

概述
进化计算 (Evolutionary Computation) 是一系列启发式的搜索技术
- 遗传算法 (Genetic Algorithm, GA)
- 遗传规划 (Genetic Programming, GP)
- 进化策略 (Evolution Strategy, ES)
- 进化规划 (Evolutionary Programming, EP)
- 差分进化 (Differential Evolution, DE)
具有高鲁棒性,广泛适应性的全局优化算法。它们模拟自然选择和遗传学的原理,使用种群的概念来搜索解空间。进化计算通常用于解决复杂的优化问题,尤其是那些具有高维度、非线性或不连续性的函数。
算法思想
生物群体的生存过程遵循自然选择的原则,适者生存。进化计算模拟了这一过程,通过选择、交叉、变异等操作来生成新的解。
- 选择:根据适应度函数选择优秀的个体进行繁殖。
- 交叉:将两个或多个个体的基因组合在一起,产生新的个体。交叉操作可以是单点交叉、多点交叉或均匀交叉等。
- 变异:对个体的基因进行随机修改,以增加种群的多样性。变异操作可以是位翻转、交换或插入等。
遗传算法
遗传算法是最早提出的进化计算方法之一,主要用于优化问题。
编码
将解空间的状态编码为位串形式的code,通常使用二进制编码、实数编码或符号编码等。
二进制编码
将解空间的每个维度用二进制位表示,适用于离散问题。若解空间的最大值为 , 最小值为 ,则可以用 位二进制数表示解空间中的十进制状态 。
其中 对应的二进制数为 。
对于精度为 的优化问题, 的取值为 。
Example: 在某个优化问题中,搜索范围为 精度要求为,请问需要至少多少位二进制编码
解:
格雷码
对于一些连续优化问题,二进制编码由于遗传算法的随即特性而使其局部搜索能力较差。为了改进这一特性,人们提出使用格雷码。
首先要说明为什么二进制编码不好。不妨考虑一个简单的例子,在十进制中,19和20相差仅为1,但是在二进制中,19的二进制是10011,20的二进制是10100,它们之间相差3位。这就导致了在使用二进制的编码中,实际上如果采用每次只改变一位的方式进行变异,那么在19和20之间的变异就需要经过至少3次变异才能到达。然而,我们的优化问题往往是针对十进制空间进行的,这种编码方式显然会导致搜索效率的降低。
格雷码的特点是十进制中相邻的两个数只有一位不同,这样在进行变异时,变异的幅度就会小很多。例如在十进制中,19和20的格雷码分别为10011和10010,它们之间只相差一位。
格雷码的公式如下
其中 是格雷码的第 位, 是二进制编码的第 位, 表示异或操作。
要从格雷码得到十进制表达,需要先把格雷码变为二进制编码,再由二进制得到十进制。
Example: 把 11 变为格雷码,并计算出 1101 对应的十进制数
解:
- 十进制编码
d = 11,对应的二进制编码为b = 1011, 求格雷码相当于将二进制编码自左向右求异或 (有点类似求差分的感觉),于是可以求出对应格雷码为g = 1110。 - 格雷码为
g = 1101, 先求对应二进制编码。格雷码求二进制编码类似计算前缀和,把二进制编码的前一位和格雷码中当前位异或即可求得结果。b = 1001, 从而十进制编码为d = 9。

4位格雷码对应表
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 二进制 | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| 格雷码 | 0000 | 0001 | 0011 | 0010 | 0110 | 0111 | 0101 | 0100 | 1100 | 1101 | 1111 | 1110 | 1010 | 1011 | 1001 | 1000 |
实数编码
将解空间的每个维度直接用实数表示,适用于连续优化问题。实数编码直接使用浮点数表示解空间中的状态,个体的基因型和表现型之间没有转换过程。
其中 是一个 维向量, 是第 个维度的值, 是第 个维度的取值范围。
优势:
- 表示精度更高,不受位数限制
- 计算效率更高,避免了编码和解码过程
- 更接近问题的自然表示
- 便于应用特定领域的遗传算子
实数编码的遗传算子:
交叉操作:
- 算术交叉:,
- 离散交叉:从父代基因中随机选择每个位置的值
- BLX- 交叉:在扩展的区间内随机选择
变异操作:
- 高斯变异:
- 均匀变异:在指定区间内随机替换
- 非均匀变异:变异幅度随代数增加而减小
产生初始群体
采用随机方法生成若干个个体的集合,该集合称为初始种群。初始种群中个体的数量称为种群规模。种群规模越大,搜索的范围也就越广,但是每代的计算量也会增加。通常,种群规模取 。
适应度函数
遗传算法对一个个体(也就是一个解)优劣的评价用适应度函数来表示,适应度函数值越大,解的质量越好(当然也可以反过来)。适应度函数是遗传算法进化过程的驱动力,也是自然选择的唯一标准。通常,适应度函数就设置为优化问题的目标函数。
选择操作
根据个体的适应度函数值来决定该个体的它在下一代是被淘汰还是被遗传。选择操作通常有以下几种方法
- 轮盘赌选择 (Roulette Wheel Selection):根据适应度函数值的比例来选择个体,适应度函数值越高,被选择的概率越大。
- 锦标赛选择 (Stochastic Tournament Selection):随机选择若干个体进行比赛,适应度函数值高的个体胜出。
- 期望值选择 (Stochastic Universal Sampling):根据个体的适应度函数值来计算生存期望数目,生存期望数目越高,被选择的概率越大。
- 确定性采样选择 (Deterministic Sampling):根据个体的适应度函数值来计算生存期望数目,生存期望数目越高,被选择的概率越大。
轮盘赌选择
将每个个体的适应度函数值计算出来,归一化成为概率值(类似 softmax 操作),然后根据概率值进行选择。
- 优点:简单易实现,适用于大多数问题。
- 缺点:容易导致早熟现象,即过早地收敛到局部最优解。
计算归一化概率 ,其中 是第 个个体的概率, 是第 个个体的适应度函数值, 是种群规模。
设定轮盘赌区。构造一个前缀和函数 ,那么区间 就是第 个个体对应的区间,。
在区间 上随机选择一个数 ,如果 ,则选择第 个个体。
用这样一个方法,重复 次,就可以得到 个个体。
锦标赛选择
锦标赛选择是从种群中随机选择 个个体进行比赛,适应度函数值最高的个体胜出( 选 1)。重复 次,就可以得到 个个体。
- 优点:简单易实现,适用于大多数问题。
- 缺点:容易导致早熟现象,即过早地收敛到局部最优解。
期望值选择
根据每个个体在下一代群体中的生存期望值来进行随机选择运算。期望值选择的基本思想是,认为每个个体在下一代群体中的生存期望值与其适应度函数值成正比。
- 优点:避免了早熟现象,适用于大多数问题。
- 缺点:计算复杂度较高,适用于小规模种群。
- 计算每个个体的生存期望数目 ,其中 是第 个个体的生存期望数目, 是第 个个体的适应度函数值, 是种群规模。
- 若某一个个体被选中参与交叉运算,则生存期望数目减去 , 若某一个个体未被选中参与交叉运算,则它在下一代中的生存期望数目减去 。
- 随着选择过程的进行,若某一个个体的生存期望数小于 ,则它在下一代中就不再被选中。
确定性采样选择
针对最优个体保留的不确定性,此方法按照一种确定的方式来进行选择操作。
- 计算个体在下一代中的生存期望
- 确定各个对应个体在下一代群体中的确定生存数目,对个体进行降序排序,顺序取前 个个体为下一代群体。
交叉操作
交叉是产生新个体的主要方式,从一对亲代中产生一对自带个体。通常交叉概率 ,交叉概率越高,产生新个体的数量就越多。交叉操作的目的是为了增加种群的多样性,决定了全局搜索能力。设群体规模为 ,交叉操作后产生的个体数量为 ,则有 , 不过一般工程上还需要把 取最近的偶数。
交叉操作通常有以下几种方法
单点交叉 (Single Point Crossover):在两个父代个体中随机选择一个交叉点,将交叉点之前的部分交换,产生两个新的个体。随机性除了亲代个体的随机性外,还有微店选取的随机性。
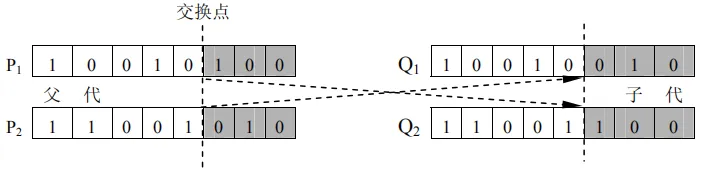
多点交叉 (Multi Point Crossover):在两个父代个体中随机选择多个交叉点,将交叉点之间的部分交换,产生两个新的个体。
均匀交叉 (Uniform Crossover):在两个父代个体中随机选择每个基因的位置进行交换,产生两个新的个体。
算术交叉 (Arithmetic Crossover):在两个父代个体中随机选择一个交叉点,将交叉点之前的部分进行线性组合,产生两个新的个体。
变异操作
变异是另一种产生新个体的方式,依据变异概率 将个体编码串中的某些基因用其他基因值来替换,从而形成一个新的个体。变异操作决定了遗传算法的局部搜索能力,同时保持群体多样性。变异概率 是针对单个字符而言的,即 ,其中 是变异的基因数目, 是种群规模, 是个体编码的长度。变异概率 的取值范围通常为 ,也可以根据具体问题进行调整。变异概率越高,产生新个体的数量就越多。
注意,变异概率是一个敏感参数,过高的变异概率会导致搜索效率降低,过低的变异概率会导致搜索陷入局部最优解。
变异操作通常有以下几种方法
- 位翻转变异 (Bit Flip Mutation):对二进制编码的个体,随机选择一个基因,将其值翻转。
- 位交换变异 (Bit Swap Mutation):对二进制编码的个体,随机选择两个基因,将它们的值交换。
- 位插入变异 (Bit Insert Mutation):对二进制编码的个体,随机选择一个基因,将其值插入到另一个基因的位置。

- 高斯变异 (Gaussian Mutation):对实数编码的个体,随机选择一个基因,将其值加上一个高斯分布的随机数。
- 均匀变异 (Uniform Mutation):对实数编码的个体,随机选择一个基因,将其值加上一个均匀分布的随机数。
- 非均匀变异 (Non-uniform Mutation):对实数编码的个体,随机选择一个基因,将其值加上一个非均匀分布的随机数。
- 交换变异 (Swap Mutation):对实数编码的个体,随机选择两个基因,将它们的值交换。
- 插入变异 (Insert Mutation):对实数编码的个体,随机选择一个基因,将其值插入到另一个基因的位置。
- 逆转变异 (Inversion Mutation):对实数编码的个体,随机选择两个基因,将它们之间的基因值逆转。
- 反转变异 (Reverse Mutation):对实数编码的个体,随机选择两个基因,将它们之间的基因值反转。
终止条件
终止条件一般可以用最大迭代次数、适应度函数值不再变化、达到预设的精度要求等条件来判断。
算法流程
Algorithm: 基本遗传算法
| Input: | 种群规模 ,染色体长度 ,交叉概率 ,变异概率 ,最大迭代次数 |
| Output: | 最优解 及其适应度值 |
| 1: | 初始化 随机生成初始种群 |
| 2: | 评估 计算种群中每个个体的适应度值 , |
| 3: | 迭代进化 |
| 4: | while and 未满足终止条件 do |
| 5: | 选择 根据个体的适应度值,使用轮盘赌或锦标赛等方法选择父代个体 |
| 6: | 交叉 按概率 对选中的父代个体进行交叉操作,生成子代个体 |
| 7: | 变异 按概率 对子代个体的每个基因进行变异操作 |
| 8: | 评估 计算新生成的子代个体的适应度值 |
| 9: | 更新 根据适应度值从父代和子代中选择 个优秀个体组成新的种群 |
| 10: | |
| 11: | end while |
| 12: | 返回 迭代过程中找到的最优个体 及其适应度值 |
遗传算法的理论基础
- 传统的模式理论
- 有限状态Markov链模型