

4.1 从 DP 和 MC 到 TDL
时序差分学习 (Temporal-Difference Learning) 无疑是强化学习中最核心的方法之一,它结合了 Dynamic Programming 算法 和 Monte Carlo 算法的思想。与 MC 方法类似,TD 方法也是直接从与环境交互的经验中学习策略,而不需要环境的模型。但是,与 MC 不同的是,TD 不需要等待交互的最终结果,因为使用了自举法 (bootstraping),因此可以像 DP 一样基于已得到的其他状态的估计值来更新当前状态的价值函数。
自举法: 就是从不完全的经历样本中学习,利用一个猜测的数据去预测另一个数据
TDL 的特点
- 自举法
- 免模型
- 直接从经历样本中学习
| 方法 | 自举 | 采样 | model-free |
|---|---|---|---|
| DP | ✔ | × | × |
| MC | × | ✔ | ✔ |
| TD | ✔ | ✔ | ✔ |
4.2 方法
4.2.1 价值更新
更新价值函数采用的是估计的回报 和采样的奖励 ,更新方法为
其中, 是TD 目标 (TD Target),而 是 TD 误差 (TD Error)。
对比 MC 的更新方式 ,差异也只要是在于更新的信号上。MC 的误差是 ,实际上,MC 的误差可以由 TD 的误差表示
至于解释放在后面的 步自举中说明。
4.2.2 策略估计
TD(0) 算法
| Input: | 策略 , 步长 |
| 1: | 任意初始化 |
| 2: | 对于每幕循环 |
| 3: | 初始化 状态 |
| 4: | for 直至终止状态 |
| 5: | 从策略 中 采样动作 |
| 6: | 执行动作 ,观察得到 奖励 和 下一个状态 |
| 7: | 更新价值 |
这个算法反映出来几点
- TD 可以在知道最终结果之前学习,而MC 必须直到每幕结束知道回报后才能学习
- TD 在没有最终结果时可以学习,因此 TD 方法既可以用于连续型任务,又可以用于分幕式任务,而 MC 只能用于分幕式任务
4.2.3 偏差与方差
MC 方法是高方差、零偏差的学习方法
- 回报 是对 的无偏估计,但是具有较高的方差(因为涉及到很多的随机变量,且这些随机变量之间是相互独立的,因此方差直接累加了)
- MC 方法有良好的收敛性能,且对于初始价值不敏感
- MC 没有使用 Markov 属性,因此在 非 Markov环境中更有效
TD 方法是低方差、但有一些偏差
- TD 目标 也是 的无偏估计(前提是 得无偏),但是方差很低
- TD 方法对初始价值敏感
- TD 使用了 Markov 属性,因此在 Markov环境中更有效
4.3 时序差分控制
将TD方法运用到控制中,可以让智能体每做出一个动作,就对应的进行学习改进策略。时序差分控制仍然遵循广义策略迭代 (GPI) 的模式,在评估和预测的部分都使用时序差分方法。类似 MC 方法,需要在 Explore 和 Exploit 之间做出权衡,因此方法也同样分为on-policy 和 off-policy 两类。
4.3.1 SARSA
SARSA 是一个 on-policy 方法,它所使用的价值函数是动作价值函数,更新方式为
每当从非终止状态的 出现一次转移之后,就进行上面的一次更新。如果涉及到了是终止状态,那么就把终止状态对应的动作价值函数设置为 ,例如,若 是终止状态,那么就让 。由于这个更新方式涉及到了五元组 ,因此这个方法被命名为 SARSA,代表这个五元组的每个元素分别是 状态-动作-奖励-状态-动作。
SARSA Control 算法
| Input: | 步长 , |
| 1: | 任意初始化动作价值函数 ,其中 |
| 2: | 对每幕数据 |
| 3: | 初始化状态 |
| 4: | 使用从 得到的策略 (例如 -greedy),在 处选择动作 |
| 5: | for |
| 6: | 执行动作 ,观察到 |
| 7: | 使用从 得到的策略(例如 -greedy),在 处选择动作 |
| 8: | |
| 9: | 若 是终止状态,则终止当前幕的 for 循环 |
4.3.2 Q-Learning
Q-Learning 是一个 off-policy 方法,其定义为
这里,待学习的动作价值函数 采用了对最优动作价值函数 的直接近似作为学习目标,而与用于生成智能体决策序列轨迹的行动策略无关。它的 TD 目标是 。这个迭代的方式不需要在 时刻的动作选择 ,简化了迭代过程。
Q-Learning Control 算法
| Input: | 步长 , |
| 1: | 初始化动作价值函数 ,其中 |
| 2: | 对每幕 |
| 3: | 初始化状态 |
| 4: | for |
| 5: | 使用从 得到的策略 ( 例如 -贪心 ),在 处选择动作 |
| 6: | 执行动作 ,观察得到 |
| 7: | |
| 8: | 若 是终止状态,则停止 for 循环 |
Q-Learning 显然是 off-policy 方法,因为它使用的动作策略和目标策略不同
- 动作策略是一个 ε-贪心 的策略
- 而目标策略则是 贪婪 策略
Q-Learning 虽然是 off-policy 方法,但是不需要对经验 做重要性采样
- 重要性采样的目的是修正不同策略之间的概率偏差
- Q-Learning 的更新目标是 ,相当于是对
的 Monte Carlo 估计,可以发现这里的期望积分实际上只涉及下一个状态 而不包含动作 ,那么在 当前动作 和状态 均已知的条件下,实际上采样只会用到环境模型,而不涉及到策略模型,有因此无需重要性采样。
- 从公式角度也可以看出
4.3.3 期望 SARSA (Expected SARSA)
期望 SARSA 的更新公式非常类似 Q-Learning 或 SARSA, 就是把 Q-Learning 的动作价值最大化改为了求期望。相较于 SARSA 也就是替换了在下一步状态 下一步动作 的价值函数为对动作求期望的动作价值函数,因此被命名为 期望 SARSA。当引入了 -贪心且行为策略和目标策略一致时,期望 SARSA 是 on-policy 方法。
当采用了探索性的行为策略和贪心的目标策略时,期望 SARSA 是 off-policy 方法。此时的更新公式仍然为
这里没有重要性采样的原因与 Q-Learning 中没有重要性采样的原因相同,也因此更新公式与前述公式相同。
算法形式与 SARSA 或 Q-Learning 相同,只需要替换更新公式即可。
4.3.4 Double Q-Learning
最大化正偏差问题
最大化正偏差(Maximization Positive Bias)是指在强化学习(尤其是值函数估计方法如Q-learning)中,由于使用最大化(max)操作来选择动作或估计未来回报,导致对真实期望值系统性高估的现象。最大化偏差的数学本质如下。假设动作的真实 Q 值 与估计 Q 值 满足:
其中 是独立同分布的噪声,且 ,方差为 。这里 是随机变量而 是确定量。
对于下一状态 ,最大化操作的结果为:
由于最大值函数是凸函数,根据Jensen不等式:
因此, 的期望会高估真实的最大Q值,导致更新目标被系统性抬高。
此外,由于 TD 等方法在学习过程中使用了自举法,即对状态 的价值估计是基于其他状态 之上的。如果其他的状态估计存在有最大化偏差的问题,那么对当前状态 的估计也会相应的有最大化偏差。也就是说,自举法实际上加剧了这种正偏差。
影响与后果
高估问题(Overestimation):
- Q值的持续高估可能导致策略选择次优动作。
- 例如,在存在多个动作的情况下,某个次优动作的Q值可能因噪声被高估,导致智能体错误地偏好该动作。
收敛稳定性下降:
- 高估偏差可能使Q值更新过程震荡,尤其是在函数近似(如深度Q网络)中,可能导致训练不稳定。
4.3.5 双 Q 学习消除最大化偏差
将样本分为两个集合,独立学习得到两个动作价值 和 ,让 选择最大价值的动作,用 计算动作价值估计。然后交换 和 的角色,再进行更新。
Double Q-Learning 算法
| Input: | 步长 , |
| 1: | 初始化两个动作价值函数 和 ,其中 |
| 2: | 对每幕循环 |
| 3: | 初始化状态 |
| 4: | for |
| 5: | 基于 ,使用 ε-贪心策略在 选择动作 |
| 6: | 执行动作 , 观察得到 , |
| 7: | 以 的概率执行 |
| 8: | |
| 9: | 或者执行 |
| 10: | |
| 11: | 若 是终止状态,则终止当前幕的 for 循环 |
可以看出来,双 Q 学习就是利用两个动作价值函数同时进行学习。用其中一个动作价值函数来选择最优动作,然后用另一个动作价值函数来估计这个动作的价值,再更新第一个动作价值函数的动作价值。
双Q学习可以减弱最大化偏差问题(注意不是消除),因为当采用了两个动作价值函数的时候,只要 选择的动作对应的在 中的动作价值没有被高估,就不会出现最大化偏差的问题。
4.4 n 步自举法 (n-step Bootstrapping)
单独的 MC 方法或 TD 方法都不会总是最好的方法。 步时序差分方法是这两种方法更一般的推广,在这个框架下可以更加平滑地切换这两种方法。
4.4.1 方法
考虑在固定策略 下利用多幕采样序列估计 的情况。 Monte Carlo 方法是根据从某一状态开始到终止状态的收益序列,对这个状态的价值进行更新。而时序差分方法则只根据后面的单个即时收益,在下一个后继状态的价值估计值的基础上进行自举更新。考虑一种介于两者之间的方法——采样 步的奖励,然后在 第 步进行自举。
步回报定义为
作为 步时序差分的 TD 目标用于更新。
步时序差分 (TD (n)) 的更新公式为
其中 代表第 个时间步时的价值函数,因为价值函数在每步都在迭代,且这种迭代是具有延迟效应的,即 第 个 时间步的状态 的价值函数需要等待 个时间步才能更新。还有一个需要注意的点是,更新时所用的基线是 而不是 , 这是因为相较于 , 更新更准确。采用后者会更加的合理,能减少误差,使价值函数收敛到正确的预测。
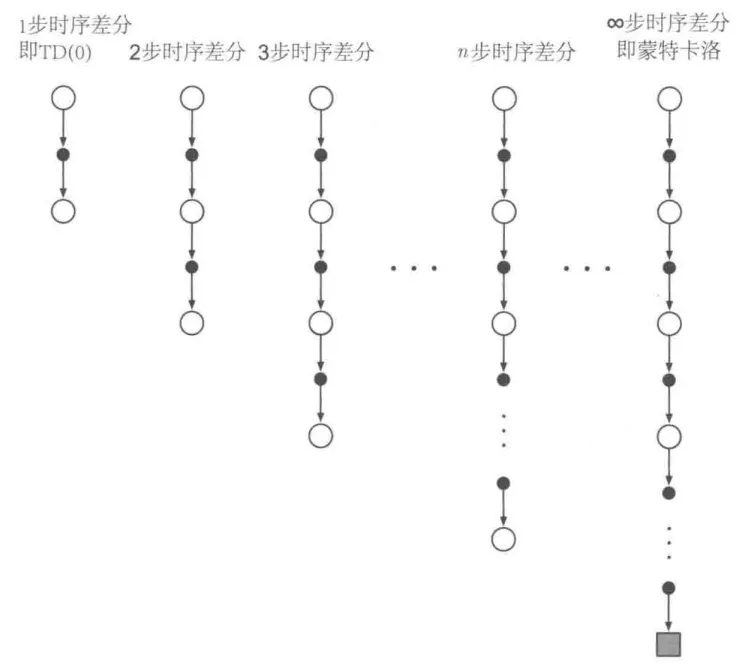
TD(n) 算法
| Input: | 策略 ,步长 ,正整数 |
| Output: | 状态价值函数 |
| 1: | 任意初始化状态价值函数 |
| 2: | 对每幕循环: |
| 3: | 初始化并存储状态 (非终止状态) |
| 4: | |
| 5: | for do |
| 6: | if then |
| 7: | 根据 采样动作 |
| 8: | 执行动作 ,观察 和 ,并存储 |
| 9: | if 是终止状态 then |
| 10: | end if |
| 11: | (当前正在更新的状态时刻) |
| 12: | if then |
| 13: | |
| 14: | if then |
| 15: | |
| 16: | end if |
| 17: | |
| 18: | end if |
| 19: | if then 终止 for 循环 |
| 20: | end for |
| 21: | end 对每幕循环 |
4.4.2 步 SARSA
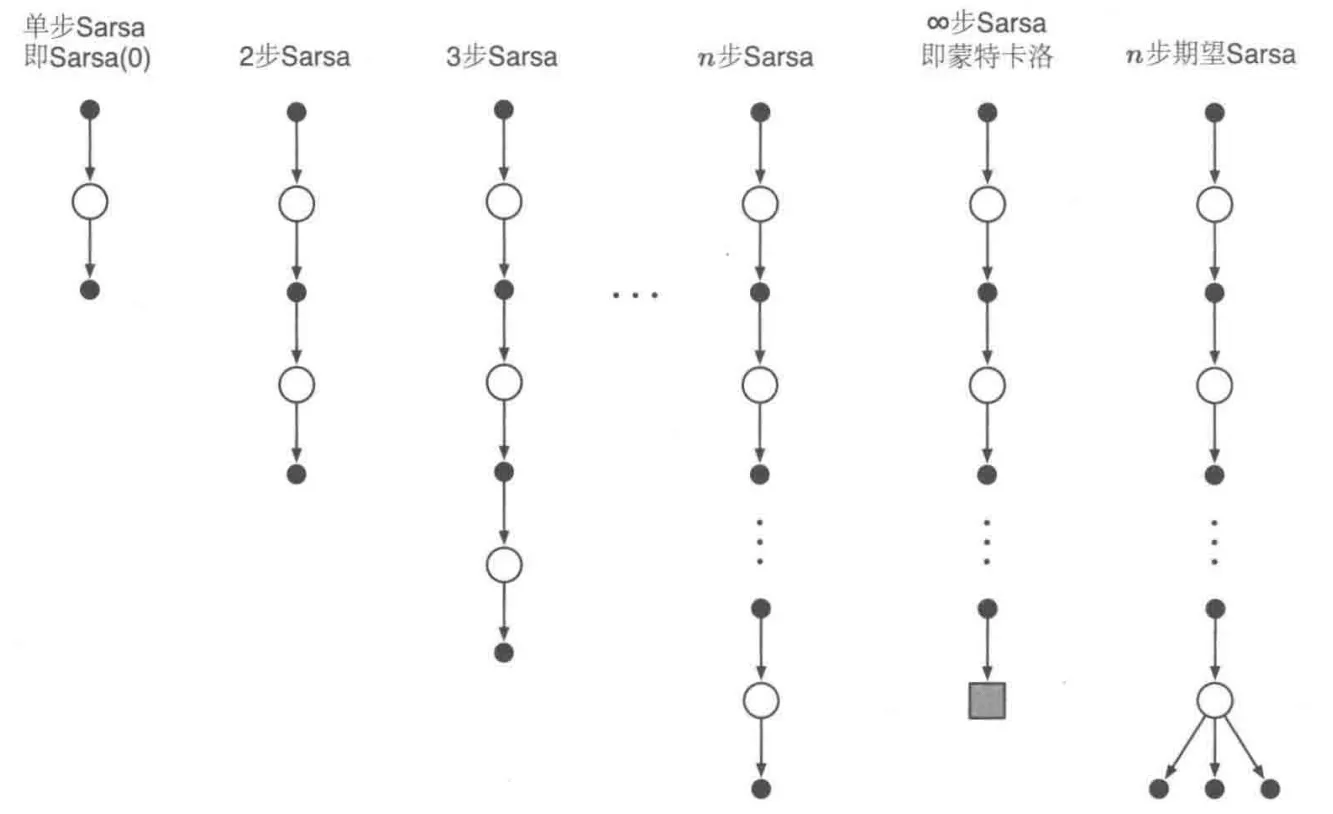
结合 步自举法 和 SARSA,可以得到同轨策略下的时序差分控制方法
类似地,定义 步 回报为
于是 步 SARSA 的更新公式为
符号表示与 类似, 表示第 步时的动作价值函数。
n-step SARSA Control 算法
| Input: | 步长 ,正整数 |
| 1: | 将 初始化为对应 的 -greedy 策略,或者某个固定的给定策略 |
| 2: | 对每幕循环: |
| 3: | 初始化并存储状态 (非终止状态),并选择和保存动作 |
| 4: | |
| 5: | for do |
| 6: | if then |
| 7: | 执行动作 ,观察 和 ,并存储 |
| 8: | if 是终止状态 then else 选择并存储动作 |
| 9: | end if |
| 10: | (当前正在更新的状态时刻) |
| 11: | if then |
| 12: | |
| 13: | if then |
| 14: | |
| 15: | end if |
| 16: | |
| 17: | 如果处于学习 的过程中,那么需要确保 是基于 的-贪心策略 |
| 18: | end if |
| 19: | if then 终止 for 循环 |
| 20: | end for |
| 21: | end 对每幕循环 |
步 SARSA 相较于 单步的 SARSA 加速了策略学习。
类似地还有 步期望 SARSA,更新公式为
4.4.3 步离轨策略学习
类似 MC 的离轨策略学习,这里的方法是需要引入重要度重采样率的。
- off-policy
- off-policy 步 SARSA
- off-policy 步 期望 SARSA
其中
4.4.4 步树回溯
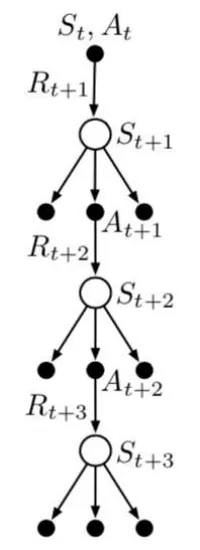 借鉴 Q-Learning 和 期望SARSA 中不使用重要度采样的思想,采用自举构建用于价值函数更新的目标。在回溯树中,顶端节点的价值由沿途所有的收益和底部节点的估计价值组合而成,更新量是从树的叶子节点的动作价值的估计值计算出来的,采样子步骤与期望子步骤交替进行。
借鉴 Q-Learning 和 期望SARSA 中不使用重要度采样的思想,采用自举构建用于价值函数更新的目标。在回溯树中,顶端节点的价值由沿途所有的收益和底部节点的估计价值组合而成,更新量是从树的叶子节点的动作价值的估计值计算出来的,采样子步骤与期望子步骤交替进行。
回报的递归公式为
动作价值更新为