

语言文本的数据格式
回顾:图像的数据格式
在前两章中,我们主要探讨了一些与图像相关的机器学习任务。图像数据通常是一个三维张量 (高度、宽度、通道)。给定一张图像 ,可以形式化表示为
其中 是图像的高度, 是宽度, 是通道数。
从矩阵堆叠的角度来看,图像就是若干张形状相同的矩阵堆叠在一起
其中 是第 个通道的二维矩阵。每个二维矩阵都体现了各个像素位置在它这个通道上的信号强度。
从向量做二维排列的角度来看,图像也可以看成是 个像素点,每个像素点是一个 维的向量,它们沿着二维网格分布,聚集在一起
其中 是位于第 行、第 列的像素点的向量表示,包含了该像素在所有通道上的信号强度。
无论从哪个角度观察,图像数据都具有明确的空间结构,这是其最显著的特征。
在实际应用中最多的图像数据格式是三通道 RGB 格式,其中 R 表示红色通道,G 表示绿色通道,B 表示蓝色通道。每个通道的像素值通常在 0~255 之间,表示该像素在该颜色上的强度。
文本的数据格式
文本,本质上就是一段文字,在计算机中以字符串的形式存在。与图像不同,文本没有显然的空间结构——文本长度并不固定,而且每个字符也只有前一个字符和后一个字符两个邻居,而不是像图像像素点那样最多可以有八个邻居。
正如语言学中为了便于研究,产生了“字母”、“词根”、“词”、“句子”等不同颗粒度的概念一样,在自然语言处理 (NLP) 中,为了便于研究和计算,文本也可以有不同颗粒度的划分方式。为了便于阐述,不论哪种颗粒度的划分形式,都把文本看作是最基本单元 Token (中文叫 “词元”) 的序列。也即数学上,文本被表示成一个一维 Token 序列
其中 是文本的长度, 是文本的词汇空间, 是文本中的第 个 Token。需要注意的是,由于不同任务的需要, Token 的颗粒度是可以不同的。例如,给定一句话 T = "I love AI!",我们可以按以下不同的方式划分:
T = ["I", " ", "l", "o", "v", "e", " ", "A", "I", "!"] # 字符级划分
T = ["I", "love", "AI!"] # 词级划分但不论是何种划分方式,文本数据都具有一维序列结构,这是其本质属性。仿照图像的处理方式,让计算机分别对每个文本组成单元——也就是例如字符或者单词的 Token——进行处理,是不是就能完成文本理解和生成的任务了呢?
事实上,这很困难。这是因为直接对字符组合(单词或者字符)进行处理,会面临一个无法计算的问题——Token 本身是不可计算的,它不像图像那样是数值的组合。我们无法直接对 Token 进行加减乘除或者内积等数学运算。
举个例子,你不能拿 "l" 加上 "o" 期望得到 "v",也不能计算 "I" 与 "AI" 之间的欧氏距离。缺乏了数值计算,机器学习的方法也就无法直接应用了。
此外,文本作为字符串本身,并非是直接切分好的 Token 序列。这里是为了阐述方便,直接默认文本是切分好了的。实际上,切分的操作需要基于一定的规则来完成,这是下面介绍的分词器的工作。
分词 (Tokenization) 与词嵌入 (Word Embedding)
既然 Token 本身不可计算,那么要让计算机处理文本,首先就必须解决可计算的核心问题,即如何将离散的 Token 序列转化为可供数学运算的数值形式?
参考图像分类的最后两步,特征向量经过线性层得到了每个类别的置信分数,然后选置信分数高的为预测的类别,类别都是用离散的整数表示,但是经过字典的映射可以变为类别本身的字符串。这一步可以看作是从特征向量到整数再到字符串的变换过程。
那反其道而行之,倒着设计文本数据的处理流程:首先将 Token 转化为整数 ID,然后再通过一个可学习的查找表将整数 ID 转化为稠密的向量表示。事实上,现代的自然语言处理都是这么干的。这个过程分为两个步骤:
- 分词 (Tokenization):将文本拆分为 Tokens。Token 的颗粒度由分词算法决定,可能等于一个完整的词,也可能是一个词的片段 (子词),甚至是一个单独的字符。目前主流的子词级分词算法包括 Byte Pair Encoding (BPE,字节对编码) 及其变体 Byte-level BPE (BBPE,字节级字节对编码)。它们通过统计语料中字符或字节的共现频率,迭代地合并高频相邻对,从而在词表大小和序列长度之间取得平衡。
- 词嵌入 (Word Embedding):将每个 Token ID 映射为一个高维的稠密向量。这一映射通过一个可训练的嵌入矩阵实现——Token ID 作为索引,从矩阵中取出对应的向量行。在训练过程中,这些向量会通过反向传播不断调整,最终使得语义相近的 Token 在向量空间中彼此靠近。
通过分词和词嵌入,我们就完成了文本数据从离散的符号序列到连续的数值张量的转变。最终得到的文本数据格式是一个形状为 的二维张量
其中 是文本的长度, 是嵌入向量的维度。这就成为了神经网络模型可以直接处理的输入格式。
在 NLP 术语描述中,Token 的本义是文本的最小组成单元,但是为了便于表达,有的时候 Token 也可以泛指经过分词操作之后的 Token ID 或者 Token 的嵌入向量。
分词器 (Tokenizer) 的实现——以 BPE 为例
Byte Pair Encoding (BPE) 的核心思想可以概括为:从字符级词表出发,通过反复合并语料中出现频率最高的相邻符号对,逐步构造出更大的子词单元。定义词表 (Vocabulary) 是模型所“认识”的全部 Token 构成的有限集合,本质是一张从 Token 到整数 ID 的映射表。在 BPE 中,词表 分为子词词表 和预定义的特殊标记(如 <PAD>、<UNK>)词表 两个部分构成
BPE 的算法原理
子词词表 是通过以下迭代过程构建的:
假设构建过程中,当前子词词表为 ,语料中所有相邻符号对构成的集合为 ,定义任意相邻对 在语料中的共现频次为 。BPE 的每一轮迭代执行以下操作:
- 找出频次最高的相邻对:
- 将 合并为一个新符号 ,并加入词表 。
- 在语料中将所有相邻出现的 和 替换为 ,更新 中的频次统计。
重复上述过程 次( 为目标词表大小减去初始字符数),最终得到一个包含子词单元的词表及对应的合并规则序列。
特殊标记的设计
除了从语料中学习到的子词单元,分词器通常还需要预先定义一组特殊标记 (Special Tokens)。这些标记并不来自语料的统计合并,而是服务于模型训练和推理过程中的工程需求。常见的特殊标记包括如下这些:
| 标记符号 | 全称与含义 | 用途 |
|---|---|---|
<PAD> | Padding Token | 填充标记。由于同一批次内的文本序列长度不一,需将较短序列填充至统一长度 ,填充位置用 <PAD> 占据,并在后续注意力计算中通过掩码忽略。 |
<UNK> | Unknown Token | 未知词标记。当分词器遇到词表中不存在的字符或子词组合时,统一映射为 <UNK>,防止因集外词导致的索引越界。 |
<BOS> | Beginning of Sequence | 序列起始标记。置于输入序列的首位,提示模型序列的开始。在生成任务(如文本续写、翻译解码)中常作为第一个输入 token。 |
<EOS> | End of Sequence | 序列结束标记。置于序列末尾,用于指示生成过程的终止条件,模型在预测到 <EOS> 时停止输出。 |
<SEP> | Separator Token | 分隔标记。常用于需要区分多个句子的任务(如 BERT 的下一句预测),置于两个句子之间。 |
<CLS> | Classification Token | 分类标记。通常置于序列首位,其对应的最终隐状态被用作整段文本的聚合表示,输入分类层。 |
分词器在编码阶段会为每个特殊标记预留固定的整数 ID(通常从 0 开始连续分配),并在解码时将其映射回对应的标记字符串或忽略(例如 <PAD> 不出现在最终输出文本中)。
特殊标记的 ID 分配顺序虽无硬性规定,但常见实践是将其置于词表最前端,以保证:
- 索引稳定:不同训练轮次或不同语料下,特殊标记的 ID 保持不变,方便模型权重的迁移与复用。
- 掩码便利:
<PAD>的 ID 常设为 0,使得注意力掩码可通过判断输入是否为 0 快速生成。
以下代码实现中,我们显式地将 <UNK>、<PAD>、<BOS>、<EOS> 作为基础特殊标记加入词表,并在后续的 encode 和 decode 方法中正确处理它们。
BPE 分词器的代码实现
首先用代码实现一个简单的 BPE 分词器,包含训练和编码解码功能:
import re
from collections import defaultdict, Counter
from typing import List, Tuple, Dict, Optional
from tqdm import tqdm
class BPETokenizer:
"""Byte Pair Encoding (BPE) 分词器"""
def __init__(self, vocab_size: int = 1000, unk_token: str = "<UNK>"):
"""
Args:
vocab_size: 目标词表大小(包含所有基础字符和特殊标记)
unk_token: 未知词标记
"""
self.vocab_size = vocab_size
self.unk_token = unk_token
self.merges: Dict[Tuple[str, str], str] = {} # 合并规则:(a, b) -> ab
self.vocab: Dict[str, int] = {} # 词表:token -> id
def _prepare_corpus(self, texts: List[str]) -> Dict[Tuple[str, ...], int]:
"""将语料中的每个单词拆分为字符组元组,并利用 Counter 提前聚合词频,极大节省内存和时间"""
word_freqs = Counter()
for text in texts:
words = re.findall(r"\w+|[^\w\s]", text)
for word in words:
word_freqs[word] += 1
# 转换为带权重字典: {('l', 'o', 'v', 'e', '</w>'): 150}
corpus = {}
for word, freq in word_freqs.items():
chars = tuple(list(word) + ["</w>"])
corpus[chars] = freq
return corpus
def _get_stats(self, corpus: Dict[Tuple[str, ...], int]) -> Dict[Tuple[str, str], int]:
"""统计字典中相邻符号对的频次 (需乘上该词的全局权重频次)"""
pairs = defaultdict(int)
for word_tuple, freq in corpus.items():
for i in range(len(word_tuple) - 1):
pairs[(word_tuple[i], word_tuple[i + 1])] += freq
return pairs
def _merge_pair(self, corpus: Dict[Tuple[str, ...], int], pair: Tuple[str, str]) -> Dict[Tuple[str, ...], int]:
"""在去重汇总后的字典词表上合并对,而不是重新创建一千万个列表"""
a, b = pair
new_corpus = {}
for word_tuple, freq in corpus.items():
# 这里如果单词里没包含待合并的字符,直接放过去
if a not in word_tuple or b not in word_tuple:
new_corpus[word_tuple] = freq
continue
new_word = []
i = 0
while i < len(word_tuple):
if i < len(word_tuple) - 1 and word_tuple[i] == a and word_tuple[i + 1] == b:
new_word.append(a + b) # 合并
i += 2
else:
new_word.append(word_tuple[i])
i += 1
new_corpus[tuple(new_word)] = freq
return new_corpus
def train(self, texts: List[str], verbose: bool = False):
"""
在给定文本上训练 BPE 分词器
"""
# 1. 准备语料:每个单词拆分为字符序列
if verbose:
print("正在将语料拆分为字符序列并全局聚合词频...")
iterator = tqdm(texts, desc="预处理与聚合语料")
else:
iterator = texts
corpus = self._prepare_corpus(iterator)
if verbose:
print(f"数据聚合完毕!去重后的独立词元数量: {len(corpus)}")
# 2. 初始化词表:所有基础字符(含 </w>)
base_vocab = set()
for word_tuple in corpus.keys():
base_vocab.update(word_tuple)
# 将特殊标记排在词表最前面(索引 0, 1, 2, 3...)
special_tokens = [self.unk_token, "<PAD>", "<BOS>", "<EOS>"]
final_vocab = list(special_tokens)
# 加上语料中的基础字符(去重后排序)
base_chars = sorted([char for char in base_vocab if char not in special_tokens])
final_vocab.extend(base_chars)
self.vocab = {tok: i for i, tok in enumerate(final_vocab)}
if verbose:
print(f"初始词表大小: {len(self.vocab)}")
# 3. 迭代合并
num_merges = self.vocab_size - len(self.vocab)
if num_merges <= 0:
print(f"\n[Warning] 设定的 vocab_size ({self.vocab_size}) 小于或等于抽取出的基础字符表大小 ({len(self.vocab)})。")
print("[Warning] 由于中文字符丰富以及特殊符号极多,基础字符数轻易破万。建议指定更大的 vocab_size (例如 20000 或 50000)!当前将跳过字符合并操作。")
num_merges = 0
if num_merges > 0:
iterator = tqdm(range(num_merges), desc="训练 BPE 合并规则") if verbose else range(num_merges)
for i in iterator:
pairs = self._get_stats(corpus)
if not pairs:
break
best_pair = max(pairs, key=pairs.get) # 频次最高的相邻对
corpus = self._merge_pair(corpus, best_pair)
# 记录合并规则和更新词表
new_token = best_pair[0] + best_pair[1]
self.merges[best_pair] = new_token
self.vocab[new_token] = len(self.vocab)
if verbose:
# 使用 tqdm 时,通过 set_postfix 动态更新当前进度信息,避免原先 print 导致的一直刷屏
if hasattr(iterator, 'set_postfix'):
iterator.set_postfix({'merging': f"{best_pair[0]}+{best_pair[1]}", 'freq': pairs[best_pair]})
elif (i + 1) % 100 == 0:
print(f"合并 {i + 1}/{num_merges}: {best_pair} -> {new_token}, 频次: {pairs[best_pair]}")
if verbose:
print(f"训练完成,最终词表大小: {len(self.vocab)}")
def tokenize(self, text: str) -> List[str]:
"""将文本分词为 token 序列"""
# 预处理:按单词拆分并转为字符序列(加 </w>)
words = re.findall(r"\w+|[^\w\s]", text)
tokens = []
for word in words:
chars = list(word) + ["</w>"]
# 反复应用合并规则,直到无法再合并
while len(chars) > 1:
# 找到当前序列中在合并规则里优先级最高的相邻对
# 规则按照训练时的顺序(即频次高低)应用
min_index = float("inf")
target_pair = None
for pair in self.merges:
for i in range(len(chars) - 1):
if chars[i] == pair[0] and chars[i + 1] == pair[1]:
# 因为规则是按频次高低顺序存储的(Python 3.7+ dict 保持插入顺序)
# 所以第一次遇到的就是最高优先级的
if i < min_index:
min_index = i
target_pair = pair
if target_pair is None:
break
# 合并找到的 pair
a, b = target_pair
i = min_index
chars = chars[:i] + [a + b] + chars[i + 2:]
# 去掉单词结束符,但保留为独立的 token(常规 BPE 会将 </w> 作为词边界标记)
# 这里直接将 </w> 保留在 token 中,例如 "love</w>" 表示单词 love
tokens.extend(chars)
# 处理未知字符(简单起见,此实现中基础字符已覆盖所有输入,故省略 UNK 逻辑)
return tokens
def encode(self, text: str) -> List[int]:
"""将文本编码为 token ID 序列"""
tokens = self.tokenize(text)
return [self.vocab.get(tok, self.vocab[self.unk_token]) for tok in tokens]
def decode(self, ids: List[int]) -> str:
"""将 token ID 序列解码为原始文本"""
id_to_token = {v: k for k, v in self.vocab.items()}
tokens = [id_to_token.get(i, self.unk_token) for i in ids]
# 拼接 tokens,移除 </w> 并替换为空格
text = ""
for tok in tokens:
if tok.endswith("</w>"):
text += tok[:-4] + " "
else:
text += tok
return text.strip()
def save(self, path: str):
"""保存分词器(合并规则和词表)"""
import json
with open(path, "w", encoding="utf-8") as f:
json.dump({
"vocab_size": self.vocab_size,
"unk_token": self.unk_token,
"merges": {f"{k[0]} {k[1]}": v for k, v in self.merges.items()},
"vocab": self.vocab
}, f, ensure_ascii=False, indent=2)
def load(self, path: str):
"""加载分词器"""
import json
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
self.vocab_size = data["vocab_size"]
self.unk_token = data["unk_token"]
self.merges = {tuple(k.split()): v for k, v in data["merges"].items()}
self.vocab = data["vocab"]为了训练这个 BPE 分词器,我们需要准备一些文本数据。这里选择一下几个数据集
训练的接口如下所示:
# 创建并训练 BPE 分词器
tokenizer = BPETokenizer(vocab_size=args.vocab_size, unk_token="<UNK>")
tokenizer.train(corpus, verbose=True) # corpus 是一个文本列表,例如 ["I love AI!", "BPE is great!"]
# 测试分词器
text = "I love AI!"
tokens = tokenizer.tokenize(text) # 分词列表
ids = tokenizer.encode(text) # 编码为 token ID 列表
decoded = tokenizer.decode(ids) # 解码回原始文本(可能与输入略有不同,取决于分词规则)具体训练代码可以参考 codes/train_tokenizer.py,需要注意的是这个代码会一次性加载整个语料到内存中,如果计算机内存较小,可能会导致 OOM (内存溢出),从而导致死机。请谨慎运行,可以选择合适的语料规模。下面是训练一个小型 BPE 分词器的命令示例:
python train_tokenizer.py \
--data_root "data/corpus" \
--datasets translation2019zh baike2018qa news2016zh \
--vocab_size 5000 \
--num_train_samples 10000 \
--save_path "models/tokenizer/mixed_bpe_tokenizer.json"工业级分词器训练 (HuggingFace tokenizers)
在真实的工业场景下,为了更加内存友好且高效地训练分词器,通常借助底层为 Rust 编写的高性能库 tokenizers 以实现对分词器的流式训练。这个库的优点包括:
- 效率:Rust 的性能优势使得分词器训练速度大幅提升,能够处理大规模语料。
- 内存友好:支持从数据生成器流式加载文本,避免一次性将整个语料加载到内存中导致 OOM。
- 功能丰富:提供了多种预定义的分词模型(如 BPE、WordPiece、Unigram)和灵活的特殊标记配置,满足不同任务需求。
- 易用性:Python 接口简洁,易于集成到现有的 NLP 工作流中,且属于 Huggingface 生态系统的一部分,与 Transformers 库无缝兼容。
Huggingface 是一个专注于自然语言处理与机器学习的开源平台和社区,以其核心库 Transformers 最为知名,提供了大量预训练模型(如BERT、GPT等)、数据集以及模型训练、评估和部署的工具,极大降低了开发者构建和应用先进NLP模型的门槛;同时,它还通过模型Hub和Spaces等功能,促进了全球开发者之间的模型共享与协作,已成为现代AI开发不可或缺的基础设施之一。
安装 Huggingface 生态系统中主要的环境依赖可以使用如下 pip 命令:
pip install transformers datasets accelerate peft evaluate tokenizers sentencepiece
pip install -U huggingface_hub # 安装 Huggingface Hub 客户端库(可选,用于模型和数据集的上传下载)由于在中国大陆地区无法直接访问 Huggingface 的官方资源,通常的做法是使用国内的镜像网站——HF Mirror,来访问 Huggingface 的模型和数据集资源。下载数据集或者模型前,可以预先设置环境变量
# Linux / MacOS
export HF_ENDPOINT=https://hf-mirror.com
# Windows PowerShell
$env:HF_ENDPOINT = "https://hf-mirror.com"以下是 tokenizers 库的接口实例:
from tokenizers import Tokenizer, models, pre_tokenizers, decoders, trainers
# 1. 定义底层模型为 BPE
tokenizer = Tokenizer(models.BPE(unk_token="<UNK>"))
# 2. 配置预分词器与解码器 (例如使用大模型常用的 ByteLevel 字节级切分)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
tokenizer.decoder = decoders.ByteLevel()
# 3. 配置训练器 (设置工业级词表大小与需要的特殊标记)
trainer = trainers.BpeTrainer(
vocab_size=50000,
show_progress=True,
special_tokens=["<PAD>", "<UNK>", "<BOS>", "<EOS>", "<SEP>", "<CLS>"]
)
# 4. 极为关键的一步:从数据生成器流式(Stream)训练
# 这样能够源源不断地从硬盘加载文本进入 Rust 引擎,避免 OOM (内存溢出)
tokenizer.train_from_iterator(batch_iterator(train_ds, batch_size=20000), trainer=trainer)
# 5. 训练结束,保存词表
tokenizer.save("industrial_bpe_tokenizer.json")
# 真实的使用测试
encoded = tokenizer.encode("AI is changing the world.")
print(f"Token IDs: {encoded.ids}")
print(f"切分片段: {encoded.tokens}")具体训练代码可以参考 codes/train_tokenizer_hf.py,使用下列命令可以训练一个工业级的 BPE 分词器:
python train_tokenizer_hf.py \
--data_root "data/corpus" \
--datasets wiki2019zh news2016zh baike2018qa webtext2019zh translation2019zh \
--vocab_size 30000 \
--save_path "models/tokenizer/my_bert_tokenizer.json"后续的语言模型训练我们会采用 Huggingface 提供的预训练的分词器。
分词器的结果
完成对分词器的训练后,我们会得到一个词汇表(Vocabulary) 和对文本做切分的规则 。词汇表收录了模型能够识别和处理的所有 token,并为每个 token 分配一个唯一的整数编号(ID)。形式化地,词汇表确定了一个从 token 到整数 ID 的双射映射
其中 代表词表大小。示例如下:
vocab = {
"[PAD]": 0, # 填充标记,用于将不等长序列对齐
"[UNK]": 1, # 未知词标记,处理未收录词
"[CLS]": 2, # 序列起始标记(常用于分类任务)
"[SEP]": 3, # 分隔标记(常用于分隔两个句子)
"I": 4,
"love": 5,
"AI": 6,
"!": 7,
...
}如果是使用前面实现的 BPETokenizer,可以用 tokenizer.vocab 属性查看训练好的词汇表内容字典。
如果是使用 Hugging Face 的工业级 tokenizers.Tokenizer,可以通过调用 get_vocab() 等方法来操作词表内容:
# 获取完整的词汇表字典 (Token -> ID)
hf_vocab = tokenizer.get_vocab()
# 获取词表大小
print(f"词汇表大小: {tokenizer.get_vocab_size()}")
# 双向映射查询
print(f"'AI' 对应的 ID: {tokenizer.token_to_id('AI')}")
print(f"最开始的 ID (例如 0) 对应的 Token: {tokenizer.id_to_token(0)}")有了分词器后,我们就可以将文本数据转化为整数 ID 序列了。这个过程我们用数学形式化表示为
- 分词
- 映射为整数 ID
其中 表示整数的 N 维向量空间。每个文本中的 token 都被映射为一个整数 ID,这些 ID 就是模型可以直接处理的数值输入了。需要注意的是,分词器的设计和训练质量直接影响到后续模型的性能,因为它决定了文本数据的基本表示形式。
词嵌入层 (Embedding Layer)
词嵌入层的作用是为了解决整数 ID 的两个缺陷:
- 整数之间的大小关系(例如 5 > 4)并不代表任何语义上的远近或重要性差异;
- 单个整数所能表达的信息容量极为有限。
词嵌入层的核心是一张巨大的可训练查询表——嵌入矩阵
其中 是嵌入向量的维度(例如 512、768 或 4096), 表示第 个 token 的嵌入向量。对于输入序列 中的每一个整数 ID ,嵌入层所做的操作就是“查表”
例如,ID 为 5 的 token "love" 会被映射为一个 维的实数向量。这个向量的每一个分量在训练开始时是随机初始化的,但随着模型在任务数据上的不断训练,这些向量的数值会通过反向传播算法被逐步调整。调整的目标是让语义上相近的词(如 "love" 与 "like")在向量空间中彼此靠近,而语义无关的词则相互远离。
这就是 词嵌入 的核心思想,将离散的 token 映射为连续向量空间中的点,用向量之间的几何关系(距离、角度)来编码词汇之间的语义和语法关系。著名的例子有
通过词嵌入层,文本数据最终完成从“不可计算的符号序列”到“可微分的数值张量”的关键蜕变。整段文本被表示为一个形状为 的二维矩阵,形式化表示为
词嵌入层可以在 PyTorch 中通过 nn.Embedding 模块实现
embedding_layer = nn.Embedding(num_embeddings=len(vocab), embedding_dim=d)文本翻译——序列到序列的建模 (seq2seq)
文本翻译是自然语言处理领域的一个经典任务,属于序列到序列 (seq2seq) 建模范畴,目标是将一种语言的文本转换为另一种语言的文本。这个任务不仅要求模型理解输入文本的语义,还需要生成符合目标语言语法和习惯的输出文本。
数学上,文本翻译就是建立从一种语言的词汇空间到另一种语言的词汇空间的映射关系,完成文本序列之间的转换,即学习一个映射
其中 和 分别是源语言和目标语言的词汇空间, 和 是输入和输出文本的长度; 是输入文本字符序列, 是输出文本字符序列。模型需要学习在不同语言之间捕捉语义对应关系,并生成流畅自然的翻译结果。
根据前面的离散文本到连续张量的转变,我们可以将文本翻译任务转化为学习一个从源语言文本的嵌入张量到输出目标语言文本的嵌入张量的映射
注: 在许多文献中,嵌入维度 都表示成 或者 以便于区分。本文在公式中选择 的简洁表示,但在实际代码中会采用 的描述形式。
注意力机制
文本翻译实际上并非是简单词对词的翻译,需要考虑到句子中间很复杂的依赖关系。例如
- 中文:他做事总是三天打鱼,两天晒网。
- 英文直译:He always fishes for three days and dries the net for two days.
- 英文意译:He is very inconsistent in his work. 这个翻译的例子就很好地说明了文本翻译的复杂性,英文中的 “inconsistent” 这个词并没有在中文原文中出现过,而是模型通过对整个句子语义的理解,推断出一个更符合英文表达习惯的翻译结果。
这种依赖关系不是简单词与词之间的对应,也不是简单的只与当前词汇往前的几个词汇相关,而是每个词都可能与输入序列中的任意一个词相关。因此,文本翻译需要一个能够捕捉全局依赖关系的机制。
基于此,注意力机制 (Attention Mechanism) 被提出了。它允许模型在生成每个输出词时,动态地“关注”输入序列中的不同部分,从而捕捉到全局的依赖关系。这种机制极大地提升了文本翻译的质量,使得模型能够生成更自然、更准确的翻译结果。
数学模型
注意力机制的核心思想是,句子中的每个词,都可以直接与句子中的所有其他词进行交互,“注意到”那些与自己相关的部分。
Q、K、V 模型
注意力机制借用了数据库检索的概念:
- 查询张量(Query, 或 ):当前正在寻找相关信息的词(我该关注谁?)。
- 键张量(Key, ):被考察的词(我包含什么信息?)。
- 值张量(Value, ):被考察词的实际内容(如果你关注我,我就把这段信息给你)。
从张量形状的角度看, 是输入序列的长度, 和 是键和值的维度。这表明,对于每一个 token,我们都为它生成了一个 维度的查询向量、一个 维度的键向量和一个 维度的值向量。
根据网络构建目的的不同,注意力机制主要有两种模式,分别是自注意力(Self-Attention) 和 交叉注意力(Cross-Attention)。这两种注意力机制的 、、 特征向量的来源不同:
对于自注意力(Self-Attention),、、 都来自同一个输入序列 :
其中 是模型自动学习的权重矩阵。
对于交叉注意力(Cross-Attention), 来自一个序列(例如目标语言的输入),而 和 来自另一个序列(例如源语言的输入):
其中 是目标输入序列, 是源输入序列, 是模型自动学习的权重矩阵。
缩放点积注意力(Scaled Dot-Product Attention)
注意力机制的目标是为了提取出一整个序列关于某一个 token 的信息。为了衡量信息的相关性,这里采用了点积的方式。有了特征张量 和 后,依次计算它们各个 tokens 之间的点积。点积结果越大,说明两个 tokens 越相关,也称作注意力得分越高。
单个点积的计算如下(这里把 的向量看作是行向量)
其中 是查询张量 中的第 个 token 的查询向量, 是键张量 中的第 个 token 的键向量。通过计算所有 与所有 的点积组合,我们可以得到一个注意力得分矩阵
为了方便统一相似性度量的尺度,需要沿着键张量的序列长度维度 做 Softmax 归一化,将得分转换为概率分布(每个查询 token 都会有一个概率分布),表示键张量对应序列中的每个 token 对当前查询 token 的关注程度:
然而,随着 的增加,点积的结果可能会变得非常大,这会导致 Softmax 函数的容易出现梯度消失。为了解决这个问题,我们对点积结果进行缩放,除以 ,从而得到缩放点积注意力的计算公式
缩放点积注意力的本质是关于值张量 的权重,加权求和,就是最终的注意力结果
缩放点积注意力的 PyTorch 实现
PyTorch 实现核心缩放点积注意力
def scaled_dot_product_attention(q, k, v, mask=None):
d_k = q.size(-1)
# 1. 计算未缩放的分数 q * k^\top
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
# 2. 如果存在掩码,将特定位置屏蔽,从而不参与注意力计算(后续会解释这步操作)
if mask is not None:
scores = scores.masked_fill(mask == False, -1e9)
# 3. Softmax 归一化
attention_weights = F.softmax(scores, dim=-1)
# 4. 加权求和 Value
output = torch.matmul(attention_weights, v)
return output, attention_weights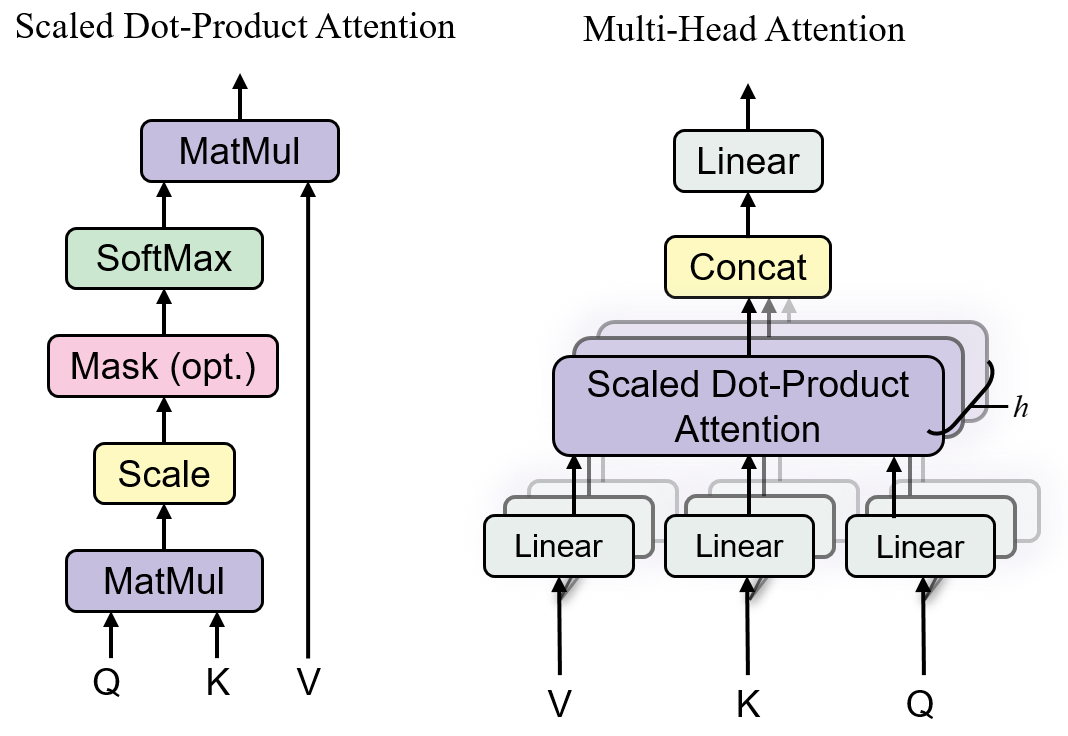
多头注意力(Multi-Head Attention)
为了让模型能从多个不同的“角度”去观察词与词间的关系,通常会将输入拆分成多个并行的“头”(Heads)来计算上述 Attention,然后将结果拼接在一起。
这里的头可以理解为模型关注的不同的特征领域,每个头都有自己独立的查询、键、值的权重矩阵。通过多头注意力,模型能够捕捉到输入序列中不同层次、不同类型的依赖关系,从而提升模型的表达能力和性能。
打个比方,使用多头注意力后,有的头可能专注于捕捉语法关系(如主谓宾),有的头可能专注于捕捉语义关系(如同义词),还有的头可能专注于捕捉长距离依赖(如跨句子关系)。通过这种方式,模型能够更全面地理解输入文本的结构和意义,从而生成更准确、更自然的翻译结果。
不论是自注意力机制还是交叉注意力机制,都可以封装成下面的 MultiHeadAttention 层
class MultiHeadAttention(nn.Module):
"""多头注意力模块"""
def __init__(self, d_model: int, n_heads: int, dropout: float = 0.1):
super().__init__()
assert d_model % n_heads == 0, "d_model must be divisible by n_heads"
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def _split_heads(self, x):
"""将最后一维拆分为 (n_heads, d_k),并转置为 (batch, n_heads, seq_len, d_k)"""
batch, seq_len, _ = x.shape
x = x.view(batch, seq_len, self.n_heads, self.d_k)
return x.transpose(1, 2) # (batch, n_heads, seq_len, d_k)
def _combine_heads(self, x):
"""合并头,形状 (batch, seq_len, d_model)"""
batch, n_heads, seq_len, d_k = x.shape
x = x.transpose(1, 2).contiguous()
return x.view(batch, seq_len, self.d_model)
def forward(self, q, k, v, mask=None):
"""
q, k, v: (batch, seq_len_q/k/v, d_model)
mask: 可选,形状 (batch, 1, seq_len_q, seq_len_k) 或可广播的形状
"""
# 线性变换并分头
Q = self._split_heads(self.W_q(q))
K = self._split_heads(self.W_k(k))
V = self._split_heads(self.W_v(v))
# 计算注意力
attn_output, _ = scaled_dot_product_attention(Q, K, V, mask=mask)
attn_output = self.dropout(attn_output)
# 合并头并输出
output = self._combine_heads(attn_output)
output = self.W_o(output)
return outputTransformer 模型
Transformer 模型是同时集成了多头自注意力机制和多头交叉注意力机制的架构。它由编码器 (Encoder) 和解码器 (Decoder) 两部分组成,分别负责处理输入文本和生成输出文本。
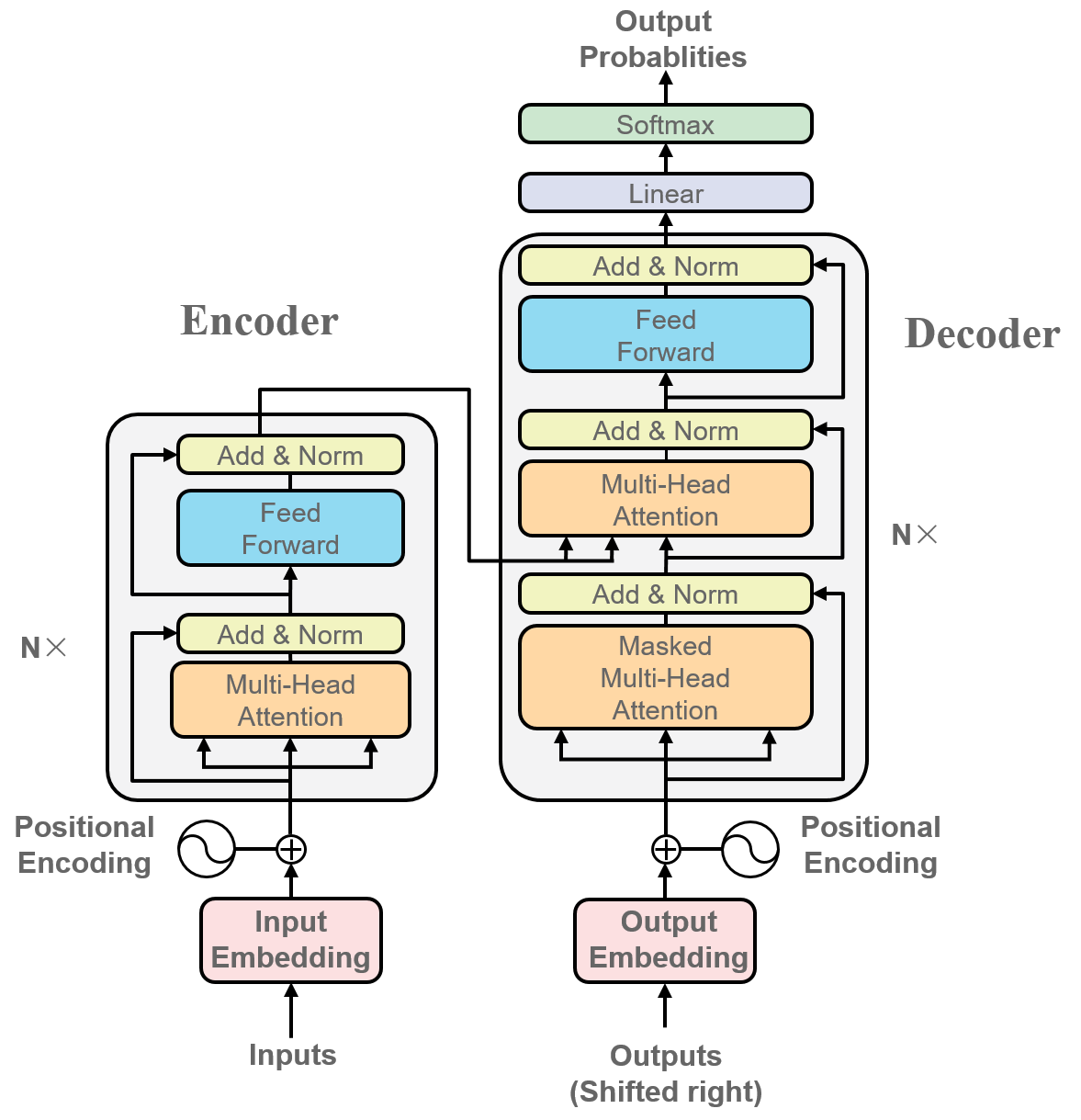
如图所示,Transformer 的编码器由多个相同的层堆叠而成,每层包含一个多头自注意力机制和一个前馈神经网络 (Feed-Forward Network)。解码器也由多个相同的层堆叠而成,每层包含一个多头自注意力机制、一个多头交叉注意力机制和一个前馈神经网络。
简单来说,编码器的经过逐层自注意力机制处理,就像图像中的全连接网络一样,感受野本身就是全局的。即使是编码器输出序列中的一个 token,它都是捕捉了输入序列中所有 token 的信息的。正因如此,编码器输出的序列被叫作全局上下文中间表示(Global Contextual Representation),数学符号记作 。全局上下文中间表示会在解码器中被当作键和值输入序列,用于交叉注意力的计算。
编码器的序列处理是一层一层的把整个序列进行加工,这和图像卷积层的逐层加工非常类似的。但是解码器的处理就很不一样了。解码器并不是一次性地输出最终的翻译序列结果,而是自回归式地一个 token 一个 token 地生成翻译结果的。
自回归式的处理,意思就是给定一个半成品序列 (下标表示左闭右开) ,解码器需要结合这个半成品序列和编码器输出的全局上下文中间表示,去预测下一个 token 的概率分布 。根据概率分布选择最合适的 token 作为 的输出 (通常是从分布中采样或者选择概率值最大的那个 token),然后将 添加到半成品序列中,重复操作,继续预测下一个 token ,直到生成完整的翻译结果。
对比之下,编码器一次性就完成计算了,而解码器需要反复迭代生成结果。
讲完了 Transformer 编码器和解码器的整体工作原理后,接下来需要细细探讨它的各层的具体实现。
输入序列的文本嵌入 (Text Embeddings) 和位置编码 (Positional Encoding)
Transformer 模型本身不包含任何循环或卷积结构,因此它无法天然感知序列中 token 的顺序信息,这一点从注意力结果的序列次序可交换性上可以看出来。但是,位置关系在语言建模中是相当重要的,一个简单的例子就足以体现
- 文本 1: “我爱自然语言处理”
- 文本 2: “自然语言处理爱我” 这两句话的 tokens 是完全一样的,但是它们的语义是完全不同的,这就是位置关系导致的差异。
为了让模型能够利用 token 在序列中的位置关系,我们必须在输入端显式地注入位置信息。具体做法是,将 文本嵌入 与 位置编码 相加,作为编码器和解码器真正的输入。其中位置编码必须要能体现出不同位置的区别。
数学描述上,位置编码的目标是为每个绝对位置 (, 为序列长度)生成一个 维向量,使得模型能够区分不同位置的 token。有两种常见的设计方案:
1. 正余弦型位置编码 (Sinusoidal Positional Encoding)
其中 表示位置在 处的 token 的,在文本嵌入向量的第 个维度上的位置编码。这种设计的优点包括:
- 每个位置的编码是唯一的;
- 对于任意固定的偏移量 , 可以表示为 的线性函数,这有助于模型学习相对位置信息;
- 值域在 之间,与文本嵌入相加时不会造成数值不稳定。
最后,将文本嵌入与位置编码按元素相加,得到编码器和解码器的真正输入:
PyTorch 实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, max_len: int = 5000):
super().__init__()
# 预计算所有位置的位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
# 计算分母项 10000^(2i/d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数索引使用 sin,奇数索引使用 cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 增加 batch 维度方便广播,形状 (1, max_len, d_model)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x 形状: (batch_size, seq_len, d_model)
return x + self.pe[:, :x.size(1), :]
# 示例:生成一个 batch 的输入嵌入并加上位置编码
batch_size, seq_len, d_model = 2, 10, 512
embedding = nn.Embedding(num_embeddings=10000, embedding_dim=d_model)
x_ids = torch.randint(0, 10000, (batch_size, seq_len))
x_emb = embedding(x_ids) # 文本嵌入
pos_enc = PositionalEncoding(d_model)
x_input = pos_enc(x_emb) # 最终输入2. 旋转位置编码 (Rotary Position Embedding, RoPE)
正弦余弦位置编码直接将位置向量加到嵌入上,而 RoPE 采用了一种不同的思路——将位置信息通过旋转矩阵融入 query 和 key 向量中,使得注意力分数天然依赖于 token 之间的相对位置。
对于序列中第 , 个位置的 token,其对应的 query 向量 和 key 向量 不直接加上位置编码,而是乘以一个与位置 相关的旋转矩阵
其中 是未经过位置编码的原始 query/key 向量(来自文本嵌入的线性变换), 是旋转矩阵。旋转矩阵具有性质
因此,两个旋转后的向量的内积为
这表明 注意力分数仅依赖于相对位置 ,而不是绝对位置 和 ,这是 RoPE 能够很好地外推到更长序列的关键。
为了高效实现,RoPE 通常将 维向量拆分成 个二维子空间,每个子空间独立旋转。对于第 个子空间(),旋转角度为
于是位置 的旋转矩阵为
实际计算时不需要构造完整的稀疏矩阵,而是利用复数乘法高效实现。将二维向量视为复数 ,乘以旋转因子 即可完成旋转。
RoPE 的优点包括:
- 相对位置依赖:注意力分数直接由相对距离决定,更符合自然语言的局部性假设。
- 长序列外推能力:训练时未见过的长度,在推理时仍能保持较好的性能,而正弦余弦编码的外推能力较弱。
- 不改变向量模长:旋转是正交变换,不会缩放向量,保持数值稳定。
PyTorch 实现
def rotate_half(x):
"""将输入的后一半维度旋转到前一半的负位置"""
x1, x2 = x.chunk(2, dim=-1)
return torch.cat([-x2, x1], dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin):
"""
通用 RoPE 应用函数
q, k: (batch, n_heads, seq_len, d_k)
cos, sin: (1, 1, seq_len, d_k)
"""
# 确保 cos 和 sin 的维度与 q 匹配(截断到当前序列长度)
seq_len = q.shape[2]
cos = cos[:, :, :seq_len, :]
sin = sin[:, :, :seq_len, :]
# 旋转公式: q_rotated = (q * cos) + (rotate_half(q) * sin)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
class Model(nn.Module):
def __init__(self, ...):
super().__init__()
pass
def get_rotary_emb(self, seq_len, device):
"""
计算旋转位置编码的 cos 和 sin 缓存向量
Args:
seq_len: 当前输入的序列长度
device: 张量所在设备
Returns:
cos, sin: 形状为 (1, 1, seq_len, d_k) 的旋转向量
"""
t = torch.arange(seq_len, device=device).float()
freqs = torch.outer(t, self.inv_freq) # (seq_len, d_k/2)
# 核心逻辑:这里为了配合 rotate_half 中的 chunk(2, dim=-1) 操作,
# 我们需要构造一个对称的角度序列 [theta_0, ..., theta_{d_k/2-1}, theta_0, ..., theta_{d_k/2-1}]
# 这样在 apply_rotary_pos_emb 中,每一对 (x1, x2) 都会乘以相同的旋转频率
emb = torch.cat([freqs, freqs], dim=-1) # (seq_len, d_k)
# 整理形状以适配多头注意力:(batch, n_heads, seq_len, d_k)
cos = emb.cos().view(1, 1, seq_len, self.d_k)
sin = emb.sin().view(1, 1, seq_len, self.d_k)
return cos, sin还需注意的一点是,当引入多头注意力机制后,RoPE 位置编码的维度就不再是 ,而是每个头的维度 了,需要注意调整。
在实际应用中,如果任务序列长度固定且较短(如机器翻译),正弦余弦编码足够;如果需要处理超长上下文或要求更好的外推性,RoPE 是更优选择。
注意力掩码 (Attention Mask)
在实际训练和推理中,我们需要控制注意力机制能看到哪些位置。掩码(Mask)是一个与注意力得分矩阵形状相同(或可广播)的布尔矩阵,用于屏蔽某些位置的注意力分数(通常将屏蔽位置设为 ,使其 Softmax 权重为 0)。
主要有两类掩码:
1. 填充掩码 (Padding Mask)
由于批次内序列长度不一,较短的序列会用 <PAD> token 填充至统一长度。这些填充位置不应参与注意力计算,否则模型会学到无意义的模式。
填充掩码通常是一个形状为 (batch_size, seq_len) 的布尔矩阵,其中 True 表示有效 token,False 表示填充 token。在计算注意力时,将填充 token 对应的键/查询位置屏蔽。
2. 因果掩码 (Causal Mask / Look-ahead Mask)
在解码器的自注意力中,为了保持自回归性质(预测第 个 token 时不能看到 及之后的 token),需要使用因果掩码。它确保位置 只能关注到位置 。
因果掩码是一个下三角矩阵:
当与填充掩码结合时,通常将两者取逻辑与,然后在计算注意力得分前将无效位置设为 。
PyTorch 实现
def create_padding_mask(seq, pad_token_id=0):
"""seq: (batch_size, seq_len) token id 序列"""
return (seq != pad_token_id).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, seq_len)
def create_causal_mask(size):
"""生成下三角掩码,shape: (size, size)"""
mask = torch.triu(torch.ones(size, size), diagonal=1).bool() # 上三角为 True
return ~mask # True 表示允许关注
# 在注意力计算中合并掩码
def combine_masks(padding_mask, causal_mask):
# padding_mask: (batch, 1, 1, seq_len_k)
# causal_mask: (1, seq_len_q, seq_len_k) 或 (seq_len_q, seq_len_k)
# 输出形状 (batch, 1, seq_len_q, seq_len_k)
if padding_mask is not None:
mask = padding_mask & causal_mask.unsqueeze(0)
else:
mask = causal_mask
return mask
# 在 scaled_dot_product_attention 中使用
def scaled_dot_product_attention(q, k, v, mask=None):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
# mask 中 True 表示允许关注,False 表示屏蔽
scores = scores.masked_fill(~mask, -1e9)
attention_weights = F.softmax(scores, dim=-1)
return torch.matmul(attention_weights, v), attention_weights注意:在实际实现中,为了提高效率,常常将填充掩码和因果掩码预先计算好并合并为一个张量,传入注意力函数。
前馈层 (Feed-Forward Network)
在多头注意力机制之后,Transformer 的每个编码器和解码器层都包含一个全连接的前馈网络(FFN)。该网络对每个 token 的表示独立地进行相同的非线性变换,从而增强模型的表达能力。
FFN 由两个线性变换和一个激活函数组成(通常使用 ReLU 或其变体 GELU)。设输入为 ,则:
其中:
- , 是第一个线性层的参数;
- , 是第二个线性层的参数;
- 是前馈层的隐藏维度,通常设为 (即 2048 当 时);
- GELU 是高斯误差线性单元激活函数:,其中 是标准正态分布的累积分布函数。相比 ReLU,GELU 更平滑,常用于现代 Transformer 模型。
值得注意的是,FFN 对序列中的每个位置独立作用(参数共享),即输出矩阵的第 行仅依赖于输入矩阵的第 行。这使得 FFN 能够在不破坏位置独立性的前提下,为每个 token 引入非线性变换。
PyTorch 实现
class FeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int = None, dropout: float = 0.1):
super().__init__()
if d_ff is None:
d_ff = 4 * d_model
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# x: (batch_size, seq_len, d_model)
x = self.linear1(x)
x = F.gelu(x) # GELU 激活
x = self.dropout(x)
x = self.linear2(x)
return x残差连接与层归一化 (Add & Norm)
随着神经网络层数的加深,梯度消失和表示退化问题会变得严重。Transformer 采用了 残差连接 (Residual Connection) 与 层归一化 (Layer Normalization) 相结合的策略,使得梯度可以顺畅地流过深层网络,同时稳定训练过程。
每个子层(多头注意力或前馈网络)的输出都会与该子层的输入相加,然后再进行层归一化。形式化地,对于子层 ,其输出为:
其中 是子层的输入。在原始 Transformer 论文中,层归一化位于残差连接之后(即 Post-LN),但后续实践(如 GPT、BERT)常采用 Pre-LN 变体,即先归一化再进入子层,然后残差连接:。Pre-LN 更有利于训练稳定性,尤其当层数很深时。
层归一化 与批归一化 (Batch Normalization) 不同,它对每个样本的每个特征维度独立计算均值和方差,并应用可学习的缩放和平移参数。对于输入 ,层归一化沿最后一维(特征维度)进行:
其中:
- (每个 token 的均值,形状为 );
- (每个 token 的方差);
- 是可学习的缩放和偏移参数;
- 是一个小常数(如 )防止除零。
PyTorch 实现
class AddNorm(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, pre_ln: bool = True):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.pre_ln = pre_ln # True: Pre-LN, False: Post-LN
def forward(self, x, sublayer):
# x: 子层输入, sublayer: 子层(尚未加残差)
if self.pre_ln:
# Pre-LN: 先归一化,再经过子层,然后残差连接
return x + self.dropout(sublayer(self.norm(x)))
else:
# Post-LN: 先子层再加残差,最后归一化
return self.norm(x + self.dropout(sublayer(x)))实际使用时,Add & Norm 不单独创建一个模块,通常直接封装在 编码器/解码器 层内部:
class EncoderLayer(nn.Module):
"""单个编码器层(Pre-LN 风格)"""
def __init__(self, d_model: int, n_heads: int, d_ff: int = None, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Pre-LN: 先归一化,再子层,然后残差
residual = x
x = self.norm1(x)
x = self.self_attn(x, x, x, mask)
x = self.dropout1(x)
x = residual + x
residual = x
x = self.norm2(x)
x = self.ffn(x)
x = self.dropout2(x)
x = residual + x
return x
class DecoderLayer(nn.Module):
"""单个解码器层(Pre-LN 风格)"""
def __init__(self, d_model: int, n_heads: int, d_ff: int = None, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
# 自注意力(带因果掩码)
residual = x
x = self.norm1(x)
x = self.self_attn(x, x, x, tgt_mask)
x = self.dropout1(x)
x = residual + x
# 交叉注意力(q 来自解码器,k/v 来自编码器)
residual = x
x = self.norm2(x)
x = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.dropout2(x)
x = residual + x
# 前馈网络
residual = x
x = self.norm3(x)
x = self.ffn(x)
x = self.dropout3(x)
x = residual + x
return x动手实践:构建微型翻译机
1. 首先完成对 Transformer 的搭建:
class Transformer(nn.Module):
"""完整的 Transformer 模型(用于序列到序列任务)"""
def __init__(self,
src_vocab_size: int,
tgt_vocab_size: int,
d_model: int = 512,
n_heads: int = 8,
num_encoder_layers: int = 6,
num_decoder_layers: int = 6,
d_ff: int = 2048,
max_seq_len: int = 5000,
dropout: float = 0.1,
pad_token_id: int = 0):
super().__init__()
self.d_model = d_model
self.pad_token_id = pad_token_id
# 嵌入层(共享或独立,考虑到做文本翻译任务,两种语言有很大的区别,这里分开)
self.src_embedding = Embeddings(src_vocab_size, d_model)
self.tgt_embedding = Embeddings(tgt_vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_seq_len) # 这里的代码设计是 PE 模块自己内部把加法做好了,其他地方可能是需要自己手动在此处完成与 PE 的相加
self.encoder = Encoder(num_encoder_layers, d_model, n_heads, d_ff, dropout) # Encoder 是由若干个 EncoderLayer 堆叠而成的
self.decoder = Decoder(num_decoder_layers, d_model, n_heads, d_ff, dropout) # Decoder 是由若干个 DecoderLayer 堆叠而成的
self.output_proj = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
self._init_parameters()
def _init_parameters(self):
"""参数初始化(Xavier 均匀分布)"""
for p in self.parameters():
if p.dim() > 1:
# xavier 均匀分布是从 [-sqrt(6 / (fan_in + fan_out)), sqrt(6 / (fan_in + fan_out))] 之间均匀采样,其中 fan_in = 输入维度,fan_out = 输出维度
# 对于嵌入层,它各个维度的取值范围是 [-sqrt(3/d_model), sqrt(3/d_model)],明显小于位置编码的取值范围 [-1, 1],在向量范数上看来,位置编码占了主导作用
# 因此在早期的嵌入层设计中,会给嵌入向量乘上 sqrt(d_model) 来放大嵌入向量的范数,使其与位置编码的范数保持一致
nn.init.xavier_uniform_(p)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
"""
src: (batch, src_seq_len) 源语言 token ID
tgt: (batch, tgt_seq_len) 目标语言 token ID(训练时使用,需要偏移)
src_mask: 可选,源序列的掩码(通常为填充掩码)
tgt_mask: 可选,目标序列的掩码(通常为因果掩码 + 填充掩码)
"""
# 嵌入并添加位置编码
src_emb = self.src_embedding(src)
src_emb = self.pos_encoding(src_emb)
src_emb = self.dropout(src_emb)
tgt_emb = self.tgt_embedding(tgt)
tgt_emb = self.pos_encoding(tgt_emb)
tgt_emb = self.dropout(tgt_emb)
# 编码器
encoder_output = self.encoder(src_emb, src_mask)
# 解码器
decoder_output = self.decoder(tgt_emb, encoder_output, src_mask, tgt_mask)
# 输出投影到目标词表
logits = self.output_proj(decoder_output) # (batch, tgt_seq_len, tgt_vocab_size)
return logits
def encode(self, src, src_mask=None):
"""仅编码(用于推理时复用编码器输出)"""
src_emb = self.src_embedding(src)
src_emb = self.pos_encoding(src_emb)
src_emb = self.dropout(src_emb)
return self.encoder(src_emb, src_mask)
def decode(self, tgt, encoder_output, src_mask=None, tgt_mask=None):
"""单步解码(自回归生成时调用)"""
tgt_emb = self.tgt_embedding(tgt)
tgt_emb = self.pos_encoding(tgt_emb)
tgt_emb = self.dropout(tgt_emb)
return self.decoder(tgt_emb, encoder_output, src_mask, tgt_mask)
def generate(self, src, start_token_id, end_token_id, max_len=100, device='cpu'):
"""
自回归生成(简单示例,使用贪婪搜索)
src: (batch, src_seq_len)
返回: (batch, generated_seq_len)
"""
batch_size = src.size(0)
src_mask = create_padding_mask(src, self.pad_token_id).to(device)
encoder_output = self.encode(src, src_mask)
# 初始化解码器输入:只包含起始标记
tgt = torch.full((batch_size, 1), start_token_id, dtype=torch.long, device=device)
for _ in range(max_len):
# 生成目标掩码(因果掩码 + 填充掩码)
tgt_seq_len = tgt.size(1)
causal_mask = create_causal_mask(tgt_seq_len, device) # (1, tgt_len, tgt_len)
# 填充掩码:tgt 中没有填充(假设起始标记和生成 token 都不含 pad)
# 但为了统一接口,可以生成一个全 True 的掩码
tgt_padding_mask = torch.ones(batch_size, tgt_seq_len, dtype=torch.bool, device=device)
tgt_padding_mask = tgt_padding_mask.unsqueeze(1).unsqueeze(2) # (batch,1,1,seq_len)
combined_mask = combine_masks(tgt_padding_mask, causal_mask)
logits = self.decode(tgt, encoder_output, src_mask, combined_mask)
next_token_logits = logits[:, -1, :] # 取最后一个位置的输出
next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)
# 拼接
tgt = torch.cat([tgt, next_token], dim=1)
# 如果所有序列都生成了结束标记,则停止
if (next_token == end_token_id).all():
break
return tgt[:, 1:] # 去掉起始标记模型代码详见 codes/models/transformer.py
2. 数据集准备
这里选用 translation2019zh 语料作为训练和测试的数据集。这个数据集包含了大量的中英文平行句对,非常适合用来训练机器翻译模型。
Transformer 模型的输入需要有源语言序列 src 和不完整的目标语言序列 tgt 两个部分,输出是目标语言序列的下一个 token 的预测分布。但是数据集加载器在构建时一般是直接给出完整的源语言序列 src 和完整的目标语言序列 tgt 的,因此在训练前需要对目标语言序列 tgt 进行偏移处理(shifted right),分别构建 tgt_in 和 tgt_out
tgt_in = tgt[:, :-1] # 目标序列的输入,去掉最后一个 token
tgt_out = tgt[:, 1:] # 目标序列的输出,去掉第一个 token训练使用的损失函数使用预测当前 token 的交叉熵损失函数即可,优化器可以选择 AdamW。
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
criterion = nn.CrossEntropyLoss(ignore_index=pad_id) # ignore_index 用于忽略 <PAD> token 的损失计算具体的训练循环如下:
for src, tgt in dataloader:
src, tgt = src.to(device), tgt.to(device)
tgt_in = tgt[:, :-1] # (batch, tgt_seq_len-1)
tgt_out = tgt[:, 1:] # (batch, tgt_seq_len-1)
src_mask = create_padding_mask(src, pad_id).to(device)
tgt_mask = create_causal_mask(tgt_in.size(1), device) # 因果掩码
tgt_padding_mask = create_padding_mask(tgt_in, pad_id).to(device)
combined_mask = combine_masks(tgt_padding_mask, tgt_mask)
logits = model(src, tgt_in, src_mask, combined_mask) # (batch, tgt_seq_len-1, tgt_vocab_size)
loss = criterion(logits.view(-1, logits.size(-1)), tgt_out.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()训练部分代码详见 codes/train_transformer.py,可以使用下列命令来运行训练:
python train_transformer.py \
--data_root "data/translation" \
--train_file "translation2019zh_train.json" \
--valid_file "translation2019zh_valid.json" \
--tokenizer_name "bert-base-multilingual-cased" \
--batch_size 64 \
--epochs 20 \
--lr 0.0001 \
--max_len 128 \
--d_model 512 \
--n_heads 8 \
--num_layers 6 \
--d_ff 2048 \
--dropout 0.13. 测试模型推理阶段的能力
在测试阶段,我们可以使用训练好的模型进行推理,生成新的翻译结果。这通常涉及到自回归生成过程,即每次生成一个 token,然后将其添加到输入中继续生成下一个 token,直到生成结束标记 <EOS> 或达到最大长度。
test_sentence = "Hello, how are you?"
src_tokens = [bos_id] + tokenizer.encode(test_sentence, add_special_tokens=False) + [eos_id]
src_tensor = torch.tensor(src_tokens, dtype=torch.long).unsqueeze(0).to(device)
with torch.no_grad():
generated = model.generate(src_tensor, bos_id, eos_id, max_len=50, device=device)
generated_list = generated.squeeze(0).tolist()
# 清除特殊字符并解码
generated_list = [idx for idx in generated_list if idx not in [pad_id, bos_id, eos_id]]
translated = tokenizer.decode(generated_list)
print(f"模型输出预测: {translated}")为了衡量模型的翻译质量,我们可以使用 BLEU 分数等指标来评估生成的翻译与参考翻译之间的相似度。它通过对比”机器生成的译文”与”人工参考译文”的词序重合程度来打分。具体来说:先统计机器译文中有多少词和短语出现在了参考答案中(比如单个词、连续两个词、三个词、四个词的搭配分别检查),然后计算这些匹配的精确率并取平均;为了防止机器”只答一半”也能拿高分,还加入了一个长度惩罚项——如果生成的句子比参考答案短太多,就会扣分。最终得到一个0到1之间的数值,越接近1表示翻译质量越好。举个例子:如果机器译文是”我吃饭了”而参考答案是”我吃过了”,这两个句子虽然意思相近但用词略有不同,BLEU可能会给出一个中等分数而非满分。因此BLEU不是完美指标,但它能快速给大量翻译结果量化排名,是自然语言处理领域最常用的评测标准之一。
其中 是 n-gram 的精确率, 是 n-gram 的权重, 是 brevity penalty,用于惩罚过短的生成结果。
下面是手动实现的 BLEU 分数计算函数,供参考:
from collections import Counter
import math
def bleu_score(candidate, references, max_n=4):
"""计算BLEU分数"""
# 生成n-gram函数
def ngrams(seq, n):
return list(zip(*[seq[i:] for i in range(n)])) if len(seq) >= n else []
# 1. 统计各级修正精确率
precisions = []
for n in range(1, max_n + 1):
cand_ng = Counter(ngrams(candidate, n))
# 参考取最大计数
ref_ng = Counter()
for ref in references:
ref_ng.update(ngrams(ref, n))
# 裁剪并求和
match = sum(min(cand_ng[k], ref_ng.get(k, 0)) for k in cand_ng)
precision = match / len(candidate) if candidate else 0
precisions.append(precision)
# 2. 几何平均(加平滑防止log(0))
log_sum = sum(math.log(p + 1e-10) for p in precisions)
geo_mean = math.exp(log_sum / max_n)
# 3. 长度惩罚BP
ref_len = min(references, key=lambda x: abs(len(x)-len(candidate)))
if len(candidate) >= len(ref_len):
bp = 1.0
elif len(candidate) == 0:
bp = 0.0
else:
bp = math.exp(1 - len(ref_len) / len(candidate))
return bp * geo_mean
# ===== 使用示例 =====
if __name__ == "__main__":
candidate = "the cat sat on the mat".split()
references = ["the cat sat on the mat".split(), "a cat sat on the rug".split()]
print(f"BLEU 分数: {bleu_score(candidate, references):.4f}")也可以用 nltk 库中的 sentence_bleu 函数来计算 BLEU 分数,使用起来更方便:
from nltk.translate.bleu_score import sentence_bleu
score = sentence_bleu(
["the cat sat on the mat".split(), "a cat sat on the rug".split()],
"the cat sat".split()
)
print(f"BLEU: {score:.4f}")4. 常见疑问
为什么训练时的输入是偏移的 tgt_in (正确答案,其中不含有模型预测的 token),而不是直接把模型预测的 token 添加到 tgt_in 中,作为下一次训练时的输入?
这是因为:
- 如果像模型推理时使用自己生成的 token 作为下一步的输入,如果自己预测的 token 是错误的,那么后续的输入就会被污染,导致错误不断累加,训练过程不稳定,模型难以收敛;使用真实的目标序列作为输入可以保证训练过程中的输入是正确的,模型能够更快地学习到正确的映射关系。
- 观察输入的
tgt_in: (batch, tgt_seq_len-1)和输出的logits: (batch, tgt_seq_len-1, tgt_vocab_size)的形状,发现实际上在训练中,模型是并行地对整个序列的各种位置进行预测的,而不是自回归式的逐步生成。自回归需要迭代完成,而并行训练则可以一次性计算整个序列的损失,效率更高。
文本理解:选词填空与文本分类
文本理解是自然语言处理中的核心任务,旨在让模型理解文本的语义内容。这里介绍两种文本理解任务,分别是选词填空与文本分类。
- 选词填空:要求模型根据上下文预测文本中缺失的词语,考验模型对语境的理解能力;
- 文本分类:要求模型将文本分配到预定义的类别中,例如下一句预测、垃圾邮件分类、新闻分类、情感分析等;
1. 选词填空:
给定一个包含掩码标记的文本序列 ,这里的文本是分词后的结果, 表示第 个 tokens。文本序列中的某个位置被遮蔽了(直接用 [MASK] 这个特殊 token 替换了),模型需要预测该位置最可能的词语。数学上,这可以看作学习一个从上下文文本空间到目标词汇空间的映射:
其中 是词汇空间, 是应该填入的 token。
2. 文本分类:
给定一个文本序列 ,模型需要为其预测出一个合适的类别标签 ,其中 为类别数。这个可以用映射表示为
BERT:Encoder-Only 模型
前面两种文本理解任务聚焦于单个 token 或标签层次的预测,无需生成完整文本序列,但要求模型具备强大的全局上下文理解能力。为此,BERT (Bidirectional Encoder Representations from Transformers) 应运而生,其核心设计是仅采用 Transformer 的编码器部分(Encoder-only 架构),通过训练时的双向能力来捕捉深层次的语义关联。
BERT 的预训练
在实际训练中,为了让 BERT 有强大的文本理解能力,需要让 BERT 模型预先完成预训练任务。BERT 的预训练包含两大关键任务:
双向掩码语言建模 (Masked Language Modeling, MLM):
本质上就是前面所讲述的选词填空。通过随机掩蔽输入文本中的部分单词(用
[MASK]替换)的方式,让模型需基于上下文去预测被掩蔽的词语。这一任务迫使模型同时学习词语左侧和右侧的上下文信息,从而获得更全面的语义表示。例如输入:"苹果公司今天发布了最新的 <MASK> 手机。"模型可以同时看到
<MASK>左侧和右侧的上下文,它需要利用这些上下文信息来预测<MASK>位置应该填入的词语(例如 “iPhone”)。经过一系列编码器层的处理后,模型会输出一个与输入序列长度相同的隐藏状态序列
sequence_output: (batch_size, seq_len, d_model)。我们希望sequence_output中的每个位置都和输入序列中对应位置的 token 相对应,像图像分割模型那样,对每个 token 位置的隐藏层状态都做一系列的线性层处理后,可以得到形状为(batch_size, seq_len, vocab_size)的预测分布,其中vocab_size是词表大小。对于<MASK>位置的 token,我们可以直接从对应位置的预测分布中取出概率最高的词语作为模型的预测结果。训练的损失函数直接采用交叉熵损失函数即可,计算模型在
<MASK>位置的预测分布与真实标签之间的损失,并通过反向传播来优化模型参数。下一句预测 (Next Sentence Prediction, NSP):
本质上属于一个二分类任务。输入连续的两个句子对,模型需判断第二个句子是否在原始文本中紧邻第一个句子(
yes或no)。该任务帮助模型学习句子间的逻辑连贯性与语义关系,为后续处理涉及多句理解的复杂任务(如问答、文本分类中的长文本分析)奠定基础。在文本分类任务中,BERT 需要在输入序列的开头添加一个特殊的分类标记
<CLS>。<CLS> 这部电影非常精彩,演员的表演也很到位。具体到下一句预测的任务中,还需要在两个句子之间添加一个分隔标记
<SEP>,例如<CLS> 这部电影非常精彩,演员的表演也很到位。 <SEP> 你觉得这部电影怎么样? <SEP>这个时候,得到了
sequence_output: (batch_size, seq_len, d_model)后,模型通过取出<CLS>位置的隐藏层状态sequence_output[:, 0, :]并进行线性变换和 Softmax 操作,就可以得到全局类别信息的预测分布了。在 NSP 任务中,这个预测分布是一个二分类分布,表示输入的第二个句子是否紧邻第一个句子。训练的损失函数亦可以选用交叉熵损失函数。尽管后续一些工作发现去除 NSP 或改用其他句子级任务效果更好,但理解 NSP 有助于掌握 BERT 的设计思想。
多任务训练
通过上述任务的联合训练,BERT 可以获得强大的双向语义编码能力。更多有关预训练的内容,将会在后续章节中展开。
BERT 的微调
BERT 模型可以不只用于做选词填空和下一句预测,也可以做诸如情感分析、实体识别等其他的文本理解任务。然而,直接对一个没有经过预训练的 BERT 模型做这些更为高级的文本理解任务的训练,通常很难能得到一个表现良好的模型。这是因为这些任务通常需要模型具备对文本的深层次理解能力,而没有预训练的 BERT 模型在初始状态下并不具备这样的能力。
因此,在实际应用中,往往需要预训练的、具有一定文本理解能力的 BERT 作为初始化的模型,然后再在这些更为高级的文本理解任务上训练,这个过程被称作微调 (Fine-tuning)。通过微调,模型可以在预训练阶段学到的通用语言表示的基础上,进一步适应特定任务的需求,从而获得更好的性能。
微调也将会在后续章节中展开介绍。
BERT 的特殊输入设计
与简单的 Transformer 编码器不同的是,BERT 的输入由三部分嵌入组成:
- 语言嵌入 (Word Embeddings):将输入文本中的每个 token 转换为一个固定维度的向量表示,捕捉词语的语义信息。
- 位置嵌入 (Position Embeddings):由于 Transformer 模型本身没有序列信息,位置嵌入用于为每个 token 提供位置信息,使模型能够区分不同位置的 token。
- 类型嵌入 (Token Type Embeddings):在 BERT 的预训练任务中,输入通常是由两段文本拼接而成的,例如
[CLS] Sentence A [SEP] Sentence B [SEP],类型嵌入用于区分这两段文本中的 token,帮助模型理解它们之间的关系。
动手实践:BERT 实现
构建一个 BERT 模型,这里依然选择 Pre-LN 的设计风格 (实际最早的 BERT 是 Post-LN 架构的),编码器层的结构与之前介绍的 EncoderLayer 类似:
class BERTEncoderLayer(nn.Module):
"""单个编码器层(Pre-LN 风格)"""
def __init__(self, d_model: int, n_heads: int, d_ff: int = None, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Pre-LN: 先归一化,再子层,然后残差
residual = x
x = self.norm1(x)
x = self.self_attn(x, x, x, mask)
x = self.dropout1(x)
x = residual + x
residual = x
x = self.norm2(x)
x = self.ffn(x)
x = self.dropout2(x)
x = residual + x
return x
class BERTEncoder(nn.Module):
"""编码器:由 N 个 EncoderLayer 堆叠"""
def __init__(self, num_layers: int, d_model: int, n_heads: int,
d_ff: int = None, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
BERTEncoderLayer(d_model, n_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class BERT(nn.Module):
def __init__(self, vocab_size, num_classes=None, d_model=256, n_heads=8, num_layers=4, type_vocab_size=2, max_len=512):
super().__init__()
self.d_model = d_model
self.word_embeddings = nn.Embedding(vocab_size, d_model)
self.position_embeddings = nn.Embedding(max_len, d_model)
self.token_type_embeddings = nn.Embedding(type_vocab_size, d_model)
self.embedding_norm = nn.LayerNorm(d_model)
self.embedding_dropout = nn.Dropout(0.1)
self.encoder = BERTEncoder(num_layers, d_model, n_heads)
# 1. 增强型 MLM Head
self.mlm_head = nn.Sequential(
nn.Linear(d_model, d_model),
nn.GELU(),
nn.LayerNorm(d_model),
nn.Dropout(0.1),
nn.Linear(d_model, vocab_size)
)
# 2. CLS Pooler (用于分类/NSP任务)
self.pooler = nn.Sequential(
nn.Linear(d_model, d_model),
nn.Tanh()
)
self.classifier = nn.Linear(d_model, num_classes) if num_classes else None
def forward(self, input_ids, token_type_ids=None, attention_mask=None, task='mlm'):
# input_ids: (batch, seq_len)
# token_type_ids: (batch, seq_len)
seq_len = input_ids.size(1)
# 词嵌入 + 类型嵌入 + 位置嵌入
x = self.word_embeddings(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
x = x + self.token_type_embeddings(token_type_ids)
position_ids = torch.arange(seq_len, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
x = x + self.position_embeddings(position_ids)
x = self.embedding_norm(x)
x = self.embedding_dropout(x)
# attention_mask: (batch, seq_len) -> (batch,1,1,seq_len)
if attention_mask is not None:
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
sequence_output = self.encoder(x, attention_mask) # (batch, seq_len, d_model)
if task == 'mlm':
return self.mlm_head(sequence_output) # (batch, seq_len, vocab_size)
else: # classification / nsp
cls_hidden = sequence_output[:, 0, :] # 取 <CLS> 向量
pooled_output = self.pooler(cls_hidden) # 通过 Pooler
return self.classifier(pooled_output) # (batch, num_classes)更多代码细节详见 codes/models/bert.py
训练原理:
模型一开始是瞎猜的。但在训练时,我们会不断比对 mask_prediction_id 和原句中原本的真实词,或者 <CLS> token 对应的 logits 与真实标签之间的差异,计算交叉熵损失,然后使用优化器反向传播,逐渐逼近人类的语言规律。
需要注意的是,输入的 mask 张量是一个 boolean 矩阵,用于指示哪些位置是 <PAD>。<MASK> 部分虽然是模型需要预测的目标,但它本身也是一个有效的 token,因此在 mask 中应该被标记为 True(即不被屏蔽)。
训练部分代码详见 codes/train_bert.py,可以用下列命令一件运行
python train_bert.py \
--tokenizer_name "bert-base-chinese" \
--datasets wiki news `
--wiki_path "data/corpus/wiki_zh" \
--news_path "data/corpus/news2016zh_train.json" \
--tasks mlm nsp \
--max_len 128 \
--batch_size 32 \
--epochs 5 \
--lr 5e-5 \
--d_model 768 \
--n_heads 12 \
--num_layers 12 \
--log_interval 50 \
--save_path "checkpoints/bert_pretrain"使用 PyTorch nn.TransformerEncoder 构建 BERT
PyTorch 的 nn.TransformerEncoder 模块已经封装好了多层编码器的结构,我们可以直接利用它来构建 BERT 的编码器部分。下面是一个简化的 BERT 实现示例:
class BERT(nn.Module):
def __init__(self, vocab_size, num_classes=None, d_model=256, n_heads=8, num_layers=4, type_vocab_size=2, max_len=512):
super().__init__()
self.d_model = d_model
self.word_embeddings = nn.Embedding(vocab_size, d_model)
self.position_embeddings = nn.Embedding(max_len, d_model)
self.token_type_embeddings = nn.Embedding(type_vocab_size, d_model)
self.embedding_norm = nn.LayerNorm(d_model)
self.embedding_dropout = nn.Dropout(0.1)
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(
d_model, n_heads, dim_feedforward=4*d_model,
dropout=0.1, batch_first=True, norm_first=True
),
num_layers=num_layers
)
# 1. 增强型 MLM Head
self.mlm_head = nn.Sequential(
nn.Linear(d_model, d_model),
nn.GELU(),
nn.LayerNorm(d_model),
nn.Dropout(0.1),
nn.Linear(d_model, vocab_size)
)
# 2. CLS Pooler (用于分类/NSP任务)
self.pooler = nn.Sequential(
nn.Linear(d_model, d_model),
nn.Tanh()
)
self.classifier = nn.Linear(d_model, num_classes) if num_classes else None
def forward(self, input_ids, token_type_ids=None, attention_mask=None, task='mlm'):
seq_len = input_ids.size(1)
x = self.word_embeddings(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
x = x + self.token_type_embeddings(token_type_ids)
positions = torch.arange(seq_len, device=input_ids.device).unsqueeze(0)
x = x + self.position_embeddings(positions)
x = self.embedding_norm(x)
x = self.embedding_dropout(x)
# PyTorch TransformerEncoder 的 src_key_padding_mask: True 表示屏蔽
# 如果你的 attention_mask 是常规的 (1=有效, 0=无效),需要取反
padding_mask = ~attention_mask if attention_mask is not None else None
sequence_output = self.encoder(x, src_key_padding_mask=padding_mask)
if task == 'mlm':
return self.mlm_head(sequence_output)
else:
cls_hidden = sequence_output[:, 0, :]
pooled_output = self.pooler(cls_hidden)
return self.classifier(pooled_output)这里需要注意的是,在 nn.TransformerEncoder 中,它的逻辑是认为 mask 为 1 (或 True) 的位置是需要被屏蔽的。如果你的 attention_mask 定义为 True 表示有效位置(非填充),那么在调用时需要对掩码进行逻辑取反处理。
文本生成
文本理解的目标是“读懂”文本,而文本生成的目标则是“写出”文本。生成任务要求模型自主地产生一段连贯的、符合语义的文本序列,典型应用包括文本续写、对话生成、代码生成等。
与理解任务不同,生成任务采用的是自回归 (Autoregressive) 的方式——模型根据已经生成的前缀,逐词预测下一个词。每生成一个新词,就将其追加到输入中,再继续预测下一个,直到生成结束标记或达到最大长度。
数学上,给定一个初始文本序列 ,模型需要不断预测并生成后续的 个 tokens:
GPT:Decoder-only 模型
生成任务最常用的架构是 Decoder-only(仅解码器),代表模型为 GPT 系列。它只保留了 Transformer 的解码器部分,并去掉了编码器‑解码器的交叉注意力。
为什么不需要编码器?
要回答这个问题,需要先区分两类生成任务:
条件生成(如机器翻译、文本摘要):条件生成,简单来说,就是文本的生成还需要参考一个外部的条件指示信息,像 seq2seq 类型的任务(例如文本翻译),编码器提取的源语言序列的全局上下文中间表示就是一个典型的条件信息。给定一个外部的源序列(源语言句子、长文档),模型必须根据这个源序列生成目标序列。这也是为什么 seq2seq 的建模任务需要使用一个编码器将源序列压缩成中间表示,再让解码器再通过交叉注意力从中提取信息。
无条件生成(如文本续写、故事生成):模型只需要根据已经生成的文本前缀继续往下写,没有额外的“源输入”。GPT 做的正是这一类任务——它只依赖当前已生成的 token,所有必要的信息都蕴含在这些 token 的上下文中。
如果只让 GPT 做文本生成任务,那么它是不需要处理外部源序列,所以编码器是多余的。仅用解码器,配合因果注意力(每个 token 只能看到左侧的 token),就足以让模型学习到语言的内在规律:给定前文,预测后文。这也是为什么 GPT 是一个 Decoder-only 的架构。
核心特点:
- 因果注意力 (Causal Attention):每个位置只能看到它左侧的 token(包括自己),不能看到右侧。这通过一个下三角掩码实现,确保自回归生成时不会“作弊”窥探未来。
- 位置编码:通常使用可学习的位置嵌入,因为生成序列长度不固定。
- 训练任务:语言建模 (Language Modeling) —— 给定文本序列,预测下一个 token。所有位置的损失都会被计算(不同于 BERT 只计算掩码位置)。
动手实践:Decoder-only 生成模型
下面用 PyTorch 实现一个简单的 GPT 模型,用于文本生成任务。
class GPTDecoderLayer(nn.Module):
"""仅包含自注意力 + 前馈网络的解码器层"""
def __init__(self, d_model: int, n_heads: int, d_ff: int = None, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None, rotary_emb=None):
# 自注意力 + 残差(Pre-LN)
residual = x
x = self.norm1(x)
x = self.self_attn(x, x, x, mask, rotary_emb=rotary_emb)
x = self.dropout1(x)
x = residual + x
# 前馈网络 + 残差
residual = x
x = self.norm2(x)
x = self.ffn(x)
x = self.dropout2(x)
x = residual + x
return x
class GPTDecoder(nn.Module):
"""堆叠多层 GPTDecoderLayer"""
def __init__(self, num_layers: int, d_model: int, n_heads: int,
d_ff: int = None, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
GPTDecoderLayer(d_model, n_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None, rotary_emb=None):
for layer in self.layers:
x = layer(x, mask, rotary_emb=rotary_emb)
return self.norm(x)
class GPT(nn.Module):
"""
GPT 实现:
1. 使用 RoPE (Rotary Positional Embedding) 代替绝对位置编码
2. 加入可学习的 Position Embedding (作为示例)
3. 规范的权重初始化 (GPT-2 风格)
4. Pre-LN 风格
"""
def __init__(self, vocab_size: int, d_model: int = 256, n_heads: int = 8,
num_layers: int = 4, max_seq_len: int = 512, dropout: float = 0.1):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.token_emb = nn.Embedding(vocab_size, d_model)
self.pos_emb = nn.Embedding(max_seq_len, d_model)
self.decoder = GPTDecoder(num_layers, d_model, n_heads, dropout=dropout)
self.lm_head = nn.Linear(d_model, vocab_size)
# 动态生成 RoPE 缓存 (sin/cos)
# 注意:RoPE 实际上作用在 head dimension (d_k) 上
self.register_buffer("inv_freq", 1.0 / (10000**(torch.arange(0, self.d_k, 2).float() / self.d_k)))
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, module):
"""GPT-2 风格的权重初始化"""
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
elif isinstance(module, nn.LayerNorm):
torch.nn.init.zeros_(module.bias)
torch.nn.init.ones_(module.weight)
def get_rotary_emb(self, seq_len, device):
"""计算旋转位置编码向量"""
t = torch.arange(seq_len, device=device).float()
freqs = torch.outer(t, self.inv_freq) # (seq_len, d_k/2)
# 旋转位置编码需要 cos(theta) 和 sin(theta) 对齐到 d_k
# 这里使用 interleave 或 cat [freq, freq] 取决于 apply_rotary_emb 的实现
# 我们的 apply_rotary_emb 使用了 split dim=-1,所以这里用 cat
emb = torch.cat([freqs, freqs], dim=-1) # (seq_len, d_k)
cos = emb.cos().view(1, 1, seq_len, self.d_k) # (1, 1, seq_len, d_k)
sin = emb.sin().view(1, 1, seq_len, self.d_k) # (1, 1, seq_len, d_k)
return cos, sin
def forward(self, input_ids, attention_mask=None):
"""
input_ids: (batch, seq_len)
attention_mask: (batch, seq_len), True 表示非 padding(可选)
"""
batch_size, seq_len = input_ids.shape
# 1. 词嵌入 + 可学习位置嵌入
tok_x = self.token_emb(input_ids)
# 生成 [0, 1, 2, ..., seq_len-1] 并映射到 embedding 层
pos_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0)
pos_x = self.pos_emb(pos_ids) # (1, seq_len, d_model)
x = tok_x + pos_x
# 2. 准备 RoPE (旋转位置编码)
cos, sin = self.get_rotary_emb(seq_len, input_ids.device)
# 3. 生成因果掩码(下三角,True 表示允许关注)
causal_mask = torch.tril(torch.ones(seq_len, seq_len, dtype=torch.bool, device=input_ids.device))
causal_mask = causal_mask.unsqueeze(0).unsqueeze(0) # (1, 1, seq_len, seq_len)
# 4. 合并 padding mask
if attention_mask is not None:
# attention_mask: (batch, seq_len) -> (batch, 1, 1, seq_len)
padding_mask = attention_mask.unsqueeze(1).unsqueeze(2)
mask = padding_mask & causal_mask
else:
mask = causal_mask
# 5. 解码器并传入 RoPE
x = self.decoder(x, mask, (cos, sin))
# 6. 输出层
logits = self.lm_head(x) # (batch, seq_len, vocab_size)
return logits训练方式
对于输入文本 "I love you",将其作为输入,将向右偏移一位的 "love you" 作为标签(通常用 -100 忽略起始位置)。这里模型的输出和损失计算与文本翻译任务中的 Transformer 类似,损失函数选择为计算所有位置的交叉熵。
具体训练代码参考 codes/train_gpt.py,可以用下列命令一键运行
python train_gpt.py \
--datasets wiki news \
--wiki_path "data/wiki" \
--news_path "data/news" \
--batch_size 4 \
--max_len 512 \
--d_model 768 \
--n_heads 12 \
--num_layers 12 \
--save_path "checkpoints/gpt"文本生成(推理阶段)
GPT 完全放弃了双向互看的编码器,它是一个叠了非常多层的纯单向解码器。 它的任务非常纯粹:根据前 个词,预测第 个词(Next Token Prediction)。
因此在推理阶段,模型需要根据一个初始的文本前缀(prompt)来生成后续文本。生成过程是自回归的:每次预测下一个 token 后,将其追加到输入中,再继续预测下一个 token,直到生成结束标记或达到最大长度。
这里我们还引入了采样策略,包括 Temperature 缩放、Top-K 采样和 Top-P (Nucleus) 采样,以控制生成文本的多样性和质量。下面是一个改进后的生成函数示例:
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
"""抽取采样策略:Top-K 和 Nucleus (Top-P) 采样"""
top_k = min(top_k, logits.size(-1))
if top_k > 0:
# 过滤掉不在 Top-K 列表中的 tokens
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# 移除累积概率超过 top_p 的 tokens
sorted_indices_to_remove = cumulative_probs > top_p
# 将第一个超过阈值的 token 也保留下来(Shift right)
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
# 将需要移除的索引映射回原始 logits 的位置
for i in range(logits.size(0)):
indices_to_remove = sorted_indices[i][sorted_indices_to_remove[i]]
logits[i][indices_to_remove] = filter_value
return logits
@torch.no_grad()
def generate(model, prompt_ids, max_new_tokens=50, temperature=1.0, top_k=50, top_p=0.9, eos_token_id=None):
"""
改进后的生成函数:
1. 支持 Temperature 缩放 (控制创造性)
2. 支持 Top-K / Top-P (Nucleus) 过滤 (防止崩坏)
3. 支持 Batch 生成
"""
model.eval()
generated = prompt_ids
for _ in range(max_new_tokens):
# GPT 输入长度通常有上限 (max_seq_len)
input_ids = generated[:, -512:]
logits = model(input_ids) # (batch, seq_len, vocab_size)
next_token_logits = logits[:, -1, :] / temperature
# 采样过滤
filtered_logits = top_k_top_p_filtering(next_token_logits.clone(), top_k=top_k, top_p=top_p)
probs = F.softmax(filtered_logits, dim=-1)
# 采样获取下一个 token
next_token = torch.multinomial(probs, num_samples=1) # (batch, 1)
generated = torch.cat([generated, next_token], dim=1)
if eos_token_id is not None and (next_token == eos_token_id).all():
break
return generated使用 PyTorch nn.TransformerEncoder 构建 GPT
类似于 BERT,我们也可以利用 PyTorch 封装好的 nn.TransformerEncoder 来快速搭建 GPT。由于 GPT 是 Decoder-only 架构,本质上就是一个带有因果掩码 (Causal Mask) 的 Transformer 编码器。
class GPT(nn.Module):
def __init__(self, vocab_size, d_model=256, n_heads=8, num_layers=4, max_len=512):
super().__init__()
self.d_model = d_model
self.token_embeddings = nn.Embedding(vocab_size, d_model)
self.position_embeddings = nn.Embedding(max_len, d_model)
self.embedding_norm = nn.LayerNorm(d_model)
self.embedding_dropout = nn.Dropout(0.1)
# GPT 使用 TransformerEncoder 层,但配合因果掩码实现 Decoder 功能
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(
d_model, n_heads, dim_feedforward=4*d_model,
dropout=0.1, batch_first=True, norm_first=True
),
num_layers=num_layers
)
self.lm_head = nn.Linear(d_model, vocab_size)
def forward(self, input_ids, attention_mask=None):
seq_len = input_ids.size(1)
# 1. 嵌入层
x = self.token_embeddings(input_ids)
positions = torch.arange(seq_len, device=input_ids.device).unsqueeze(0)
x = x + self.position_embeddings(positions)
x = self.embedding_norm(x)
x = self.embedding_dropout(x)
# 2. 构造因果掩码 (Causal Mask)
# nn.TransformerEncoder 要求掩码中 True 表示屏蔽 (mask)
causal_mask = torch.triu(torch.ones(seq_len, seq_len, device=input_ids.device), diagonal=1).bool()
# 3. 编码器处理 (Padding Mask 同样 True 表示屏蔽)
padding_mask = ~attention_mask if attention_mask is not None else None
x = self.encoder(x, mask=causal_mask, src_key_padding_mask=padding_mask)
# 4. 输出层
return self.lm_head(x)这里的 GPT 是 OpenAI 的网页版 GPT 模型吗?
不是的。 我们上面实现的 GPT 是一个基础的语言模型,它只具备最核心的能力:给定上文,预测下一个词(自回归生成)。而在网页上使用的 ChatGPT 或 GPT-4o 等产品,除了基础的文本生成能力外,还拥有:
- 指令跟随:理解用户意图,按指令回答问题、写代码、总结文档等。
- 多轮对话记忆:记住对话历史,维持上下文连贯性。
- 搜索增强:可以联网搜索最新信息(需人工开启)。
- 工具调用:调用计算器、代码解释器、外部 API 等。
- 安全与对齐:拒绝有害请求,输出符合人类价值观。
这些高级能力并非单纯的 Decoder-only 架构就能实现,而是在极大规模预训练(海量文本、数千亿参数)的基础上,再经过指令微调和人类反馈强化学习(RLHF) 才能获得。此外,像联网搜索、记忆管理等还需要智能体(Agent)框架的支持(这些内容将在后续章节中展开)。
那 GPT 能做 Seq2Seq 任务(比如翻译)吗?
可以,但需要特殊训练。原生 GPT 是纯粹的无条件生成模型(只根据上文续写)。若要它完成“中文→英文”翻译,需要:
- 在预训练阶段将翻译任务建模为“输入:请把‘你好’翻译成英文 → 输出:‘Hello’”。模型通过海量这样的例子学会翻译模式。
- 再进行指令微调,让模型理解用户给出的明确指令(如“Translate to English: 你好”)。
即使如此,由于 Decoder-only 架构缺少对源序列的双向编码,对于复杂的长句翻译,效果通常不如专门的 Encoder-Decoder 模型(如 Transformer 原始架构)。但对于大多数日常场景,经过充分训练的 GPT(如 GPT-4)已经展现出极强的翻译能力,甚至超越了一些专用翻译模型。
小结:我们这里的 GPT 是一个教学用的小型语言模型,核心是理解 Decoder-only 的生成机制。而网页版 GPT 是经过千亿级参数、海量数据、多种技术栈(预训练 + 微调 + RLHF + 工具调用)打磨而成的产品级智能体。
Transformer 三大架构对比
| 架构类型 | 核心模型 | 适用任务 | 信息流动(可见性) |
|---|---|---|---|
| 完整编码器-解码器 (Encoder-Decoder) | 原始 Transformer, T5 | 中英翻译、摘要生成 | 编码器双向全可见;解码器只能看自己之前的部分+完整的编码器信息 |
| 仅编码器 (Encoder-Only) | BERT, RoBERTa | 选词填空、文本分类 | 双向上下文全可见(我知道整句的话结构) |
| 仅解码器 (Decoder-Only) | GPT 系列, LLaMA | 自回归文本生成 | 仅单向/自回归可见(我只能根据过去预测未来) |
练习部分
任务一:图像数据上的 Transformer - Vision Transformer 模型
背景知识
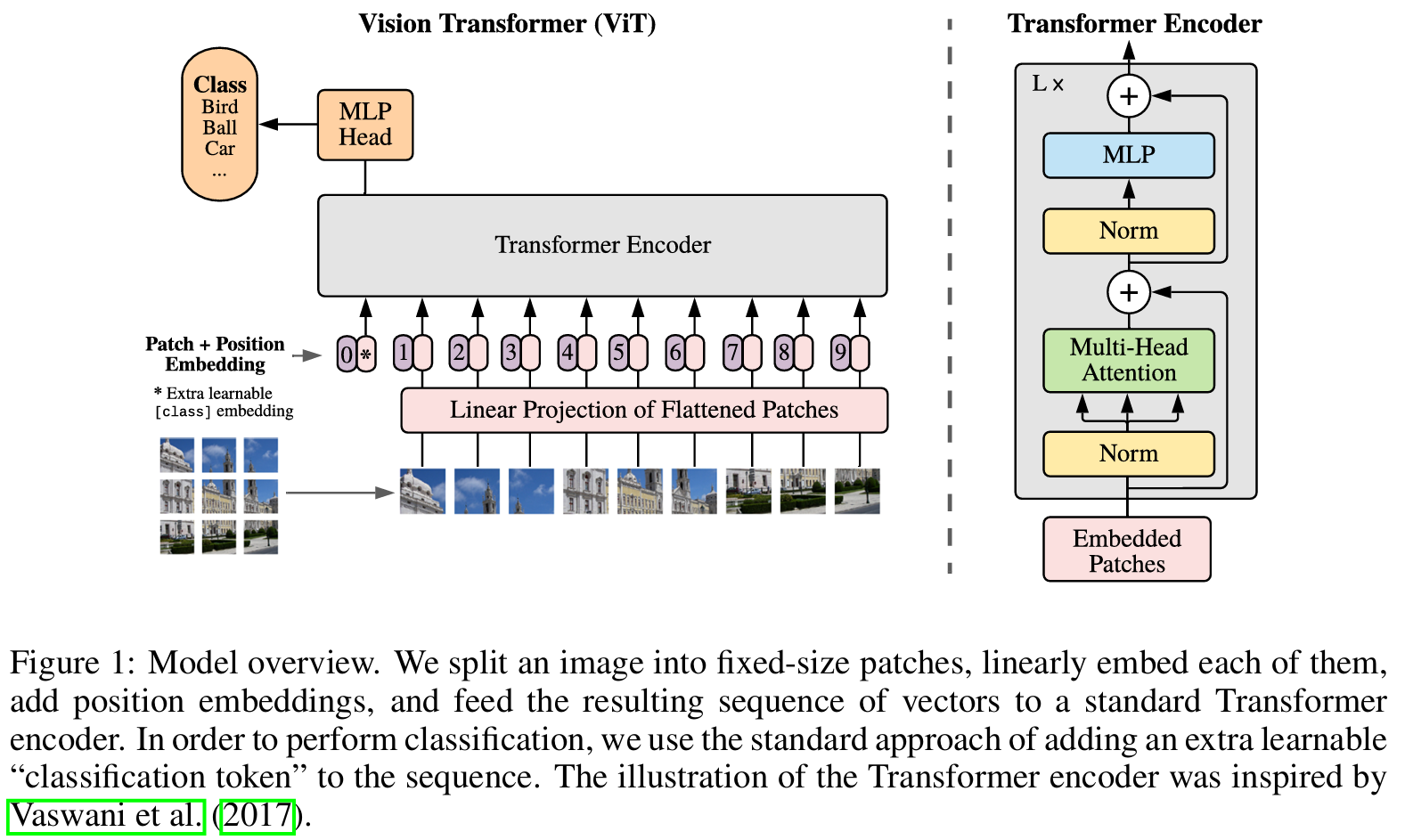
长期以来,卷积型神经网络(CNN-based)是计算机视觉的主流。自从 Transformer 模型问世并在 NLP 任务上大放异彩之后,有人好奇,能否把 Transformer 架构搬到图像处理领域中去呢?2020 年,Google 提出了 Vision Transformer (ViT),证明了纯 Transformer Encoder 结构在图像分类任务上可以超越长期以来的霸主卷积型神经网络。
ViT 的核心思想是将图像分割成固定大小的 图像块 (patch),然后将每个块线性投影为向量,从而将二维的图像转换为一个个的一维图像块 patch 序列,并叠加可学习的位置编码以保留空间信息,随后输入标准 Transformer 编码器。实验证明,在 JFT-300M 等超大规模数据集上预训练后,ViT 在 ImageNet 等分类任务上能够达到甚至超越当时最先进的卷积型神经网络。
ViT 工作流程:
- 将输入图像 划分为 个大小为 的 patch。
- 将每个 patch 展平并线性投影到维度 (称为 patch embedding)。
- 在序列开头添加一个可学习的
[CLS]token,用于最终的分类输出。 - 加上可学习的位置编码(或正弦余弦编码)。
- 输入 Transformer 编码器(与 BERT 相同,Encoder-only)。
- 取
[CLS]位置的输出,经过 MLP 分类头得到类别预测。
优势:ViT 打破了 CNN 的局部归纳偏置,能够通过自注意力捕获全局依赖。在大规模数据上预训练后,表现优异。
任务目标
1. 参考 Vision Transformer 的论文,实现一个基础的 ViT 模型。
2. 在 ImageNet 数据集上训练 ViT,并测试该模型能否达到合理的分类准确率。
3. 在 Caltech101 数据集上训练 ViT,并与 ResNet-50 进行性能对比。为什么在 Caltech101 上 ViT 的表现反而不如 ResNet-50?
4. 卷积型神经网络真的不适合大型数据集吗?有位年轻人不这么认为,并提出了 ConvNeXt,阅读 ConvNeXt 的论文,分析它对卷积网络做了哪些改进,使得在大型数据集上能够与 ViT 竞争?
5. 既然 ViT 是 Encoder-only 架构,那么是否也可以用类似 Decoder-only 的方式来做图像生成任务呢?如果可以,应该如何设计这样的模型?
任务二:跨越内存墙 - FlashAttention
背景知识
注意力计算的瓶颈
标准 Transformer 中的缩放点积注意力计算如下:
- 计算得分矩阵
- 对 按行做 Softmax,得到注意力权重
- 计算输出
其中 是序列长度。每一步都需要在 GPU 显存(HBM)中分配并存储 的中间矩阵(通常为 float32/16),导致 显存复杂度 和 大量 HBM 读写。当 时,仅 就占用 64MB;当 时,占用 1GB。更严重的是,频繁读写 HBM 的速度远慢于 GPU 计算速度,形成“内存墙”(Memory Wall)。
在 GPU 的体系结构中,GPU 上是有一个非常快的片上高速 Cache - SRAM 的,不过它的容量非常有限(通常几十 KB 到几百 KB),远小于 HBM 的容量(GB 级)。
FlashAttention 的核心思想
FlashAttention 就是考虑到了 SRAM 的优点和容量限制的。它通过 平铺(Tiling) 和 算子融合(Kernel Fusion) 加速了注意力计算:
- 将 分成小块(例如 64×64),每次只将一小块载入 GPU 的 SRAM(共享内存) 中计算。
- 在 SRAM 内完成整个注意力计算(包括 Softmax),并直接累加到最终输出 上,从不写出完整的 矩阵。
- 通过 在线 Softmax 算法,在分块计算时动态维护每个行的最大值和归一化分母,保证数学等价。
FlashAttention 将显存复杂度降为 ,速度提升 2~4 倍。更多细节可参考原始论文 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。
在线 Softmax 原理
假设我们要计算一行 对所有 的注意力。传统做法需要先拿到所有 才能计算 Softmax。但是在线 Softmax 允许我们分块处理——每处理一个块,就根据当前块的最大值和指数和更新全局最大值和分母。
对于单行,设已经处理了前 个块,记录了当前全局最大值 和指数和 。当新块到来时,计算该块内的最大值 和指数和 (指数减去新最大值),然后合并:
最后,每个块的输出贡献需要乘上相应的缩放因子 进行修正。实际实现时,通常同时处理多个行(一个块)。
代码实现(前向)
import torch
import math
def flash_attention_forward(Q, K, V, block_size=64):
"""
模拟 FlashAttention 的分块前向计算(不写出完整 S 矩阵)
Q, K, V: (batch, seq_len, head_dim)
返回: O (batch, seq_len, head_dim)
"""
batch, N, d = Q.shape
# 初始化输出 O 和用于在线 Softmax 的辅助变量
O = torch.zeros_like(Q)
# 每个样本每行的最大值和指数和
m = torch.full((batch, N), -float('inf'), device=Q.device) # 全局最大值
l = torch.zeros((batch, N), device=Q.device) # 指数和
# 按块遍历 K, V(列块)
for i in range(0, N, block_size):
k_block = K[:, i:i+block_size, :] # (batch, block_size, d)
v_block = V[:, i:i+block_size, :]
# 计算当前块对所有行的分数(不分配完整矩阵,仅计算一个块)
# Q 与 k_block 的点积,形状 (batch, N, block_size)
scores = torch.matmul(Q, k_block.transpose(-2, -1)) / math.sqrt(d)
# 当前块内的最大值
m_block = scores.max(dim=-1, keepdim=True)[0] # (batch, N, 1)
# 更新全局最大值和指数和
m_new = torch.maximum(m, m_block.squeeze(-1))
# 对于每个样本的每行,需要计算修正因子
# 原始公式:l_new = l * exp(m - m_new) + sum(exp(scores - m_new.unsqueeze(-1)))
# 注意 m 是上一轮全局最大值,m_new 是新的全局最大值
l = l * torch.exp(m - m_new) + (scores - m_new.unsqueeze(-1)).exp().sum(dim=-1)
# 维护 O 的尺度对齐
# O_new = O * exp(m - m_new) + exp(scores - m_new.unsqueeze(-1)) * v_block
O = O * torch.exp(m - m_new).unsqueeze(-1) + torch.matmul((scores - m_new.unsqueeze(-1)).exp(), v_block)
m = m_new
# 当前块内的注意力权重已在上面计算并累加到 O
# 最终归一化
O = O / l.unsqueeze(-1)
return O验证:与标准注意力输出比较,确保数值一致。
import time
def standard_attention(Q, K, V):
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(Q.size(-1))
attn = torch.softmax(scores, dim=-1)
return torch.matmul(attn, V)
# 随机数据测试
torch.manual_seed(42)
batch, N, d = 4, 1024, 64
Q = torch.randn(batch, N, d)
K = torch.randn(batch, N, d)
V = torch.randn(batch, N, d)
# 预热
_ = standard_attention(Q, K, V)
# 测试 Standard Attention
start_std = time.time()
for _ in range(10):
out_std = standard_attention(Q, K, V)
print(f"Standard Attention avg time: {(time.time() - start_std) / 10:.6f}s")
# 预热
_ = flash_attention_forward(Q, K, V, block_size=64)
# 测试 Flash Attention
start_flash = time.time()
for _ in range(10):
out_flash = flash_attention_forward(Q, K, V, block_size=64)
print(f"Flash Attention (Python Sim) avg time: {(time.time() - start_flash) / 10:.6f}s")
print("Max diff:", (out_flash - out_std).abs().max().item())输出结果
Standard Attention avg time: 0.003153s
Flash Attention (Python Sim) avg time: 0.023555s
Max diff: 1.6391277313232422e-07自定义 PyTorch 算子
PyTorch 中提供了 torch.autograd.Function 接口用于自定义可微分的算子。其中 forward 方法定义前向计算,backward 方法定义反向传播。这些算子可以直接在 nn.Module 中调用,并参与前向传播和反向自动求导的计算图中。下面我们以一个简单的 逐元素乘幂 为例,展示如何编写自定义算子。
class PowerFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x, exponent):
ctx.save_for_backward(x)
ctx.exponent = exponent
return x ** exponent
@staticmethod
def backward(ctx, grad_output): # forward 中有多少个输出参数,这里就有多少输入参数
x, = ctx.saved_tensors
exponent = ctx.exponent
grad_input = exponent * (x ** (exponent - 1)) * grad_output
# 注意 return 的时候,在 forward 中有多少输入参数,这里就要有多少返回值,且顺序对应
return grad_input, None # 对 exponent 无梯度
def power(x, exponent):
return PowerFunction.apply(x, exponent)
# 测试
x = torch.randn(3, requires_grad=True)
y = power(x, 2)
y.sum().backward()
print(torch.allclose(x.grad, 2 * x)) # 应等于 2*x,验证梯度正确性C++ 扩展编写 Softmax 算子
PyTorch 允许用 C++ 编写算子并编译成动态库,通过 torch.utils.cpp_extension 加载。下面演示如何实现一个 CPU 版本的 Softmax 算子。
步骤 1:编写 C++ 源文件 softmax_cpu.cpp
#include <torch/extension.h>
#include <vector>
// 前向传播的 Softmax 计算
torch::Tensor softmax_cpu_forward(torch::Tensor input) {
auto last_dim = input.dim() - 1;
auto max_vals = std::get<0>(input.max(last_dim, /*keepdim=*/true));
auto exp_input = torch::exp(input - max_vals);
auto sum_exp = exp_input.sum(last_dim, /*keepdim=*/true);
return exp_input / sum_exp;
}
// 反向传播的梯度计算
torch::Tensor softmax_cpu_backward(torch::Tensor grad_output, torch::Tensor output) {
auto grad_input = output * (grad_output - (output * grad_output).sum(-1, true));
return grad_input;
}
// 封装接口
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("softmax_forward", &softmax_cpu_forward, "CPU Softmax Forward");
m.def("softmax_backward", &softmax_cpu_backward, "CPU Softmax Backward");
}
完成上述代码的编写后,将这段 C++ 代码保存为 softmax_cpu.cpp,然后编写用于编译封装的 setup.py 文件
# setup.py
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CppExtension
setup(
name='softmax_cpu',
ext_modules=[
CppExtension(
name='softmax_cpu', # 编译出的模块名
sources=['softmax_cpu.cpp'],
),
],
cmdclass={
'build_ext': BuildExtension
}
)步骤 2:编写 setup.py 动态编译
在编译之前,首先安装 ninja 库,这可以加速编译过程:
pip install ninja然后运行以下命令编译 C++ 扩展:
# 编译 C++ 扩展,编译后的库会直接放在当前目录下,命名为 softmax_cpu.so (Linux/MacOS) 或类似 softmax_cpu.cp312-win_amd64.pyd 名称的文件 (Windows)
python setup.py build_ext --inplace
# 也可以直接安装到全局的 Python 环境中
pip install -e .CUDA 扩展编写 Softmax 算子
CUDA 是 NVIDIA 提出的并行计算平台和编程模型,可以利用 GPU 的强大计算能力加速深度学习中的核心算子。与 C++ 版本的类似,CUDA 版本的 Softmax 算子需要编写 .cu 文件,使用 CUDA 的线程块和共享内存来实现分块计算和在线 Softmax。可以在文件 codes/softmax_kernels/softmax_cuda/softmax_cuda.cu 中查看一个简单的 CUDA 实现示例。
CUDA 的编译封装和 C++ 类似,只需在 setup.py 中指定 sources 包含 .cu 文件,并使用 CUDAExtension:
# setup.py
from setuptools import setup
from torch.utils.cpp_extension import CUDAExtension, BuildExtension
setup(
name='softmax_cuda',
ext_modules=[
CUDAExtension(
name='softmax_cuda',
sources=['softmax_cuda.cu'],
extra_compile_args={'cxx': ['-O3'], 'nvcc': ['-O3']}
)
],
cmdclass={'build_ext': BuildExtension}
)其他操作和 C++ 类似,运行 python setup.py build_ext --inplace 编译生成动态库。
调用 C++ 或 CUDA 算子,并封装为 torch.autograd.Function
得到 .pyd 或 .so 文件后,我们可以在 Python 中导入编译好的算子,并通过 torch.autograd.Function 显式构建一条自定义的计算图节点:
import torch
import softmax_cpu
import softmax_cuda
class Softmax(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
# 兼容性处理,防止 CUDA 内存不连续
x_contig = x.contiguous()
if x.is_cuda:
ctx.cuda = True
out = softmax_cuda.softmax_forward(x_contig)
else:
ctx.cuda = False
out = softmax_cpu.softmax_forward(x_contig)
ctx.save_for_backward(out)
return out
@staticmethod
def backward(ctx, grad_out):
out = ctx.saved_tensors[0]
grad_out_contig = grad_out.contiguous()
if ctx.cuda:
return softmax_cuda.softmax_backward(grad_out_contig, out)
else:
return softmax_cpu.softmax_backward(grad_out_contig, out)
# 方式1:直接调用 apply
x = torch.randn(3, 5, requires_grad=True)
y = Softmax.apply(x)
# 方式2:包装成普通函数
def my_softmax(x):
return Softmax.apply(x)
y2 = my_softmax(x)
# 方式3:直接赋值给变量
softmax = Softmax.apply
y3 = softmax(x)
# 测试
print("输出:\n", y)
loss = y.sum()
loss.backward()
print("梯度:\n", x.grad)即时编译 (JIT - Just-In-Time) 加载方式
除了提前编译,我们也可以用 torch.utils.cpp_extension.load 直接在运行时编译加载源码。这种方式适合开发调试:
import torch
# 预先定义全局模块
_cpu_module = None
_cuda_module = None
def get_cpu_module():
global _cpu_module
if _cpu_module is None:
from torch.utils.cpp_extension import load
_cpu_module = load(name="softmax_cpu", sources=["softmax_kernels/softmax_cpu/softmax_cpu.cpp"], verbose=False)
return _cpu_module
def get_cuda_module():
global _cuda_module
if _cuda_module is None:
from torch.utils.cpp_extension import load
_cuda_module = load(name="softmax_cuda", sources=["softmax_kernels/softmax_cuda/softmax_cuda.cu"], verbose=False)
return _cuda_module
class AutoSoftmaxFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
input_contig = input.contiguous()
if input.is_cuda:
output = get_cuda_module().softmax_forward(input_contig)
ctx.cuda_enabled = True
else:
output = get_cpu_module().softmax_forward(input_contig)
ctx.cuda_enabled = False
ctx.save_for_backward(output)
return output
@staticmethod
def backward(ctx, grad_output):
output = ctx.saved_tensors[0]
grad_out_contig = grad_output.contiguous()
if ctx.cuda_enabled:
grad_input = get_cuda_module().softmax_backward(grad_out_contig, output)
else:
grad_input = get_cpu_module().softmax_backward(grad_out_contig, output)
return grad_input任务目标
1. 思考下面的问题:Python 的 FlashAttention 实现虽然避免了分配完整的 矩阵,但为什么运行速度反而比标准注意力慢?试着从 Python 循环、PyTorch 内核启动开销、未融合的算子的角度思考。
2. 尝试用 C++ 或者 CUDA 实现 FlashAttention,并封装为 PyTorch 算子。
3. 在一个小型的 Transformer 模型中替换标准注意力为你实现的 FlashAttention,比较训练速度和显存占用。
4. 使用现成的通用 FlashAttention 库
pip install flash-attention并在你的 Transformer 模型中调用 torch.nn.functional.scaled_dot_product_attention 来使用 FlashAttention 后端,比较性能差异。
完整实现 FlashAttention 的正反向非常复杂,有兴趣的读者可以参考 flash-attention 官方实现。本练习只需理解原理,不要求写出完整反向。
更多参考资料
Transformer
- Attention Is All You Need | Transformer 原始论文
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale | Vision Transformer 原始论文
分词器与词嵌入层
- 知乎文章 | 全网最全的大模型分词器(Tokenizer)总结
- 知乎文章 | 从0开始词嵌入(Word embedding)
- 一文彻底搞懂Transformer - Word Embedding(词嵌入)
seq2seq
BERT 与 GPT
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | BERT 原始论文
- GPT: Improving Language Understanding by Generative Pre-Training | GPT 原始论文
- 知乎文章 | Transformer两大变种:GPT和BERT的差别(易懂版)-2更
第三章项目文件