

分布估计算法,估计概率分布的一些方法
概述
分布估计算法起源于遗传算法,其基本思想是使用概率的方法描述和表示每一代群体。对比优化问题,优化问题中的每个自变量都被看做是一个随机变量,将所有的随机变量表示为一个随机向量 ,其中每个随机变量 代表一个个体的某一特征。于是,一个群体就对应于该随机向量的一个分布。在一个概率分布上进行采样,可以生成更有价值的群体和个体。
分布估计算法是一种基于种群的随即优化算法,它利用每一代种群,学习随机变量的分布,然后在学习得到的分布的基础上再生成下一代新种群,逐步迭代直至收敛。
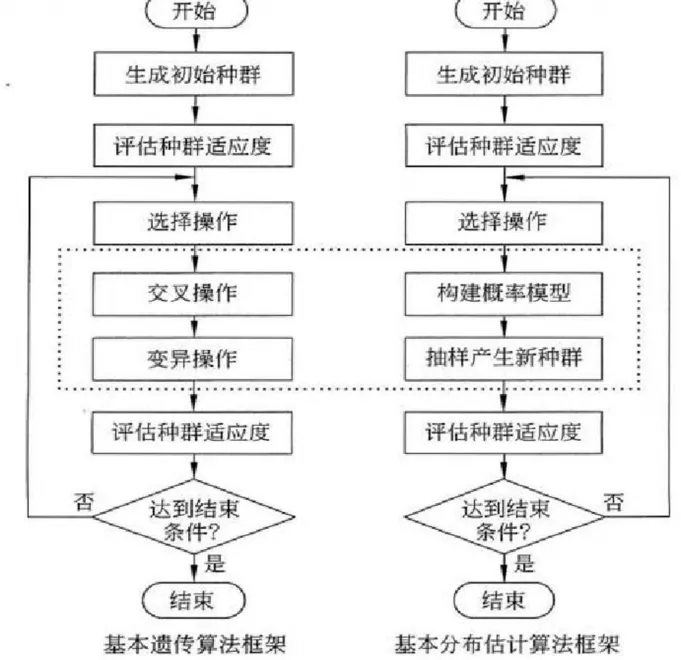
由于分布估计算法没有交叉和变异操作,因此通常不用基因来描述个体所包含的信息,取而代之的是变量。
算法步骤
变量无关的分布式估计算法
UMDA (Univariate Marginal Distribution Algorithm)
- 随机产生 个个体来组成一个初始种群,并评估初始种群中所有个体的适应度
- 按适应度从高到低的顺序对种群进行排序,并从中选取最优的 个个体 ()
- 分析所选出的 个个体所包含的信息,估计其联合概率分布
其中 为边缘分布。
- 从构建的概率模型 中采样,得到 个新样本,构建新种群。
- 若达到终止条件就结束算法流程,否则跳转至第 2 步
很显然,UMDA 算法的假设是单个特征变量之间是相互独立的,和 Naive Bayes 一样,认为变量之间是独立不相关的。
Example: OneMax Problem
对于固定长度为 的二进制串, OneMax 问题就是要求找到一个包含 的个数最大的二进制串,即找到 ,,使得 最大化。
解:
可以用 UMDA 来求解 OneMax 问题。不妨以四维的 OneMax 为例,设种群分布的概率模型可以用一个简单的概率向量 来表示描述种群分布的概率模型,其中 表示取 的概率, 表示取 的概率。
1. 产生初始种群,定义初始化概率向量模型 ,然后根据 产生规模为 10 的初始种群,根据 计算初始种群适应度。其中产生的种群如图
| 编号 | x₁ | x₂ | x₃ | x₄ | f |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 1 | 3 |
| 2 | 1 | 0 | 0 | 0 | 1 |
| 3 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 1 | 1 | 1 | 3 |
| 5 | 1 | 1 | 0 | 1 | 3 |
| 6 | 0 | 1 | 1 | 0 | 2 |
| 7 | 1 | 0 | 1 | 0 | 2 |
| 8 | 0 | 0 | 1 | 1 | 2 |
| 9 | 1 | 0 | 0 | 0 | 1 |
| 10 | 1 | 0 | 0 | 1 | 2 |
2. 按照种群的适应度从高到低进行排序。设 , 从种群中选出适应度较高的 5 个个体用来更新概率向量模型 。更新时,令 ,其中 为在选出的较优个体中 的个体数。若选取的个体如下表所示
| 编号 | 原编号 | x₁ | x₂ | x₃ | x₄ | f |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 0 | 1 | 3 |
| 2 | 4 | 0 | 1 | 1 | 1 | 3 |
| 3 | 5 | 1 | 1 | 0 | 1 | 3 |
| 4 | 6 | 0 | 1 | 1 | 0 | 2 |
| 5 | 7 | 1 | 0 | 1 | 0 | 2 |
则可以得到更新的模型为
3. 根据更新后的概率模型 产生新的种群,并计算适应度
| 编号 | x₁ | x₂ | x₃ | x₄ | f |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 2 |
| 2 | 0 | 1 | 0 | 0 | 1 |
| 3 | 0 | 1 | 1 | 1 | 3 |
| 4 | 1 | 1 | 1 | 1 | 4 |
| 5 | 0 | 1 | 1 | 1 | 3 |
| 6 | 0 | 0 | 1 | 0 | 1 |
| 7 | 1 | 1 | 1 | 0 | 3 |
| 8 | 1 | 1 | 1 | 1 | 4 |
| 9 | 1 | 1 | 0 | 1 | 3 |
| 10 | 1 | 1 | 0 | 0 | 2 |
4. 重复步骤 2 和 3,直到达到终止条件。最终得到结果如下表
| 进化代数 | 概率向量 | 种群平均适应度 |
|---|---|---|
| 1 | (0.5,0.5,0.5,0.5) | 2.2 |
| 2 | (0.6,0.8,0.6,0.6) | 2.6 |
| 3 | (0.8,1.0,0.6,0.8) | 2.9 |
| 4 | (1.0,1.0,1.0,0.8) | 3.8 |
| 5 | (1.0,1.0,1.0,1.0) | 4.0 |
PBIL (Population Based Incremental Learning)
PBIL (Population Based Incremental Learning) 是一种分布估计算法,它结合了遗传算法和竞争学习的思想。与UMDA类似,PBIL也通过概率向量来表示种群中变量的分布,但采用了不同的更新机制。
PBIL的工作原理如下
- 增量式学习机制:PBIL不是直接将概率向量更新为当前选出个体的样本分布,而是采用一种渐进式学习方式,通过学习率参数逐步向最优个体方向调整
- 竞争学习机制:PBIL采用竞争学习的方式来更新概率向量。每次迭代中,PBIL会选择适应度较高的个体,并根据这些个体的信息来更新概率向量。具体来说,PBIL会将选出个体的基因信息与当前概率向量进行比较,并根据适应度的差异来调整概率向量。
- 更新概率向量:PBIL通过以下公式来更新概率向量
其中 是更新后的概率向量, 是当前的概率向量, 是学习率, 是种群大小, 是第 代中第 个个体。
更新步骤类似 UMDA,在此不列出代码流程。
CGA (Compact Genetic Algorithm)
CGA (Compact Genetic Algorithm) 是一种不同于 UMDA、PBIL 的分布估计算法。CGA 的种群规模很小,只产生两个个体,分别是最优个体和次优个体。CGA 通过对这两个个体进行交叉和变异来生成新的个体,并根据适应度来更新概率向量。
算法步骤为
Algorithm
| Input: | 问题规模 , 种群规模 , 学习率 (通常为 ) |
| Output: | 最优解 |
| 1: | 初始化概率向量 ,其中 对于所有 |
| 2: | while 未达到终止条件 do |
| 3: | 从概率向量 中采样生成两个个体 和 |
| 4: | 计算适应度: 和 |
| 5: | 确定胜者 和败者 (若 则 , ; 否则 , ) |
| 6: | for 到 do |
| 7: | if then |
| 8: | if then else |
| 9: | end if |
| 10: | 将 限制在 范围内,防止收敛到 0 或 1 |
| 11: | end for |
| 12: | 如有必要,更新 |
| 13: | end while |
| 14: | return |
变量相关的分布式估计算法
MIMC (Mutual Information Maximizing Input Clustering)
MIMIC (Mutual Information Maximizing Input Clustering) 是一种基于链式概率模型的分布估计算法。MIMIC 通过最大化变量之间的互信息来学习变量之间的依赖关系,从而构建一个更复杂的概率模型。
考虑建模为链式概率模型,给定一个变量集合 ,它的联合分布概率密度函数可表示为
MIMIC 假设变量依赖是链式的,即每个变量只依赖于它前面的变量。目标是找到一种变量的最优排序,使得这种依赖链对应的联合分布概率最接近真实分布。
排序可以表示为
对应于
使用 KL 散度来度量真实分布和估计分布之间的差异,MIMIC 的目标是最小化以下目标函数
其中, 是真实分布的熵, 是交叉熵。
MIMIC 引入了一种贪心算法来求最有排列 
类似地,算法可以扩展到树状模型和更复杂的概率模型如贝叶斯网络。
连续变量的分布估计算法
类似地处理,还是采用 UMDA、PBIL 和 CGA 等算法,只是将离散变量替换为连续变量。例如,只需要把每个变量定义为一个一元高斯分布,然后根据分布生成新个体。即可类似地对应求解。