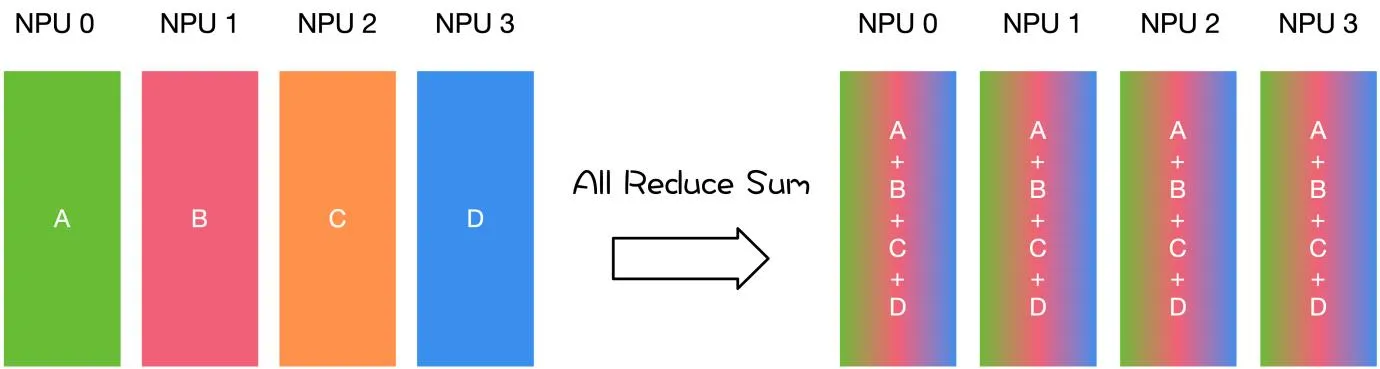
- 多对多:All-Reduce,All-Gather
| scatter | broadcast | gather | reduce | all-gather | all-reduce |
|---|---|---|---|---|---|
| 主节点把数据分发给各个节点 | 某个节点把自身数据传递给全部节点 | 不同设备上的数据规约运算 | 将所有节点的数据收集到主节点上 | gather + broadcast | reduce + broadcast |
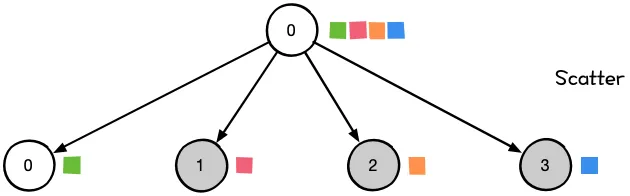 | 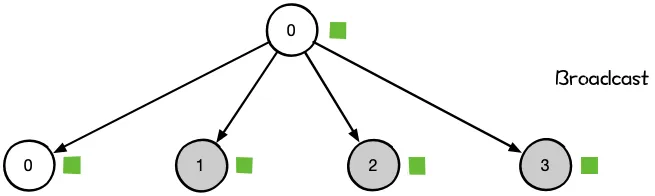 | 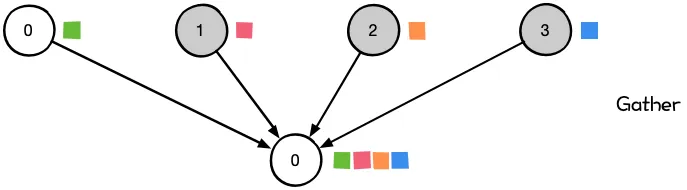 |  |  |  |
 |  | 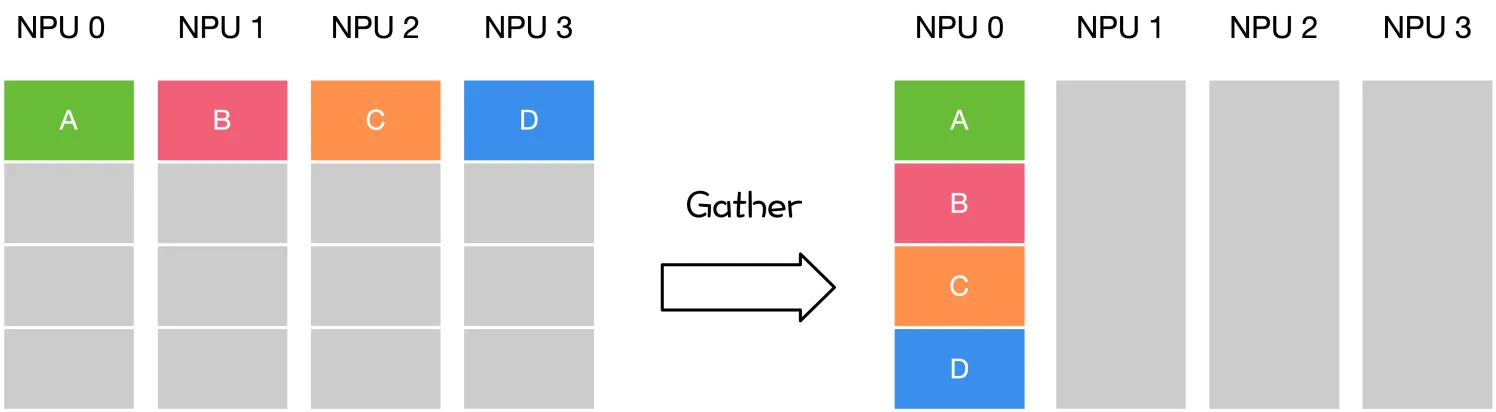 | 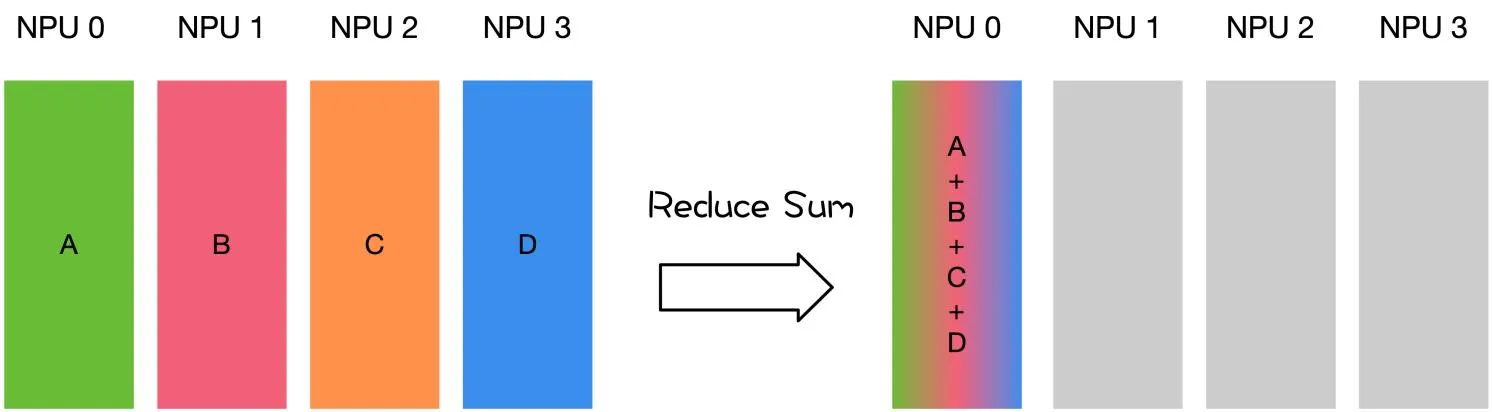 |  |  |
gather 与 reduce 的区别
同样是将数据从不同设备上收集到同一个设备上,但是 gather 是收集数据,并不进行处理,但是 reduce 则会将数据进行求和等操作。类似地,broadcast 是将同一份数据分发到不同的设备上,而 scatter 则是将不同的数据分发到不同的设备上。All-reduce 相当于 reduce + broadcast,All-gather 相当于 gather + broadcast。
PyTorch 的六种通信原语接口
import torch.distributed as dist
# 1. scatter
dist.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False)
# 2. gather
dist.gather(tensor, gather_list=None, dst=0, group=None, async_op=False)
# 3. broadcast
dist.broadcast(tensor, src=0, group=None, async_op=False)
# 4. all_gather
dist.all_gather(tensor_list, tensor, group=None, async_op=False)
# 5. all_reduce
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=None, async_op=False)
# 6. reduce
dist.reduce(tensor, dst=0, op=dist.ReduceOp.SUM, group=None, async_op=False)
# 7.barrier
dist.barrier(group=None, timeout=timedelta.max)点对点通信 (Point-to-Point Communication)
点对点通信是分布式系统中两个计算节点之间直接交换数据的通信方式。在分布式深度学习中,它用于在不同设备(如 GPU 或 机器)之间传输模型参数、梯度或中间结果。
基本特点:
- 只涉及两个节点:一个发送方和一个接收方
- 通信范围局限,不像集合通信那样涉及多个节点
实现方式:
- 同步 send/recv,即阻塞式通信,发送端需要等待接收端开始接收数据之后才能结束,发送命令的返回意味着接收端已执行了一定程度的接收工作。双方进程到达一个确定的同步点之后,通信才可以结束。
def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
dist.send(tensor=tensor, dst=1)
else:
dist.recv(tensor=tensor, src=0)
print(f"Rank {rank} has data {tensor[0]}")
- 异步 send/recv,即非阻塞式通信,可以将通信和计算重叠进行。发送指令不要求操作立即执行,从发送数据区取走数据之前命令即可返回,然后在适当时机完成实际发送通信,在
wait()时可并发进行数据传输和计算。
def run(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print(f"Rank {rank} has data {tensor[0]} after wait")参数服务器
参数服务器是一种分布式训练的架构,主要用于解决数据并行训练中的参数更新问题。参数服务器的基本思想是将模型参数存储在一个或多个服务器上,工作节点(worker)负责计算梯度并将其发送到参数服务器进行更新。参数服务器可以是集中式的,也可以是分布式的。参数服务器可以是 CPU,也可以是 GPU0。
All-Reduce 实现算法
1. Reduce + Broadcast
- Parameter Sever 作为中心节点,先全局接收所有节点的梯度,然后进行聚合计算,最后将结果 Broadcast 到所有节点。
- 总体耗时是 (这里的前者是通信耗时,后者是中心节点的计算耗时)
- 其中 是两个通信节点之间建立连接的固定延迟, 是每个节点的数据块大小, 是带宽, 是节点数, 是每个节点的每字节数据的计算耗时。
- 该算法的缺点是中心节点的带宽成为了性能瓶颈,且通信延迟较大。

2. 树形递归算法 (Reduce + Broadcast)
- 该算法的基本思想是将所有节点组织成一棵树,树的根节点是参数服务器,叶子节点是工作节点。每个节点只与其父节点和子节点进行通信。每个节点先将自己的梯度发送到父节点,然后父节点将所有子节点的梯度进行聚合计算,最后将结果 Broadcast 到所有子节点。
- 图中实线是真实的通信,虚线只是示意,并无通信发生
- 规避了单节点的带宽瓶颈,但是在递归过程中仍然有一半的节点没有进行 send 操作,只是在等待接收数据 (发送带宽没有被利用上)
- 整体耗时是

3. Scatter-Reduce + All-Gather
- 该算法结合了 Scatter-Reduce 和 All-Gather 两个操作来实现 All-Reduce
- Scatter-Reduce 阶段:首先将每个节点的数据分成 N 块(N为节点数),然后第 i 个节点负责收集所有节点的第 i 个数据块并进行聚合计算
- All-Gather 阶段:每个节点将自己计算得到的聚合结果广播给其他所有节点
- 这种方法通过分散计算负载,避免了单节点瓶颈,同时每个节点只需负责部分数据的聚合
- 总体通信时间为 ,比直接 Reduce + Broadcast 方式更有效率
- 该方法被广泛用于分布式深度学习框架中,是实现高效 All-Reduce 的基础

4. Ring All-Reduce (Scatter-Reduce + All-Gather 的变种)
采用环形拓扑结构实现通信链路。第 个 worker(节点)会把第 个数据发送给下一个 worker,即第 个节点,同时从前一个 worker 接收到 第 个数据。然后第 个 worker 会把收到的的第 个数据和自己的第 数据整合,再将整合的数据发送给下一个 worker。
假设总共有 个节点,那么经过 次迭代之后就完成了 Scatter-Reduce 操作。(不是 次,因为最后一个数据块来自第 个 worker 计算好了的)。此时,在第 个 worker 的第 个数据块上出现 reduce 好了的数据块。
此后,只需要一次 All-Gather 即可把所有的计算块收集并分发出来,从而实现 All-Reduce 操作。这里的 All-Gather 操作也是类似前述的环形操作的,对于第 块数据,会从第 个 worker 开始,逐步往下一个设备传播 (),传播 次即实现了 All-Gather。
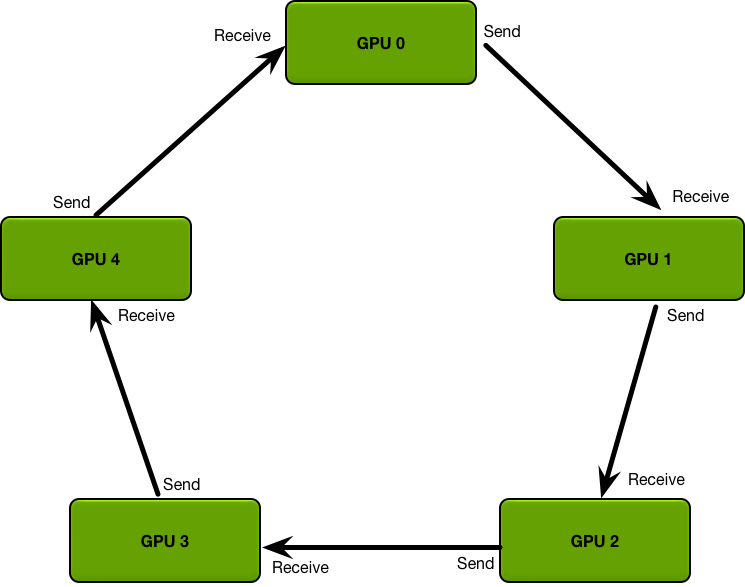
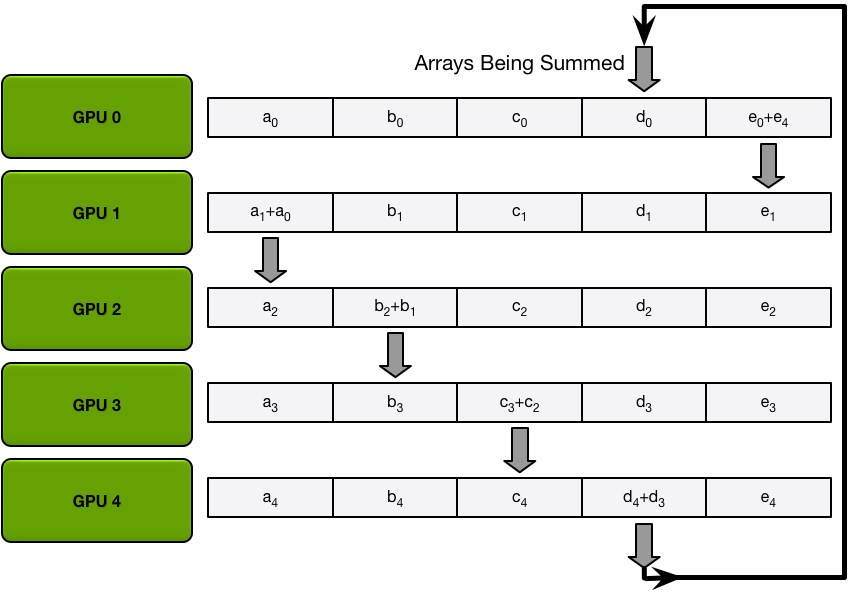
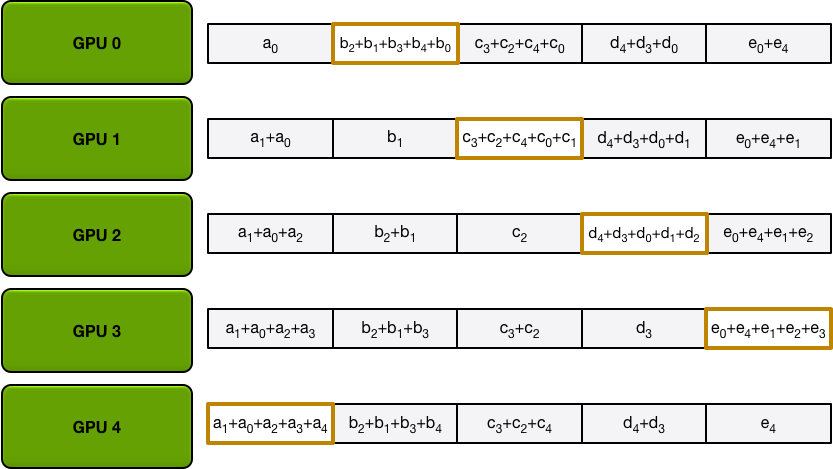
- 性能分析: 在整个过程中,网络中每个 worker 上 send / receive 的总通信数据量均为
其中, 为 worker 数量, 为每个 worker 上所有 chunk 的总数据量 (chunk数量 = worker数量)。这里的 代表单个 worker 上需要传输的一个数据块的大小。
- 单个 worker 通信数据量近似独立于 worker 的数量 ,是 。
- 每个 worker 的网络收发负载是均衡的,网络双向带宽得到充分利用
实现代码
def ring_allreduce(send, recv):
""" Implementation of a true Ring-AllReduce with explicit accumulator. """
rank = dist.get_rank()
size = dist.get_world_size()
chunk_size = send.size(0) // size # Divide data into chunks
send_buff = torch.zeros(chunk_size, *send.size()[1:]) # Buffer for sending
recv_buff = torch.zeros(chunk_size, *send.size()[1:]) # Buffer for receiving
# Split the data into chunks
chunks = [send[i * chunk_size:(i + 1) * chunk_size] for i in range(size)]
accum = torch.zeros_like(send) # Explicit accumulator
left = (rank - 1 + size) % size # Left neighbor
right = (rank + 1) % size # Right neighbor
# Reduce-Scatter phase
for i in range(size - 1):
send_chunk = chunks[(rank - i + size) % size] # Select the chunk to send
send_buff.copy_(send_chunk) # Copy the chunk to the send buffer
send_req = dist.isend(send_buff, right) # Send to the right neighbor
dist.recv(recv_buff, left) # Receive from the left neighbor
send_req.wait() # Wait for the send to complete
# Accumulate the received chunk into `accum`
recv_chunk_idx = (rank - i - 1 + size) % size
accum[i * chunk_size:(i + 1) * chunk_size] += recv_buff
# All-Gather phase
for i in range(size - 1):
send_chunk_idx = (rank - i - 1 + size) % size
send_buff.copy_(chunks[send_chunk_idx]) # Copy the chunk to the send buffer
send_req = dist.isend(send_buff, right) # Send to the right neighbor
dist.recv(recv_buff, left) # Receive from the left neighbor
send_req.wait() # Wait for the send to complete
# Store the received chunk in the correct position
recv_chunk_idx = (rank - i - 2 + size) % size
chunks[recv_chunk_idx].copy_(recv_buff)
# Combine all chunks into the final result
recv.copy_(torch.cat(chunks, dim=0))PyTorch 中的 rank 间通信使用示例
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
"""Blocking point-to-point communication."""
def run_B(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor[0])
"""Non-blocking point-to-point communication."""
def run_N(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
# Send the tensor to process 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
# Receive tensor from process 0
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print('Rank ', rank, ' has data ', tensor[0])
""" All-Reduce example."""
def run_A(rank, size):
""" Simple collective communication. """
group = dist.new_group([0, 1])
tensor = torch.ones(1) * 5
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor[0])
def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run_N))
p.start()
processes.append(p)
for p in processes:
p.join()数据并行的代码实践
目前已有许多成熟的分布式通信后端,实现了各类通信原语的算法,如 MPI、NCCL 和 Gloo。这些后端在分布式训练中可以进行选择。
torch.distributed 实现单机多卡分布式训练
import torch.distributed as dist
from math import ceil
from random import Random
from torch.multiprocessing import Process
from torch.autograd import Variable
from torchvision import datasets, transforms
class DatasetSubset:
"""数据集的子集包装器"""
def __init__(self, parent_dataset, indices):
self.parent_dataset = parent_dataset
self.indices = indices
def __len__(self):
return len(self.indices)
def __getitem__(self, idx):
actual_idx = self.indices[idx]
return self.parent_dataset[actual_idx]
class DataPartitioner(object):
""" Partitions a dataset into different chuncks. """
def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=42):
self.data = data
self.partitions = []
rng = Random()
rng.seed(seed)
data_len = len(data)
indexes = [x for x in range(0, data_len)]
rng.shuffle(indexes)
for frac in sizes:
part_len = int(frac * data_len)
self.partitions.append(indexes[0:part_len])
indexes = indexes[part_len:]
def use(self, partition):
return DatasetSubset(self.data, self.partitions[partition])
def partition_dataset(): # 数据集分割需要自行实现,dist中并未实现
""" Partitioning MNIST """
dataset = datasets.MNIST(
'./data',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
]))
size = dist.get_world_size()
bsz = int(128 / float(size)) # 128 / float(size)
partition_sizes = [1.0 / size for _ in range(size)]
partition = DataPartitioner(dataset, partition_sizes)
partition = partition.use(dist.get_rank())
train_set = torch.utils.data.DataLoader(
partition, batch_size=bsz, shuffle=True)
return train_set, bsz
def average_gradients(model): # 同理,avg-SGD 也是 dist 中没有的
""" Gradient averaging. """
world_size = float(dist.get_world_size())
for param in model.parameters():
if param.grad is not None:
# 执行全局梯度求和
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
# 计算平均梯度
param.grad.data.div_(world_size)
def run(rank, size):
""" Distributed Synchronous SGD Example """
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
model = model.cuda(rank) # single machine, multiple GPU
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(3):
epoch_loss = 0.0
for data, target in train_set:
data, target = Variable(data.cuda(rank)), Variable(target.cuda(rank))
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item() #loss.data[0]
loss.backward()
average_gradients(model) # all reduce operation
optimizer.step()
print('Rank ',
dist.get_rank(), ', epoch ', epoch, ': ',
epoch_loss / num_batches)
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
size = 2
processes = []
for rank in range(size):
p = Process(target=init_processes, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()- 完整代码: dist-SGD.py
- 此代码仅实现了多 worker 组网及通信原语功能
- 但是数据集分割仍需手工编码实现
- All-reduce 操作仍需显式调用,因为其为数据并行算法相关的
- 开发及运行效率低下
DDP (torch.nn.parallel.DistributedDataParallel)
DDP 全称为 DistributedDataParallel,是 PyTorch 提供的一种高效数据并行训练模块,用于在多进程环境下进行分布式训练。
DDP 的主要优点:
- 简化分布式编程 - 隐藏了复杂的通信细节,用户只需要少量代码修改即可将单机程序转换为分布式程序
- 高效通信 - 采用 Ring-AllReduce 算法实现梯度同步,避免了中心节点带宽瓶颈
- 通信和计算重叠 - 采用梯度累积的形式,实现通信与计算的并行执行
- 支持多种后端 - 兼容 NCCL、Gloo、MPI 等不同通信后端
- 自动梯度同步 - 在反向传播过程中自动完成梯度的 AllReduce 操作
DDP 的作用:
- 在多台机器或单机多卡环境中实现数据并行训练
- 确保模型参数在各进程间的一致性
- 优化分布式训练的性能和通信效率
- 提供容错机制,处理进程失败等异常情况
以下是 DDP 使用示例:
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# 初始化分布式环境
dist.init_process_group(backend="nccl")
local_rank = dist.get_rank()
torch.cuda.set_device(local_rank)
# 创建模型并移至对应设备
model = Net().to(local_rank)
# 将模型封装到DDP中
ddp_model = DDP(model, device_ids=[local_rank])
# 正常训练流程
optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.01)
for data, target in train_loader:
data, target = data.to(local_rank), target.to(local_rank)
optimizer.zero_grad()
output = ddp_model(data)
loss = criterion(output, target)
loss.backward() # DDP自动同步梯度
optimizer.step()DDP 把 dist 中的 send/recv 和 all-reduce 封装起来了,用户只需要调用 DDP 的接口即可。
- DDP 实践代码: densenet-DDP.py
跨机器训练
多机器训练的需要确定一个主节点,主节点负责协调所有的工作节点。主节点的作用是分配任务、收集结果、同步参数等。主节点可以是任意一台机器,但通常选择性能最强的一台机器作为主节点。同时还需要确定从节点,从节点是指除了主节点之外的所有机器。每个从节点都需要知道主节点的地址和端口号,以便进行通信。
- 在多机训练中,通常使用
tcp://协议进行通信。主节点的地址和端口号需要在所有从节点上配置好,以便进行通信。可以通过环境变量MASTER_ADDR和MASTER_PORT来设置主节点的地址和端口号。 - 在多机训练中,通常使用
gloo或nccl作为通信后端。gloo是一个高性能的通信库,支持多种通信模式,如点对点通信、广播、聚合等。nccl是 NVIDIA 提供的一个高性能的通信库,专门用于 GPU 之间的通信,支持多种通信模式,如点对点通信、广播、聚合等。
不过区分主从节点不代表通信方式是使用参数服务器架构,其实实际上使用的依然可以是 Ring All-Reduce。
主节点启动 bash 脚本
#!/bin/bash
# 设置主节点信息
export MASTER_ADDR="192.168.1.100" # 主节点IP地址
export MASTER_PORT="29500" # 主节点端口
export WORLD_SIZE=4 # 总进程数(所有机器的GPU总数)
export NODE_RANK=0 # 当前节点的rank(主节点为0)
export NPROC_PER_NODE=2 # 每个节点上的进程数(GPU数)
# 启动分布式训练
python -m torch.distributed.launch \
--nproc_per_node=$NPROC_PER_NODE \
--nnodes=$WORLD_SIZE \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
train_script.py从节点启动 bash 脚本
#!/bin/bash
# 设置主节点信息(与主节点相同)
export MASTER_ADDR="192.168.1.100" # 主节点IP地址
export MASTER_PORT="29500" # 主节点端口
export WORLD_SIZE=4 # 总进程数(所有机器的GPU总数)
export NODE_RANK=1 # 当前节点的rank(从节点为非0值,每个从节点不同)
export NPROC_PER_NODE=2 # 每个节点上的进程数(GPU数)
# 启动分布式训练
python -m torch.distributed.launch \
--nproc_per_node=$NPROC_PER_NODE \
--nnodes=$WORLD_SIZE \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
train_script.py如果服务器上有多张网卡,需要指定使用那张网卡进行通信,可以通过设置环境变量 NCCL_SOCKET_IFNAME 来指定使用的网卡。
export NCCL_SOCKET_IFNAME=eth0 # 使用eth0网卡进行通信当主节点启动后,主节点会等待与从节点通信的建立。如果尚未建立通信,则主节点会一直处于等待状态。可以通过设置环境变量 NCCL_DEBUG 来查看通信的详细信息。
export NCCL_DEBUG=INFO # 打印通信的详细信息同步 barrier
不同的机器之间的硬件性能可能有差异,导致不同机器之间的训练速度不一致。为了保证训练的同步性,可以使用 barrier 来实现同步。barrier 的作用是阻塞所有进程,直到所有进程都到达 barrier 位置。
import torch.distributed as dist
import torch.multiprocessing as mp
import os
import time
def run(rank, size):
print(f"Rank {rank} is waiting at barrier, now is {time.time()}")
dist.barrier() # 等待所有进程到达 barrier
print(f"Rank {rank} has passed barrier")
time.sleep(1) # 模拟训练过程
print(f"Rank {rank} has finished training, now is {time.time()}")Horovod
“Hovovod is a distributed deep learning training framework that makes it easy to take a single-GPU TensorFlow or PyTorch program and run it on many GPUs and many machines with minimal code changes.”
Horovod 是 Uber 开源的一个分布式深度学习训练框架,支持 TensorFlow、Keras、PyTorch 和 MXNet 等深度学习框架。Horovod 的设计目标是使分布式训练变得简单和高效。Horovod 的核心思想是使用 Ring All-Reduce 算法来实现参数的同步更新,从而提高训练速度。
- Horovod 代码: horovod.py
Horovod 尽可能的保证了多卡代码的实现上和单卡的实现类似。
启动命令
horovodrun -np 4 -H localhost:4 python train.py --batch-size 64 --epochs 3 --fp16-allreduce --use-adasum其中 -np 表示总进程数,-H 表示每台机器的进程数。--fp16-allreduce 表示使用 fp16 进行 all-reduce,--use-adasum 表示使用 adasum 算法进行 all-reduce。backend 默认为 MPI,支持 gloo 和 nccl。
参考资料