

2.1 Recap: Bellman 最优方程
通过求解 Bellman 最优方程,我们可以得到最优策略和最优状态价值函数。Bellman 最优方程是一个递归方程,它将当前状态的价值与下一个状态的价值联系起来。上节中我们推导得到的 Bellman 最优方程的形式如下
其中 是最优状态价值函数, 是当前状态的价值函数, 是策略, 是状态 的动作空间, 是奖励空间, 是状态空间, 是在状态 下采取动作 时获得奖励 的概率, 是在状态 下采取动作 时转移到状态 的概率。方程中,最优的状态价值函数 是未知的,策略空间 ,动作空间 ,奖励空间 ,状态空间 ,环境模型 和 都是已知的。
2.1.1 优化变量的替换
当环境变量 和 已知时,贪心策略 ,一个确定性策略,是一个最优策略。贪心策略可以被表示为
即贪心策略只会选取当前已知的最优动作 ,而不考虑其他动作。
- 贪心策略是最优策略,但是最优策略并不一定都是贪心策略
- 贪心策略是一个确定性策略,而最优策略可以是一个随机策略
推导
这是因为 是一个对于 加权平均数,因为 。令 取最大值的 对应的权重为 1,其他的权重为 0,即可实现 取最大值。
因此,Bellman 最优方程可以简化为(对应贪心策略)
方程性质
- 解的存在性
- 解的唯一性
- 解的最优性
相关证明可以参考可以参考 西湖大学赵世钰老师所出版的强化学习的数学原理的 P38-P45。
那么,该如何求解 Bellman 最优方程呢?这一节的答案是 DP(动态规划)
2.2 动态规划方法概述
动态规划的思想是将一个复杂的问题分解为多个简单的子问题,通过求解子问题来求解原问题。一般可以用DP求解的问题具有最优子结构和重叠子问题的性质。
- 最优子结构:指一个问题的最优解包含了其子问题的最优解
- 重叠子问题:指一个问题可以分解为多个子问题,这些子问题之间存在重叠
动态规划的方法假设已经有了MDP框架下的全部知识,包括状态空间 、动作空间 、奖励函数 、转移概率 等。需要注意这一点,因为后续的强化学习方法不用建立在这些知识都已知的基础之上的。
在求解 Bellman 最优方程的问题上,DP的核心思想是 使用价值函数的 Bellman 结构搜索最优策略,换句话说,假设状态 的价值函数 已知,那么可以通过迭代的方式得到其他状态 的价值函数 。在每一轮迭代的过程中, 第 轮的状态价值函数的求解需要依赖第 轮的状态价值函数的结果。
- 最优子结构:对于每一个状态 ,它的最优价值函数 是由它的后继状态 的最优价值函数 计算得到的,后继的最优用于求解当前的最优。
- 重叠子问题:对于不同的状态 ,它在计算 Bellman 方程时都有可能会用到同一个状态 的价值函数 ,因此可以将这些重复的计算结果存储起来,避免重复计算,从而提高效率。
2.3 Policy Iteration
策略迭代由两部分组成,分别是策略评估和策略改进。
- 策略评估:在给定策略的情况下,计算该策略下的价值函数
- 策略改进:在给定状态价值函数的情况下,计算最优策略
2.3.1 策略评估
假设已知当前策略为 ,目标是预测出在该策略下的状态价值函数 。基于 Bellman 期望方程,有
该方程是一个线性方程组,向量形式为
其中, 是期望的奖励向量, 是状态转移概率矩阵, 是状态价值函数向量。显然,当 可逆时,方程组有唯一解 。当然,也可以通过迭代的方式求解该方程组,迭代公式为
这个迭代方程的含义是方程会收敛到一个不动点 ,这里的 就是最终的状态价值函数。逐步迭代,即可完成对策略的评估。
2.3.2 策略改进
在策略评估的基础上,我们可以通过计算 Bellman 最优方程来实现策略改进。 形式为
为了简化计算,可以采用贪心策略,于是策略改进的形式为
这里的计算只需一步即可完成,无需迭代。
2.3.3 完整算法
策略迭代的完整算法是一条迭代链条
策略迭代的完整算法如下
Policy Iteration 算法
| Input: | 策略 ,状态空间 ,动作空间 ,奖励函数 ,转移概率 |
| Output: | 最优策略 ,最优状态价值函数 |
| 1: | 初始化策略 和状态价值函数 |
| 2: | repeat |
| 3: | repeat |
| 4: | |
| 5: | for each do |
| 6: | |
| 7: | |
| 8: | |
| 9: | end for |
| 10: | until (策略评估收敛) |
| 11: | policy_stable true |
| 12: | for each do |
| 13: | old_action 当前策略 所选的动作 |
| 14: | |
| 15: | if old_action then |
| 16: | policy_stable false |
| 17: | end if |
| 18: | end for |
| 19: | until policy_stable |
| 20: | 返回 作为 , 作为 |
Example Problem: Cliff Walking
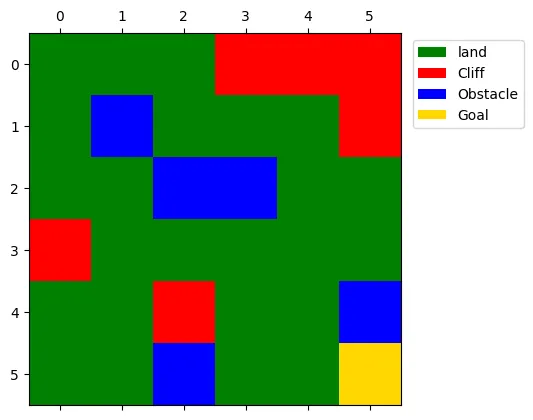
智能体在悬崖上行走,目标是到达终点。智能体可以向上、下、左、右四个方向移动,每次移动的奖励为 -1,如果跌落悬崖,则返回起点,奖励为 -1, 如果到达终点,则奖励为 +1。存在障碍物,智能体不能穿过障碍物。
import numpy as np
from matplotlib.patches import Patch
import matplotlib.pyplot as plt
class GridWorld:
def __init__(self):
self.size = 6
self.terminal = (5, 5)
self.actions = ['up', 'down', 'left', 'right']
self.obstacles = [(1, 1), (2, 2), (2, 3), (4, 5), (5, 2)]
self.cliffs = [(0, 3), (0, 4), (0, 5), (1, 5), (3, 0), (4, 2)]
def is_terminal(self, state):
return state == self.terminal or state in self.cliffs
def get_reward(self, state):
if state == self.terminal:
return 1
else:
return -1
def transition(self, state, action):
if self.is_terminal(state):
return state
row, col = state
new_row, new_col = row, col
# 处理移动
if action == 'up':
new_row = max(row - 1, 0)
elif action == 'down':
new_row = min(row + 1, self.size - 1)
elif action == 'left':
new_col = max(col - 1, 0)
elif action == 'right':
new_col = min(col + 1, self.size - 1)
# 障碍物检测
if (new_row, new_col) in self.obstacles:
return state
# 悬崖处理
if (new_row, new_col) in self.cliffs:
return (0, 0) # 跌落悬崖返回起点
return (new_row, new_col)
env = GridWorld()策略迭代的实现如下
def policy_iteration(env: GridWorld, gamma=0.9, theta=1e-6):
V = np.zeros((env.size, env.size))
V[env.terminal] = 1 # 初始化终点价值
policy = np.full((env.size, env.size), None, dtype=object) # 初始化为None, 确定性动作,非概率性
# 仅对可行动状态初始化策略
for i in range(env.size):
for j in range(env.size):
state = (i, j)
if not env.is_terminal(state) and state not in env.obstacles:
policy[i][j] = 'right' # 初始策略
policy_improvement_iters = 0
policy_evaluation_iters = 0
while True:
policy_improvement_iters += 1
# 策略评估
eval_iters = 0
while True:
eval_iters += 1
delta = 0
for i in range(env.size):
for j in range(env.size):
state = (i, j)
if env.is_terminal(state) or state in env.obstacles:
continue
old_v = V[i][j]
action = policy[i][j]
next_state = env.transition(state, action)
reward = env.get_reward(next_state)
V[i, j] = gamma * V[next_state] + reward
delta = max(delta, abs(old_v - V[i][j]))
if delta < theta:
break
policy_evaluation_iters += eval_iters
# 策略改进
policy_stable = True
for i in range(env.size):
for j in range(env.size):
state = (i, j)
# 设置特殊位置的策略为None
if env.is_terminal(state) or state in env.obstacles:
policy[i][j] = None
continue
old_action = policy[i][j]
max_value = -np.inf
best_action = old_action
for action in env.actions:
next_state = env.transition(state, action)
reward = env.get_reward(next_state)
value = reward + gamma * V[next_state]
if value > max_value:
max_value = value
best_action = action
policy[i][j] = best_action
if old_action != best_action:
policy_stable = False
if policy_stable:
break
print(f"策略迭代: 改进次数={policy_improvement_iters} 评估总次数={policy_evaluation_iters}")
return V, policy
def print_policy(policy):
direction_symbols = {
'up': '↑',
'down': '↓',
'left': '←',
'right': '→',
None: '■'
}
print("策略可视化:")
for row in policy:
print(" ".join([direction_symbols[a] for a in row]))
env = GridWorld()
print("=== 策略迭代 ===")
V_pi, policy_pi = policy_iteration(env)
print("价值函数:\n", np.round(V_pi, 2))
print_policy(policy_pi)2.4 Value Iteration
策略迭代的缺点是需要两次迭代,分别是策略评估和策略改进。我们可以将这两步合并为一步,称为价值迭代。价值迭代的核心思想是使用 Bellman 最优方程来直接更新状态价值函数 ,而不是使用策略评估来更新状态价值函数 。
迭代公式为
此公式的收敛点为最优状态价值函数 。
Value Iteration 算法
| Input: | 状态空间 ,动作空间 ,奖励函数 ,转移概率 |
| Output: | 最优状态价值函数 ,最优策略 |
| 1: | 初始化状态价值函数 |
| 2: | repeat |
| 3: | |
| 4: | for each do |
| 5: | |
| 6: | |
| 7: | |
| 8: | end for |
| 9: | until |
| 10: | 根据 确定最优策略 |
| 11: | 返回 作为 , 作为最优策略 |
def value_iteration(env, gamma=0.9, theta=1e-6):
V = np.zeros((env.size, env.size))
V[env.terminal] = 1
value_iters = 0
while True:
value_iters += 1
delta = 0
for i in range(env.size):
for j in range(env.size):
state = (i, j)
if env.is_terminal(state) or state in env.obstacles:
continue
old_v = V[i][j]
max_value = -np.inf
for action in env.actions:
next_state = env.transition(state, action)
reward = env.get_reward(next_state)
value = reward + gamma * V[next_state]
max_value = max(max_value, value)
V[i][j] = max_value
delta = max(delta, abs(old_v - V[i][j]))
if delta < theta:
break
# 提取策略(特殊位置设为None)
policy = np.full((env.size, env.size), None, dtype=object)
for i in range(env.size):
for j in range(env.size):
state = (i, j)
if env.is_terminal(state) or state in env.obstacles:
continue
max_value = -np.inf
best_action = None
for action in env.actions:
next_state = env.transition(state, action)
reward = env.get_reward(next_state)
value = reward + V[next_state] * gamma
if value > max_value:
max_value = value
best_action = action
policy[i][j] = best_action
print(f"价值迭代: 总次数={value_iters}")
return V, policy
def print_policy(policy):
direction_symbols = {
'up': '↑',
'down': '↓',
'left': '←',
'right': '→',
None: '■'
}
print("策略可视化:")
for row in policy:
print(" ".join([direction_symbols[a] for a in row]))
env = GridWorld()
print("\n=== 价值迭代 ===")
V_vi, policy_vi = value_iteration(env)
print("价值函数:\n", np.round(V_vi, 2))
print_policy(policy_vi)2.5 Questions
2.5.1 在价值迭代中,为什么不需要显式地维护一个策略?
解:
- 原始BOE的形式为
由于采用状态价值迭代时贪心策略一定可以得到最优状态价值,(, 这里的不依赖于, 因此可以给最大的对应动作赋概率)因此, 价值迭代的BOE是
这里对动作遍历,把直接变成是因为这里采用了贪心策略。由此可见,公式中的计算并没有显式的要求计算出每一步的最优策略(实际上也不需要因为这里采用的就是贪心策略,已知),因此可以不需要显式地维护一个策略。
- 由于采用了贪心策略,因此从每步的状态价值函数中提取出最优动作,可以由下式得出
2.5.2 策略迭代和价值迭代的主要区别是什么?在什么情况下应选择使用策略迭代而不是价值迭代?
解:
策略迭代分为策略评估和策略改进两个部分交替进行,收敛速度相对较慢;价值迭代则只需要不断更新状态价值函数即可,收敛速度相对较快。此外,由于策略迭代中每一步得到的状态价值函数都是基于给定策略求得的,因此是真实的有意义的状态价值函数;而价值迭代过程中的状态价值不一定满足Bellman方程(尚未收敛),因此其对应的价值函数未必具有对应于某个策略的意义。
当状态空间较小时(计算成本低),或者需要准确的中间迭代过程的策略和状态函数时,选用策略迭代更合适。