

KMP 算法简介
KMP算法(Knuth-Morris-Pratt算法)是一种高效的字符串匹配算法,用于在主文本串(Text)中快速查找模式串(p)的出现位置。其核心思想是通过预处理模式串,利用已匹配的信息避免不必要的回溯,将时间复杂度从暴力匹配的 优化至 。
KMP 算法思想
- 避免无效匹配:当匹配失败时,KMP算法不会回溯主文本串,而是利用模式串的部分匹配信息,直接跳过一些字符进行下一次匹配。
- 部分匹配表 (Partial Match Table, PMT):KMP算法通过构建一个部分匹配表(也称为前缀表或失配表),记录模式串中每个位置的最长相等前后缀长度。这个表用于在匹配失败时决定模式串应该向右移动多少位。
算法步骤
最长公共前后缀 (Longest Prefix Suffix, LPS)
LPS 就是给定一个字符串后,其前缀和后缀的最长公共部分的长度 (注意这个公共部分不能是字符串本身)。
- 例如,对于字符串
"CABABAC","ABABAC"和"ABAB"我们列个表说明它的 LPS 是什么
| 字符串 | 前缀 | 后缀 | LPS |
|---|---|---|---|
"CABABAC" | ["C", "CA", "CAB", "CABA", "CABAB", "CABABA"] | ["C", "AC", "BAC", "ABAC", "BABAC", "ABABAC"] | 1 |
"ABABAC" | ["A", "AB", "ABA", "ABAB", "ABABA"] | ["C", "AC", "BAC", "ABAC", "BABAC"] | 0 |
"ABAB" | ["A", "AB", "ABA"] | ["B", "AB", "BAB"] | 2 |
- 可以发现一些规律,
- 一个字符串有自己的前缀列表和后缀列表 (均不包含自身),且列表中的前一个元素一定是后一个元素的子串(更确切地说是前缀或后缀)。
- LPS 就是前缀列表和后缀列表的公共部分中最长的那个的长度。
构建 LPS 数组
对于给定的模式串 p,LPS 数组其实就是模式串 p 的各个前缀子串 (含自身) 的 LPS。显然,由于各个前缀子串之间有包含的关系,因此 LPS 数组的构造可以用动态规划的思想来避免重复计算。
初始化 LPS[i] = 0, i = 0, 1, ..., len(p) - 1。使用两个指针 i 和 j 进行处理。
i、j 指针的更新逻辑
指针含义:
当前子串:
p[0:i],表示模式串p的前i个字符。p[0:j]: 当前子串的最长公共前后缀对应的前缀部分p[i-j+1:i]: 当前子串的最长公共前后缀对应的后缀部分i:遍历模式串的当前位置索引,从1开始;表示前i个字符形成的子串的右侧字符 (注意这个右侧字符不在子串中,相当于是左闭右开),同时也是子串p[i-j+1:i]的右侧字符。j:当前已匹配的最长公共前后缀长度;表示前j个字符形成的子串p[0:j]的右侧字符 (同样注意这个右侧字符不在子串中)
更新条件判断原理:
动态规划设计:
- 不论
p[i] == p[j]是否成立,我们其实已经得到了p[0:j-1] == p[i-j+1:i]这个先验条件的。 - 因此可以基于这个条件减少不必要的回溯。
- 不论
失配回退条件 (
j > 0 and p[i] != p[j]):- 当前字符不匹配且存在已匹配前缀时,利用
lps[j-1]回退到次长匹配位置 - 避免从头开始匹配,复用已知的前后缀信息
- 这里是
while循环,就是说要一直找到合适的匹配才行,找到合适的匹配后,就可以经过p[i] == p[j]的条件来更新j
- 当前字符不匹配且存在已匹配前缀时,利用
匹配递增条件 (
p[i] == p[j]):- 字符匹配成功时,前后缀长度加1
- 更新
lps[i] = j
边界处理:
j = 0时无法再回退,直接设置lps[i] = 0
核心机制:通过 j = lps[j-1] 实现智能回退,将线性扫描中的潜在二次复杂度优化为线性时间。体现有滑动窗口和动态规划的思想。
def build_lps(p):
lps = [0] * len(p)
j = 0 # 当前最长公共前后缀长度
for i in range(1, len(p)):
while j > 0 and p[i] != p[j]:
j = lps[j - 1]
if p[i] == p[j]:
j += 1
lps[i] = j
return lps"ABABA" | "ABACA" |
|---|---|
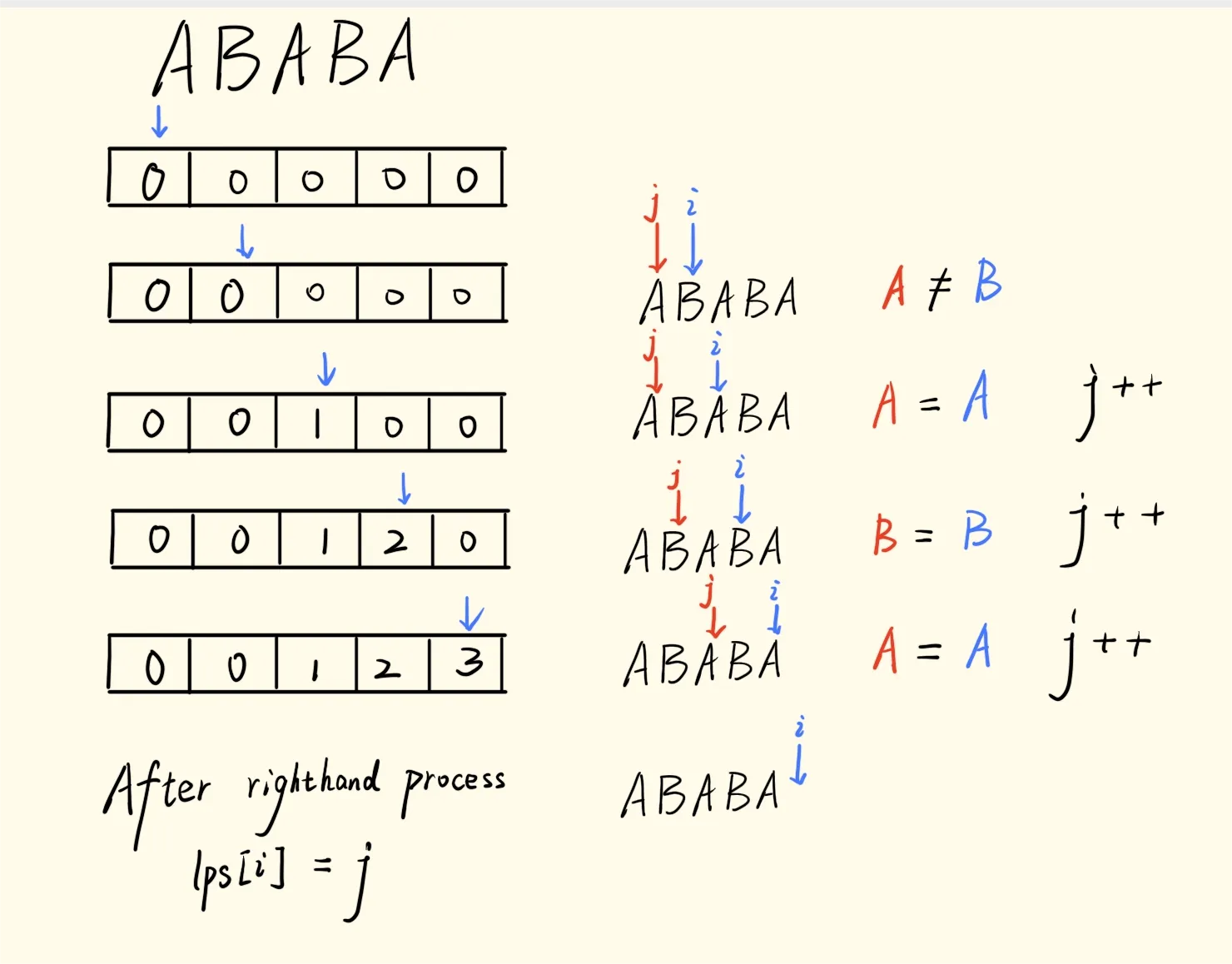 | 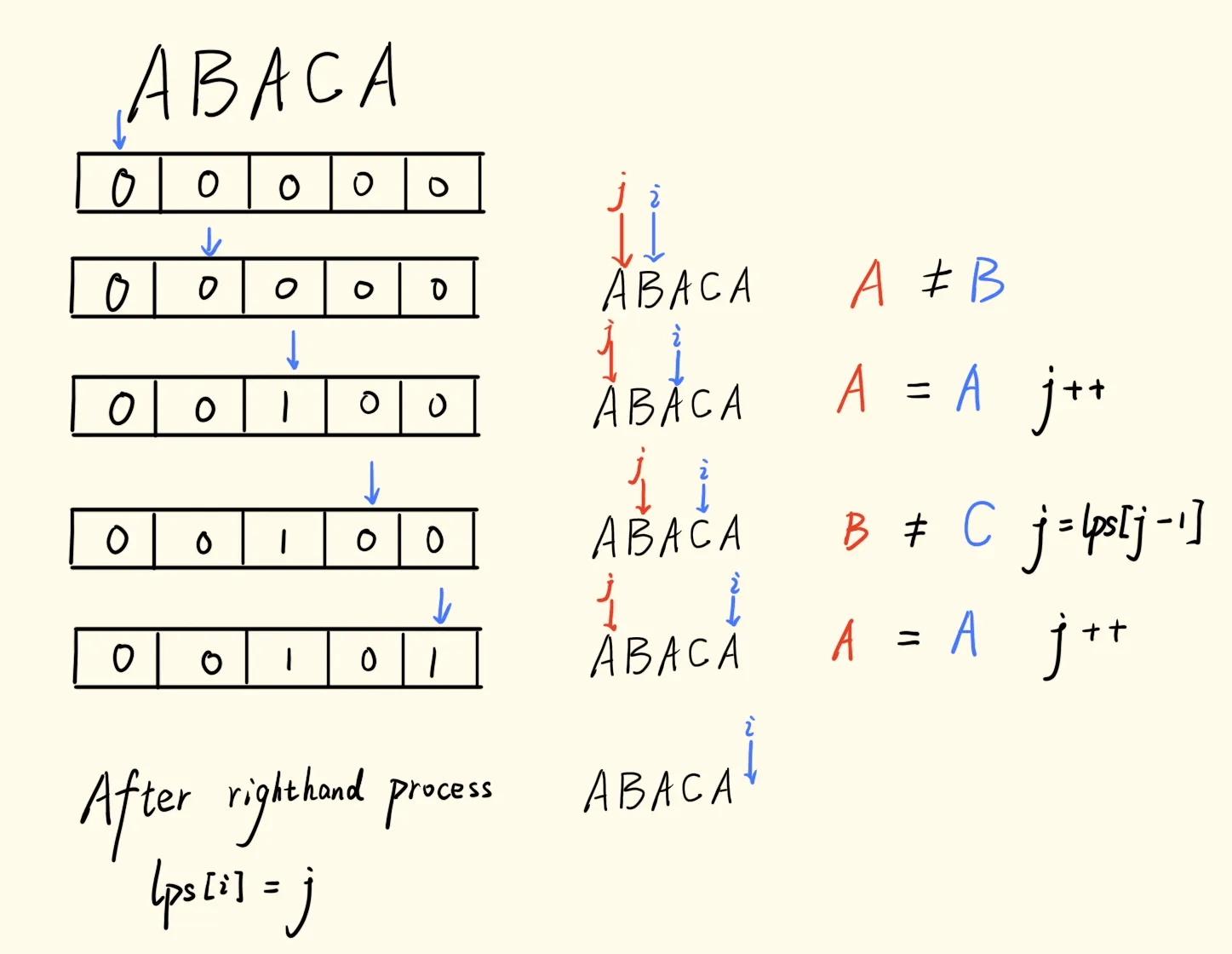 |
lps[i] = j 记录的是模式串 p[0:i] 的最长公共前后缀长度。
匹配过程
完成 LPS 数组的构建后,接下来就是使用这个 LPS 数组来进行模式串 p 在主文本串 T 中的匹配。
这里依然采用两个指针进行匹配。我们的目标是为了实现隐式匹配子串 T[i-j:i] 和模式子串 p[0:j]。当处理到 T[i] 和 p[j] 时,我们已经得到 T[i-j:i] == p[0:j]
如果
T[i] == p[j],说明当前字符匹配成功,继续向后匹配,令i += 1和j += 1。- 如果
j = len(p),说明模式串p完全匹配成功,此时记录匹配位置i - j(主字符串中子串的起始位置),然后回退到最长公共前后缀位置j = lps[j - 1]。
- 如果
匹配失败时,我们其实已经成功匹配了
p[0:j]和T[i-j:i],但是T[i] != p[j]。- LPS 数组的作用是当匹配失败,即发现
T[i] != p[j]时,利用p[0:j]的 LPS 数值信息,调整j = lps[j - 1],而不是从头开始匹配。
- LPS 数组的作用是当匹配失败,即发现
j = lps[j - 1]的含义:- 将
p的前缀快速对齐到T中已经匹配的后缀,直接将模式串的“前缀”对齐到当前已匹配的“后缀”位置,跳过不可能匹配的位置。lps[j - 1]中j-1表示当前已经匹配的子串的末位,避免了重复比较。
- 将
def kmp_search(T, p):
lps = build_lps(p)
i = 0 # 主文本串 T 的索引
j = 0 # 模式串 p 的索引
matches = [] # 存储匹配位置
while i < len(T):
if T[i] == p[j]:
i += 1
j += 1
if j == len(p): # 完全匹配
matches.append(i - j) # 匹配位置
j = lps[j - 1] # 回退到最长公共前后缀位置
else:
if j > 0:
j = lps[j - 1] # 回退到次长公共前后缀位置
else:
i += 1 # 主文本串指针向右移动
return matches
求连续出现的最大模式串次数
给定一个主文本串 T 和模式串 p,目标是找到模式串 p 在主文本串 T 中连续出现的最大次数。 可以用 KMP 算法来先找到所有匹配位置,然后统计连续出现的次数。
def max_consecutive_occurrences(T, p):
matches = kmp_search(T, p)
if not matches:
return 0
max_cnt = 1
curr_cnt = 1
for i in range(1, len(matches)):
if matches[i] == matches[i - 1] + len(p):
curr_cnt += 1
else:
max_cnt = max(max_cnt, curr_cnt)
curr_cnt = 1
return max(max_cnt, curr_cnt)