

Swarm 本义为昆虫群体,在自然计算中,有一类受昆虫群体行为启发的算法,称为群体智能(Swarm Intelligence)。群体中的个体行为非常简单,但是当它们一起协同工作时,能够产生复杂的行为。
概述
优点:
- 灵活性:群体可以适应随时变化的环境
- 鲁棒性:即使部分个体失败,整个群体也能完成任务
- 自我组织:个体的活动既不受中央控制,也不受局部管理
- 分布式:个体之间的交互是局部的,个体之间没有全局信息
缺点:
- 计算复杂度高:个体之间的交互会导致计算复杂度增加
- 收敛速度慢:群体智能算法通常需要较长的时间才能收敛到最优解
- 信息素均匀分配策略与路径重要性无关:对已搜索路径中的所有路段采用同样的信息素增量实际上与路段的重要性无关。
- 容易出现停滞现象:当所有蚂蚁都选择相同的路径时,系统不再搜索更好的解。
典型算法:
- 粒子群优化(Particle Swarm Optimization, PSO):模拟鸟群觅食行为
- 蚁群算法(Ant Colony Optimization, ACO):模拟蚂蚁觅食行为
- 蜂群算法(Bee Algorithm):模拟蜜蜂觅食行为
- 鱼群算法(Fish School Search, FSS):模拟鱼群觅食行为
蚁群算法 (Ant Colony Optimization)
算法的起源
蚁群自组织行为的双桥实验,蚁群利用遗留在往来路径上的具有挥发性的信息素来进行通信和协调。
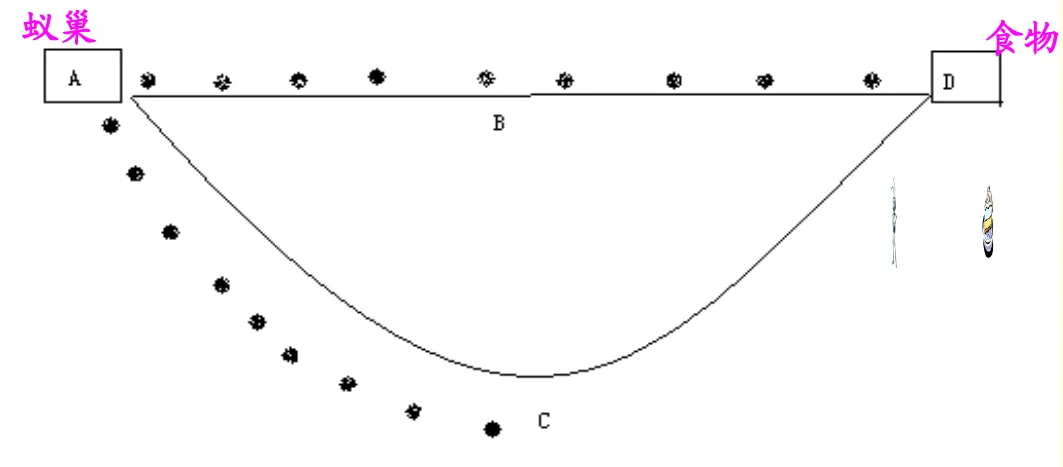 假设有一群蚂蚁,蚂蚁们从A点出发,随机选择路线ABD或ACD,这里路线ABD长度为9个时间单位而ACD的长度为18个时间单位。经过9个时间单位后,走ABD的蚂蚁到达终点,走ACD的蚂蚁刚好走到C点。
假设有一群蚂蚁,蚂蚁们从A点出发,随机选择路线ABD或ACD,这里路线ABD长度为9个时间单位而ACD的长度为18个时间单位。经过9个时间单位后,走ABD的蚂蚁到达终点,走ACD的蚂蚁刚好走到C点。
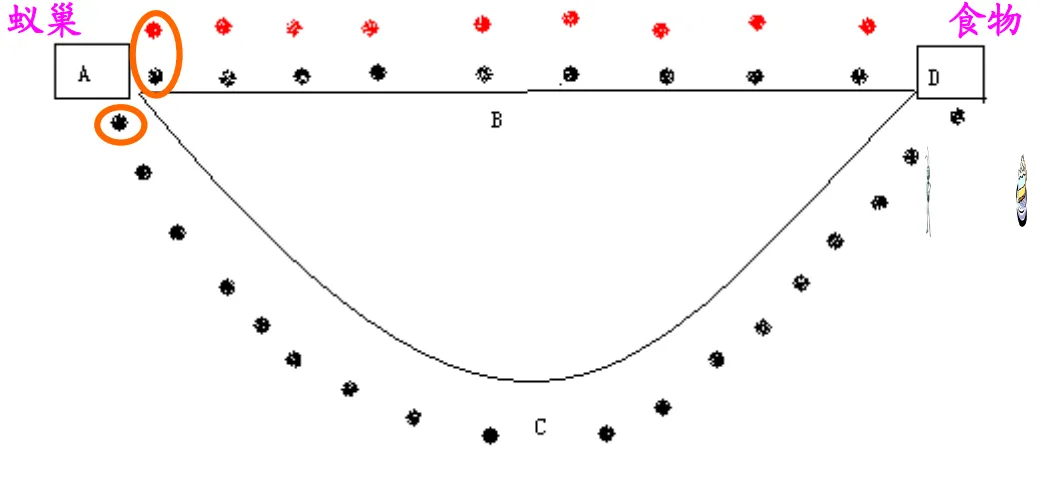 经过18个时间单位后,走ABD的蚂蚁到达终点后得到食物又返回了起点A,而走ACD的蚂蚁刚好走到D点。假设蚂蚁的在单位时间内释放的信息素是个固定量,这样一来,路线ABD上蚂蚁留下的信息素将是路线ACD上蚂蚁留下的信息素的两倍。很显然这有一个正反馈的过程,最终蚂蚁们都会被信息素较多的路线吸引,选择走ABD。
经过18个时间单位后,走ABD的蚂蚁到达终点后得到食物又返回了起点A,而走ACD的蚂蚁刚好走到D点。假设蚂蚁的在单位时间内释放的信息素是个固定量,这样一来,路线ABD上蚂蚁留下的信息素将是路线ACD上蚂蚁留下的信息素的两倍。很显然这有一个正反馈的过程,最终蚂蚁们都会被信息素较多的路线吸引,选择走ABD。
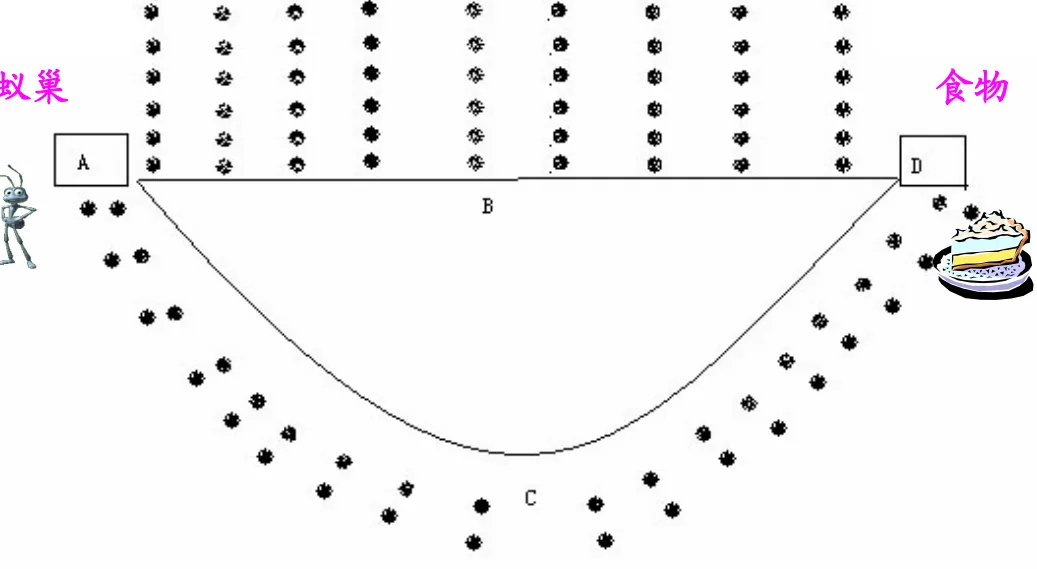 注意,并不是因为蚂蚁们知道哪条路线长就在哪条路上释放较少的信息素,蚂蚁单位时间释放的信息素是定值。
注意,并不是因为蚂蚁们知道哪条路线长就在哪条路上释放较少的信息素,蚂蚁单位时间释放的信息素是定值。
蚁群算法解决 TSP 问题
上述蚁群觅食很好的体现出来了寻找食物时的最优路径选择问题,那么,借助这个思想,可以解决其他类似的优化问题。
作为蚁群算法的蚂蚁个体,其运动和通信的简单规则,需要包含以下几个方面:
搜索范围: 蚂蚁会以一定的搜索半径进行搜索
局部环境: 蚂蚁能感知周围环境的信息
觅食规则: 蚂蚁只在其能感知的范围内进行探索和信息素释放
移动规则: 蚂蚁会朝信息素最多的方向移动,并且,当周围没有信息素指引的时候,蚂蚁会按照自己原来运动的方向惯性地运动下去。如果蚂蚁发现有它已经经过的地点,则以较大概率进行避让。
避障规则: 在蚂蚁的移动方向上有障碍物存在时,蚂蚁会随机选择另一个方向,或者按照信息素的指引继续其觅食行为。
通信规则: 信息素,信息素的挥发和蚂蚁的释放是一个正反馈的过程,信息素的浓度越高,蚂蚁就越容易选择这条路径。
TSP 问题
TSP 问题是一种典型的组合优化问题。给定 个城市的集合,TSP 问题目标是寻找一条只经过各城一次的且长度最短的闭合路径。
用蚁群算法可以很好的解决 TSP 问题。
解:
Algorithm 蚁群算法解决 TSP
| Input: 城市拓扑图 ,城市个数 ,蚂蚁个数 | |
| Output: 最优路径 | |
| 1: | 将 只蚂蚁随机的放到 个城市,并且为每只蚂蚁构造一个禁忌表,记第 只蚂蚁的禁忌表为 。 |
| 2: | 设各路径上的信息素量为 , 为一个较小的常数。// 该步只进行一次,后续不再执行,目的就是希望利用上一次循环的信息素 |
| 3: | for to do |
| 4: | 初始化每个蚂蚁的禁忌表的第一个元素 为它当前所在的城市。 |
| 5: | while 每只蚂蚁的禁忌表没有满 do |
| 6: | 对于每只蚂蚁,根据路径上的信息素和启发式信息(两城市之间的距离) 独立地选择下一个城市。具体地,在 时刻,蚂蚁 从城市 转移到 城市 的概率为 其中下一步允许选择的城市的集合为 , 为城市 i 和城市 j 之间的距离, 和 是两个参数,分别表示信息素和启发式信息的权重。 |
| 7: | 依据概率选出下一个城市 后,将 放入禁忌表 中 |
| 8: | end while |
| 9: | 当所有蚂蚁完成一次周游后,计算所有 只蚂蚁走过的周游长度 ,并更新当前的最优路径; |
| 10: | 各路径上的信息素将进行更新 其中 为蚂蚁 在本次周游中走过的路径长度, 是一个常数, 是信息素挥发速率。 |
| 11: | 清空所有的禁忌表 |
| 12: | end for |
| 13: | return 最优路径 |
典型的蚁群算法模板为
def ACO_MetaHeuristic():
while not terminated:
generateSolutions()
daemonActions()
pheromoneUpdate() # 更新信息素信息素更新的三种设置
有三种基本信息素更新模式:蚁密模型(Ant‑Density)、蚁量模型(Ant‑Quantity)和蚁周模型(Ant‑Cycle)。它们的主要区别在于信息素何时更新(每移动一步或完成整个周游后)以及更新量如何确定(常数、与边长成反比或与整条巡游长度成反比)。其中,蚁密和蚁量模型均为局部更新,前者只按常数沉积、后者根据边长沉积;而蚁周模型采用全局更新,在所有蚂蚁完成一次完整巡游后才统一沉积信息素
蚁密模型(Ant‑Density Model)
- 更新时机:每只蚂蚁在从城市 移动到城市 的瞬间,立即进行信息素更新(局部更新)。
- 更新量:在边 上沉积一个常量 ,与路径长度无关。
- 公式: 其中, 为挥发系数, 为常数。
- 特点与不足:此模型简单易实现,信息素量与蚂蚁数量成正比,但忽略了边长对路径质量的影响,容易导致搜索过度局部化。
蚁量模型(Ant‑Quantity Model)
- 更新时机:同样在每步移动时立即更新(局部更新)。
- 更新量:与边长 成反比,在移动到 时沉积 因此较短边得到更多信息素,有助于局部搜索能力。
- 公式:
- 特点:较蚁密模型更能利用边的启发式信息,但仍为局部更新,无法综合全局路径信息。
蚁周模型(Ant‑Cycle Model)
更新时机:每轮所有蚂蚁完成一次完整巡游后,才统一进行信息素更新(全局更新)。
更新量:对于第 只蚂蚁所走过的每条边 ,沉积
其中 为第 只蚂蚁本次巡游的总长度, 为常数。
整体更新公式:
优势:利用每只蚂蚁全程信息素沉积,兼顾全局与局部,从而常被证明性能优于前两种模式,收敛质量更高。
停滞现象
停滞现象(Stagnation behavior):当所有蚂蚁都选择相同的路径时,系统不再搜索更好的解。原因在于较好路径上的信息素远大于其他边上的,从而使所有蚂蚁都选择该路径。
因此参数 和 的设置非常重要。
- 越大,信息素的影响越大,容易导致停滞现象。 取较大值时,意味着在选择路径时,路径上的信息素非常重要;当 取较小值时,变成随机的贪婪算法。
- 越大,启发式信息的影响越大,容易导致搜索过度局部化。
蚂蚁数量 时,使用 ant-cycle 模型可以在最少迭代次数内找到最优解。
粒子群算法 (Particle Swarm Optimization, PSO)
概述
粒子群算法源于对鸟群捕食行为的研究。假设有一个区域,所有的鸟都不知道食物的位置,但是它们知道当前位置距离食物还有多远。PSO 算法把每个解看作一只鸟,称为 “粒子 (particle)“,所有的粒子都有一个适应值,每个粒子都有一个速度决定它们的飞翔方向和距离,粒子们追随当前最优粒子在解空间中的搜索。
| 鸟群觅食 | 粒子群优化算法 |
|---|---|
| 鸟群 | 搜索空间的一组有效解 (表现为种群规模 ) |
| 觅食空间 | 问题的搜索空间 (表现为维数 ) |
| 飞行速度 | 解的速度向量 |
| 所在位置 | 解的位置向量 |
| 个体认知与群体协作 | 每个粒子 根据自身历史最优位置和群体的全局最优位置更新速度和位置 |
| 找到食物 | 算法结束,输出全局最优解 |
算法流程
初始化一群随机粒子,通过迭代找到最优值。在每次迭代过程中,粒子通过跟踪 “个体极值 ()” 和 “全局极值 ()” 来更新自己的位置。
假设在 维搜索空间中,有 个粒子,其中
- 第 个粒子的位置矢量 ,
- 其飞行速度也是一个矢量,记为 ,
- 第 个粒子搜索到最优的位置为 ,
- 整个粒子群搜索到的最优位置为
对于第 个粒子,它的速度更新公式为
其中 表示第 个粒子在第 维上的新速度, 是惯性权重,控制粒子当前速度的影响, 是学习因子(加速常数),分别表示个体认知和群体协作的权重, 是在 范围内的随机数,增加随机性, 表示第 个粒子在第 维上的历史最优位置, 是全局最优位置在第 维上的值, 代表第 个粒子在第 维上的当前位置。
而位置更新公式为
其中, 是第 个粒子在第 维上的新位置, 是第 个粒子在第 维上的新速度。
Python 实现
import numpy as np
from tqdm import tqdm
class PSO:
def __init__(self, n_particles, n_dim, options, bounds=None):
self.n_particles = n_particles
self.n_dim = n_dim
self.bounds = bounds
self.w = options['w'] # 惯性权重
self.c1 = options['c1'] # 认知系数
self.c2 = options['c2'] # 社会系数
def _init_swarm(self):
# 如果有边界,在边界范围内初始化
if self.bounds:
min_bound, max_bound = self.bounds
self.pos = np.random.uniform(
low=min_bound,
high=max_bound,
size=(self.n_particles, self.n_dim)
)
velocity_range = np.array(max_bound) - np.array(min_bound)
self.velocity = np.random.uniform(
low=-velocity_range,
high=velocity_range,
size=(self.n_particles, self.n_dim)
) * 0.1 # 初始速度限制在较小范围
else:
# 如果没有边界,使用标准初始化
self.pos = np.random.uniform(
low=-1,
high=1,
size=(self.n_particles, self.n_dim)
)
self.velocity = np.random.uniform(
low=-0.1,
high=0.1,
size=(self.n_particles, self.n_dim)
)
# 初始化每个粒子个体的最佳位置和适应度
self.pbest_pos = self.pos.copy()
self.pbest_cost = np.full(self.n_particles, float('inf'))
# 初始化全局最佳位置和适应度
self.gbest_pos = np.zeros(self.n_dim)
self.gbest_cost = float('inf')
# 记录每次迭代的最佳适应度值
self.cost_history = []
self.pos_history = []
def reset(self):
# 重置粒子群到初始状态
self._init_swarm()
def optimize(self, objective_func, n_iters=100, verbose=False):
self.reset()
for i in tqdm(range(n_iters)):
# 计算当前粒子群的适应度值
curr_cost = np.array(objective_func(self.pos))
# 更新个体最佳
mask = curr_cost < self.pbest_cost
self.pbest_pos[mask] = self.pos[mask].copy() # 是矩阵
self.pbest_cost[mask] = self.pbest_cost[mask]
# 更新全局最佳
min_cost_idx = np.argmin(curr_cost)
if curr_cost[min_cost_idx] < self.gbest_cost:
self.gbest_cost = curr_cost[min_cost_idx]
self.gbest_pos = self.pos[min_cost_idx].copy()
# 保存历史记录
self.cost_history.append(self.gbest_cost)
self.pos_history.append(self.gbest_pos.copy())
if verbose and i % 10 == 0:
print(f'Iteration {i}: Best cost = {self.gbest_cost}')
# 更新速度和位置
r1 = np.random.random((self.n_particles, self.n_dim))
r2 = np.random.random((self.n_particles, self.n_dim))
cognitive = self.c1 * r1 * (self.pbest_pos - self.pos)
social = self.c2 * r2 * (self.gbest_pos - self.pos)
self.velocity = self.w * self.velocity + cognitive + social
self.pos = self.pos + self.velocity
# 边界处理
if self.bounds:
min_bound, max_bound = self.bounds
self.pos = np.clip(self.pos, min_bound, max_bound)
# 对于撞到边界的粒子,将其速度反向
out_of_bounds_lower = self.pos <= min_bound
out_of_bounds_upper = self.pos >= max_bound
self.velocity[out_of_bounds_lower | out_of_bounds_upper] *= -0.5
return self.gbest_cost, self.gbest_pos参数分析
惯性权重
- 使粒子保持自身运动惯性,符合现实个体行为的连续型
- 较大的惯性权重 有助于跳出局部极值,而较小的 则有利于算法收敛
加速常数 (学习因子)
- 代表个体从个体历史最优经验和当前群体趋势的学习权重
- 粒子会从个体历史最优经验和当前群体趋势学习知识
- 较低的学习因子 允许个体在被拉回之前可以在目标区域外徘徊,而较高的学习因子则会导致粒子突然冲向目标区域(甚至越过目标区域)
最大速度
- 最大速度可以限制粒子在一次迭代中的最大移动距离(在上面的代码中没有使用)
特点
- 属于仿生算法
- 属于全局优化算法
- 属于随机搜索算法
- 隐含并行性
- 根据个体的适配信息进行搜索,因此不要求目标函数具有可微性、连续型等
- 对高维复杂问题,往往会遇到早熟收敛和收敛性差的缺点
改进
变化的惯性权重:惯性权重随迭代次数的增加而减小
收敛因子模型:收敛因子模型引入了一个额外的收敛因子 ,用于调整速度更新公式。速度更新公式变为
其中,收敛因子
应用
- 神经网络训练:不需要使用梯度信息,多属性情况下训练结果优于 BP 算法,且训练速度非常快(但是高维空间中效果不好,因此不流行)
- 模糊控制、机器人路径规划等
- 组合优化
PSO 求解 TSP 问题
交换子与交换序
设 个节点的 TSP 问题的一个解序列为 ,定义交换子 为交换解 中的点 和 ,得到的新解用 表示。
- 例如,
定义交换序是一个或多个交换子的有序队列,记为 ,其中 是交换子,之间的顺序是有意义的,各个交换子依次作用于解上。
定义交换序之间的合并运算为 ,有
其中, 均为交换序,将 作用与解 上相当于 将 先作用在 上后再用 作用在解 上。因为作用相同,所以称 与 属于同一等价集。在交换序等价集中,拥有交换子的个数最少的交换序称为该等价集的基本交换序。
PSO 更新公式
其中, 是区间 上的随机数, 表示交换序, 表示路径序列(解)。
于是可以套用之前的 PSO 算法进行求解。