

3D-LLaVA
3D-LLaVA: Towards Generalist 3D LMMs with Omni Superpoint Transformer
 |  |
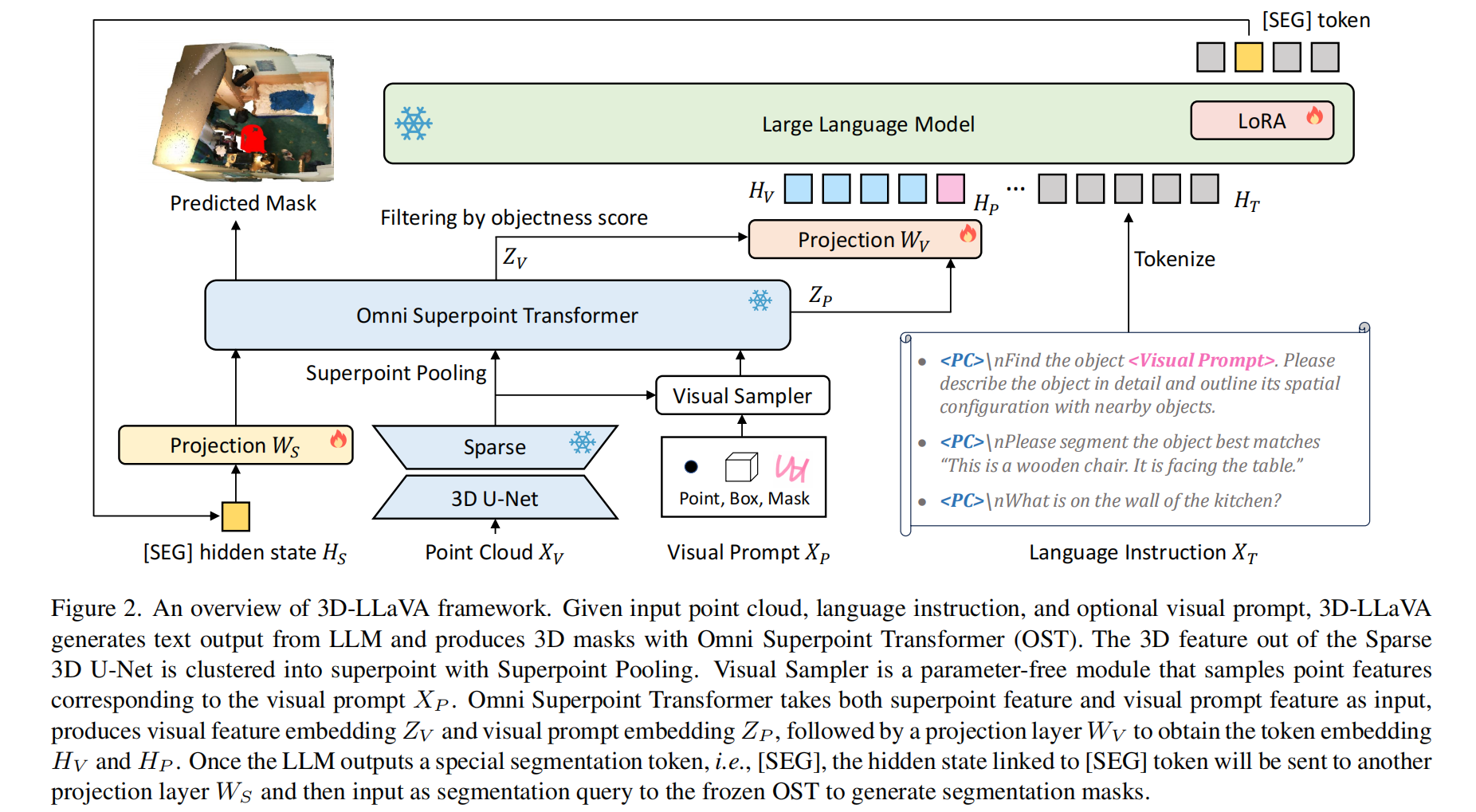
3D-LLaVA 旨在解决现有 3D 多模态模型流程繁琐、功能割裂的痛点,提出了一种极简的一体化架构。 它摒弃了复杂的多视图预处理和独立编码器,仅以点云为输入,通过核心的 Omni Superpoint Transformer (OST) 统一承担视觉特征选择、提示编码与掩码解码三大功能,实现了从 3D 感知到语言推理的端到端贯通。
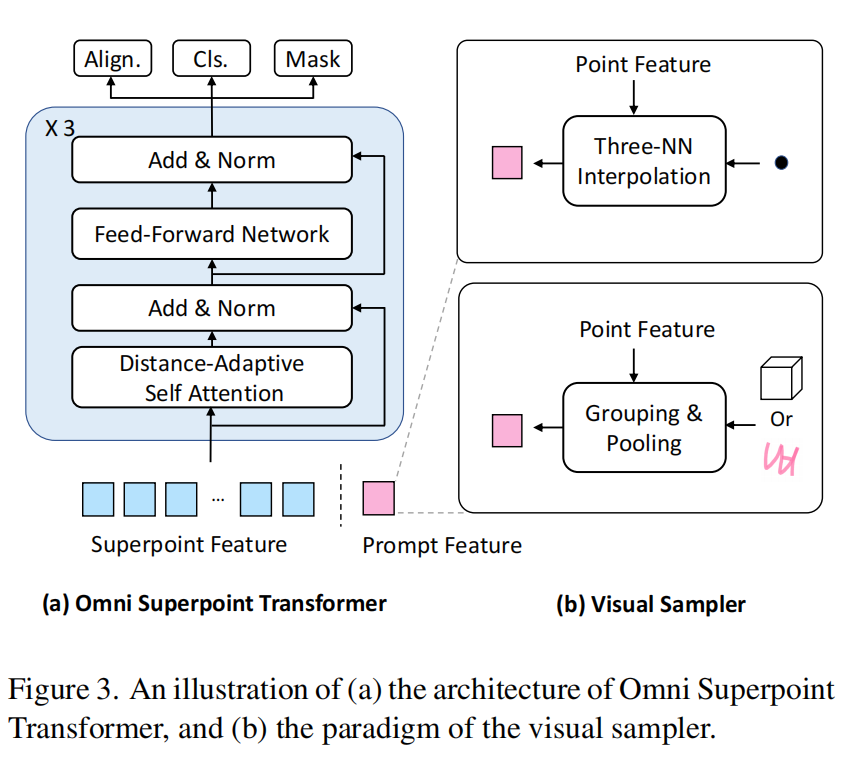
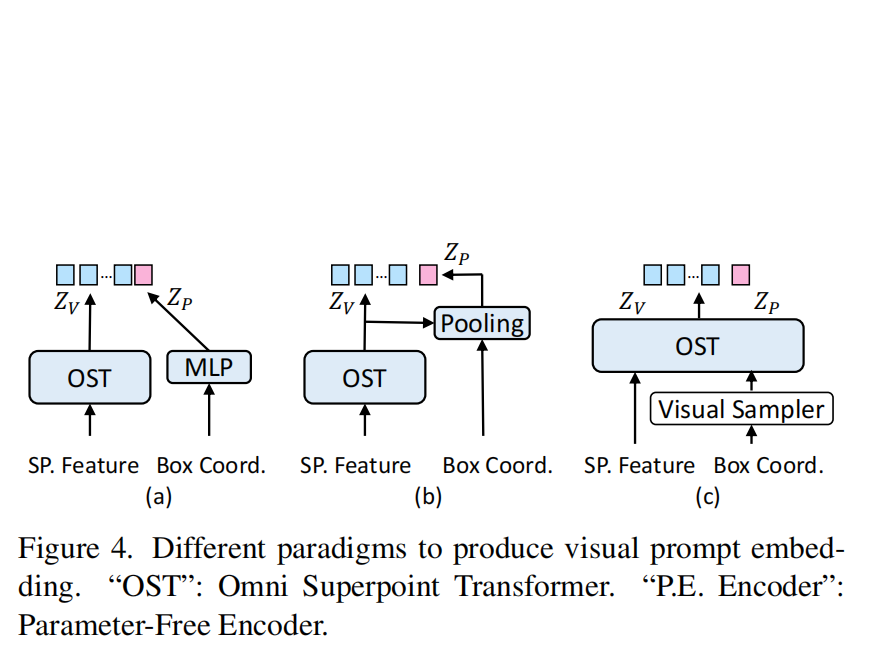
其核心创新在于“超点表示”与“混合预训练”策略的深度融合。 模型先将体素聚类为语义超点以压缩计算量,再利用距离自适应注意力机制增强几何感知;同时,通过联合实例分割任务与 2D-to-3D 知识蒸馏,将强大的 2D 语义先验注入 3D 空间,使生成的视觉 Token 既能被大语言模型理解,又能精准反推 3D 掩码,真正实现了“所说即所割”。
实验结果证明该方案在五大基准数据集上全面刷新 SOTA,且兼具高效性与通用性。 3D-LLaVA 在仅需点云输入的情况下,于 3D 问答 (ScanQA) 和指代分割 (Multi3DRefer) 任务中分别取得 92.6% CiDEr 和 42.7% mIoU 的优异成绩,显著超越依赖复杂多视图特征的竞品;它不仅统一了对话、描述与分割任务,更验证了无需额外模块即可实现高精度 3D 具身智能的可行性。
SGL
A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs
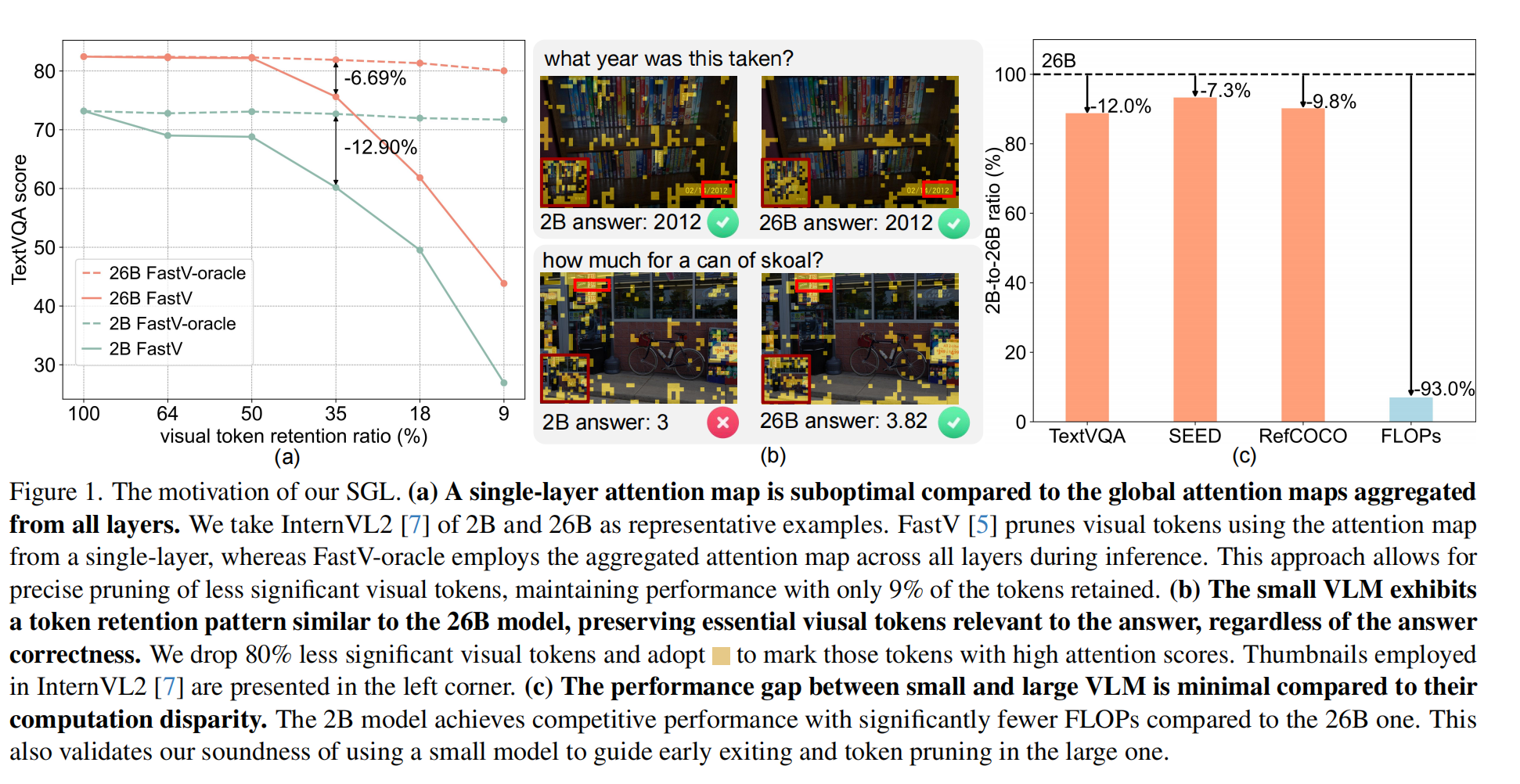
- 当视觉编码器从高分辨率图中提取得到大量的视觉 tokens 作为输入时,会导致 VLMs 面临巨大的推理效率挑战。此前的工作通常从减少视觉 tokens 的角度来解决这一问题。该思路主要分为两个大类:
- 训练类方法需要额外的训练成本。
- 无训练方法考虑做 tokens 的融合或者剪枝,但是简单的融合机制或者剪枝可能带来严重的性能下降。
- 近期的方法是无训练方法的一个分支——利用 VLMs 的中间层注意力图来评估 token 重要性并动态剪枝。这类方法中,仅通过单层的注意力图不足以准确识别关键的视觉 tokens,而对整体的注意力图做聚合又导致推理开销的增加。
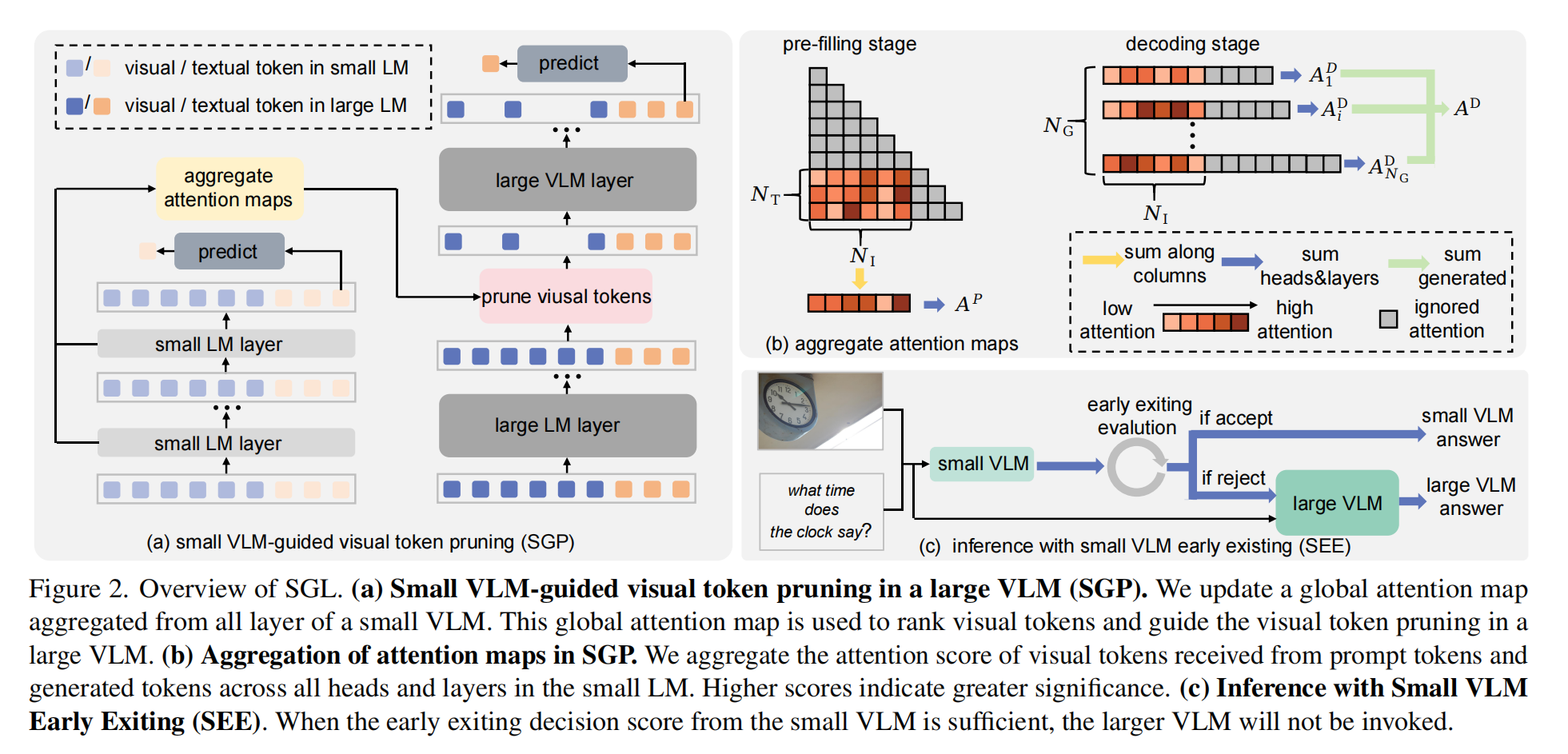
- 基于以上背景,本文提出了 SGL 方法,通过引入一个小型的 VLMs 模型并利用它的全局注意力图(由多个注意力图聚合而来)来指导视觉 tokens 剪枝。这里是利用到了实验验证的结论——小型 VLMs 的全局注意力图和大型 VLMs 的全局注意力图是十分接近的。SGL 有两个模块:
- SGP 模块首先让一个小型 VLM 运行给定的输入,聚合该小型模型的所有头的注意力图(包括 prefilling 阶段 prompt 对 visual tokens 的注意力和解码阶段 generated tokens 对 visual tokens 的关注),计算出每个视觉 token 的综合得分,然后将得分低的 token 剪掉。
- SGL 模块的设计则是考虑到既然小型的 VLM 都已经推理一次了,那么推理阶段的结果就不要浪费了。计算小型模型输出结果的决策分数 (置信度 (模型对自己输出的信任程度)和一致性分数 (剪枝前后输出结果的比对) 的平均值);如果决策分数超过某个阈值,则直接使用小模型的输出结果,否则才使用大模型(输入裁剪后的 tokens)的输出结果。
- 可以实现,在视觉token保留率仅为 9% 的情况下(即剪掉了91%的token),SGL方法仍能保持大模型原始性能的 89%-96%。非常工程化的一项工作。
A Few Heads For Visual Grounding
Your Large Vision-Language Model Only Needs A Few Attention Heads For Visual Grounding
 | 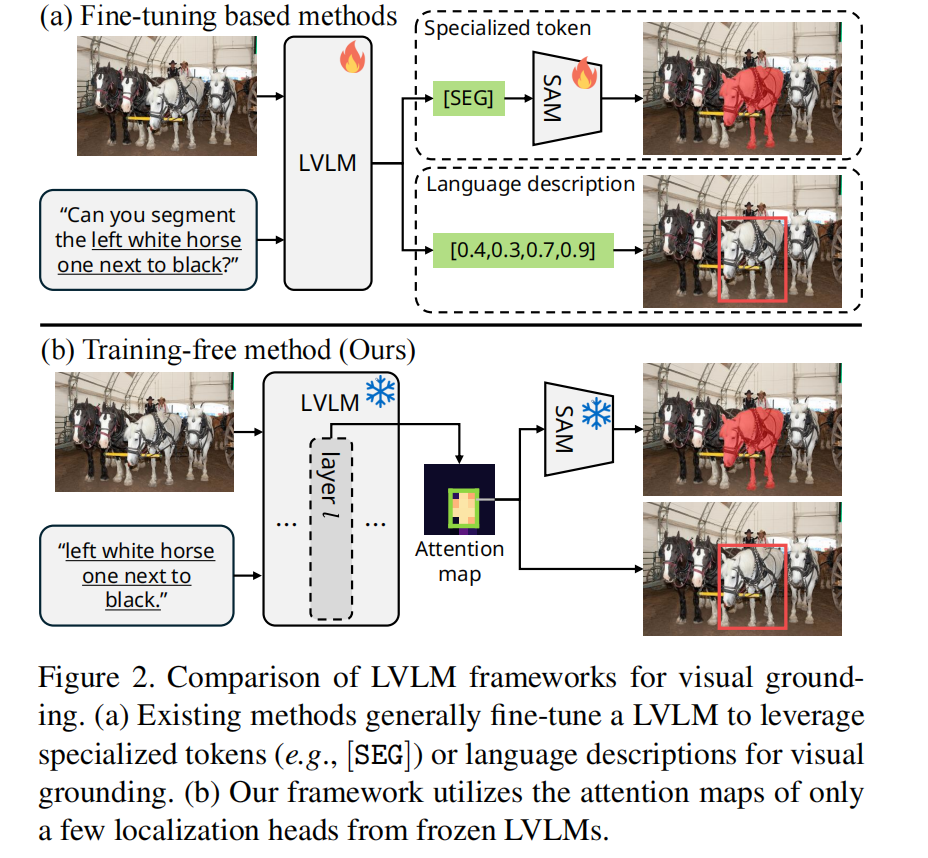 |
现有利用 VLM 做 visual grounding 的方法大多需要在视觉定位数据集上微调模型,或添加额外的定位组件(如边界框生成器、分割解码器),这无疑增加了模型复杂度和训练成本。本篇论文发现,冻结的原始 VLM 模型其实已经隐含了 grounding 的能力,可以实现无需任何微调即可用于 visual grounding。
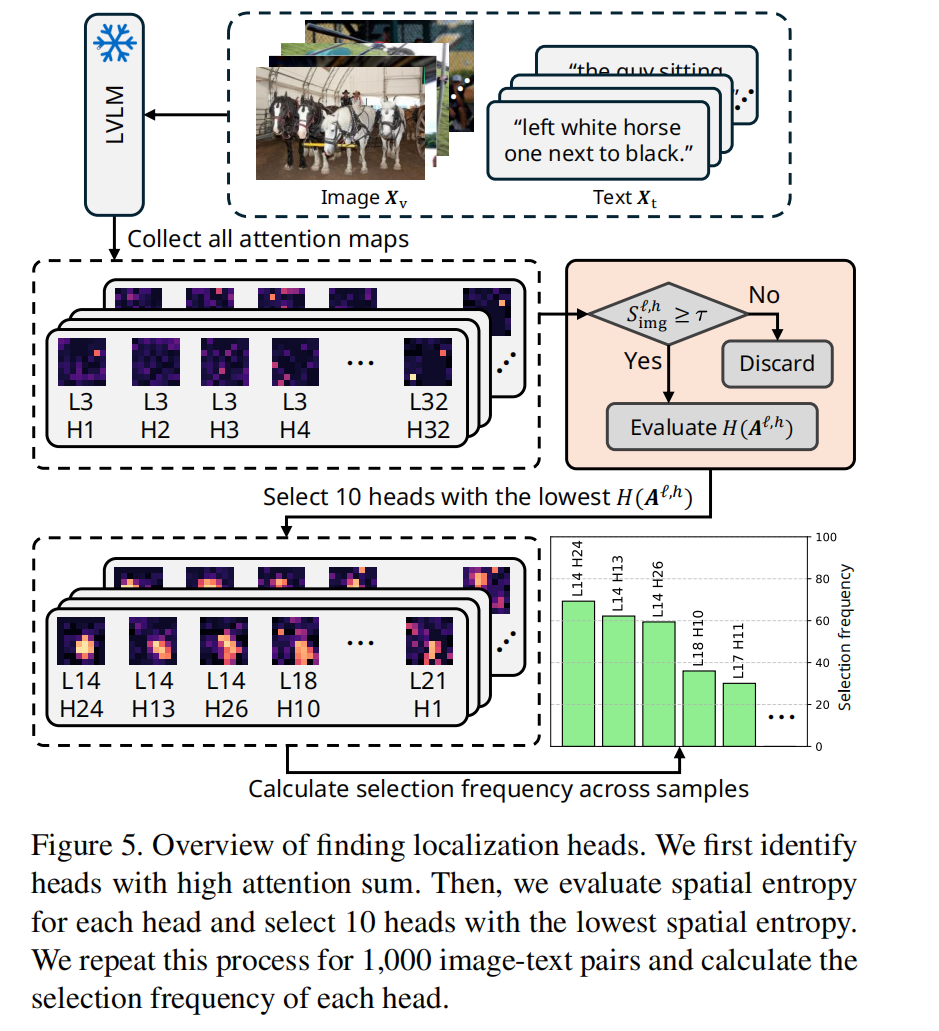
为了筛选合适的注意力头,论文提出了注意力总和和空间熵两个量化准则。需要注意的是,本文中的所有注意力图计算都是基于最后一个 text token 对所有 image tokens 的注意力图。
- (1) 注意力总和准则: 最后一个文本 token 对所有图像 token 的注意力总和,其中 分别表示头的层数序号和头数序号, 是展平的注意力图 :
- (2) 空间熵准则: 筛选注意力分布集中而非分散的头,通过计算注意力图的空间熵值,识别低空间熵的头。其中 根据 8 邻域原则发现的二值化的注意力图中的值为 1 的连通区域集合,二值化的注意力图是将注意力图中值高于平均值的位置置为 1,其他位置置为 0 得到的。
联合筛选:最终定位头需同时满足 高于阈值,且自身的 排名属于最低的前若干个头。
在多个数据集的指代理解和指代分割任务上,该方法性能与需要微调的方法相当或接近,显著优于其他免训练方法。定位头在同一模型架构内具有较好通用性,跨任务跨数据集均有效,但不同架构模型需重新筛选定位头。核心结论是冻结 VLM 内部已隐含视觉定位能力,正确提取注意力图即可实现有效定位。
评分说明:本文单看论文思路确实是一篇清晰且简单有效的工作,可以评到 4 分,但是考虑到代码没有开源,实验结果可复现性未知,暂时评到 3 分。
Words or Vision
Words or Vision: Do Vision-Language Models Have Blind Faith in Text?
随着视觉-语言模型(VLMs)在复杂多模态任务中的广泛应用,模型经常面临视觉信息与文本输入不一致的场景(如钓鱼网站中的虚假品牌描述)。然而,现有研究多关注视觉中心任务,忽视了模型在处理跨模态冲突时的行为。本文指出,当前主流VLMs普遍存在“文本盲目信任”(Blind Faith in Text)现象:当图像内容与伴随的文本信息发生冲突或文本具有误导性时,模型倾向于忽略视觉证据而过度依赖文本,这不仅导致性能大幅下降,更带来了严重的安全隐患。
为了解决这一问题,作者首先从理论层面提出解释,认为训练数据中纯文本数据量远大于多模态数据量(),导致模型在优化过程中更倾向于最小化纯文本损失,从而形成对文本的偏好;同时,实验发现输入序列中文本Token位于图像Token之前也会加剧这种偏见。针对此,论文提出了两种缓解方案:一是简单的指令提示(效果有限);二是基于监督微调(SFT)的改进方法,通过构建包含“匹配”、“冲突(损坏)”和“无关”三种文本变体的混合数据集,并保留部分纯文本数据以维持语言能力,对模型进行针对性微调,教会模型在模态冲突时正确权衡视觉与文本信息。
实验结果显示,未经调整的开放权重模型(如LLaVA、Qwen)在面对误导性文本时,准确率下降幅度高达50%-64%,且文本偏好率(TPR)普遍超过50%;相比之下,部分专有模型(如Claude)表现较为稳健。经过提出的SFT方法微调后,模型性能显著提升:例如LLaVA-NeXT-7B在冲突条件下的准确率从28.69%跃升至71.25%,宏观平均准确率也大幅提高,成功克服了盲目信任文本的缺陷。此外,研究还发现仅用少量(各1,000样本)冲突数据即可有效纠正模型行为,证明了该方法的样本高效性,同时也验证了保留纯文本数据对于防止模型走向“完全拒绝文本”这一极端的重要性。
AnyAttack
AnyAttack: Towards Large-scale Self-supervised Adversarial Attacks on Vision-language Models
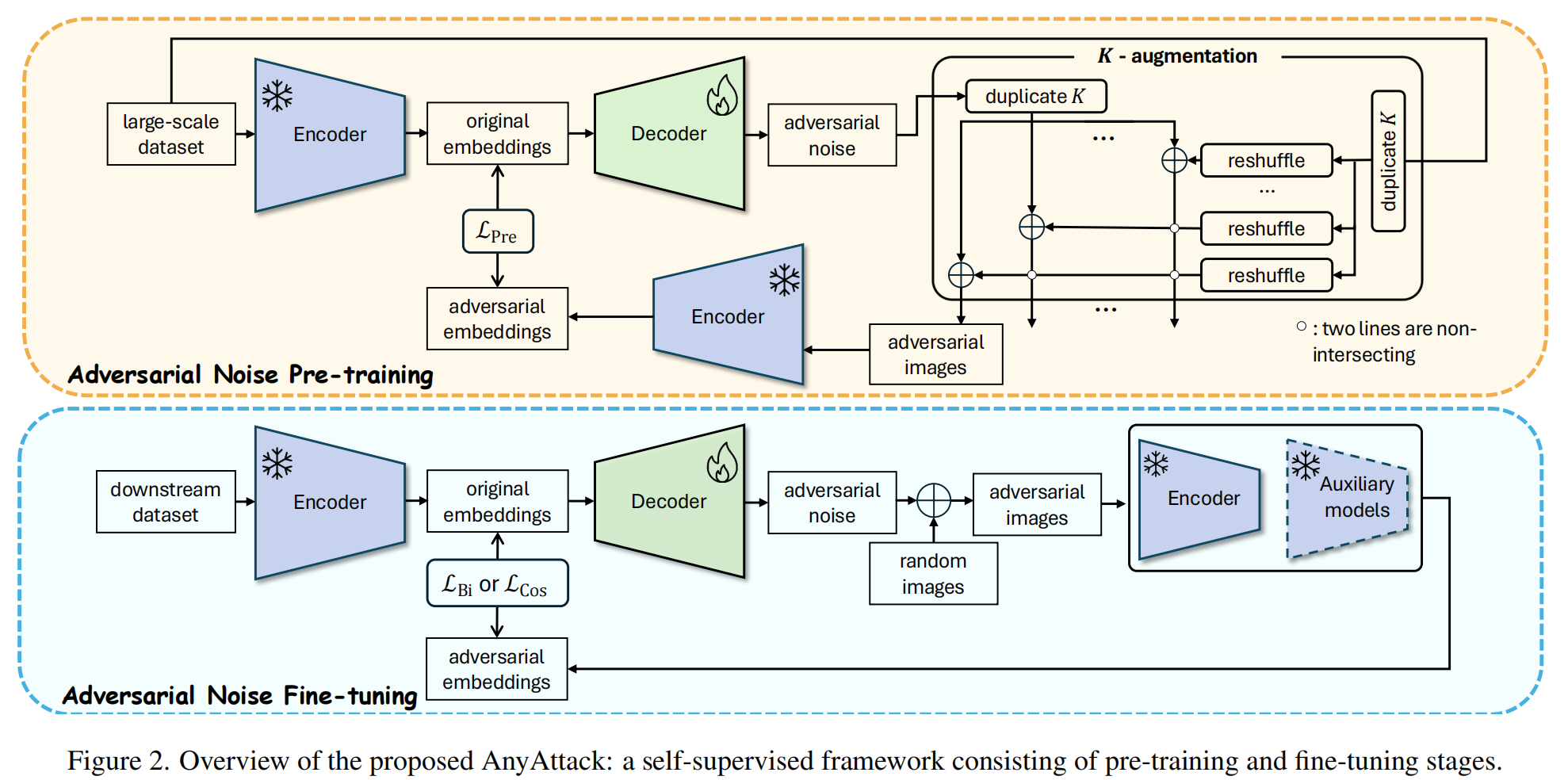
现有的针对视觉 - 语言模型(VLMs)的对抗攻击方法主要依赖于有监督学习,需要特定的目标标签或图像进行训练,这导致其扩展性差、灵活性低,难以利用海量无标签数据,且生成的对抗样本往往缺乏跨模型和跨任务的迁移能力。随着多模态大模型的广泛应用,这种局限性使得现有攻击手段无法充分揭示模型在开放世界中的深层安全漏洞,亟需一种能够大规模自监督训练、具备高度泛化能力且能实现“任意图像到任意输出”攻击的新型框架。
论文提出了 AnyAttack,这是首个将“预训练 + 微调”范式引入有目标对抗攻击的自监督框架。其核心是训练一个噪声生成器,采用两阶段策略:首先在 LAION-400M 等大规模无标签数据集上进行自监督预训练,利用对比学习损失,强制生成器将无关随机图像加上生成的噪声后,在特征空间中对齐到目标原始图像,从而学习通用的对抗噪声模式;随后在特定下游任务数据上进行微调,通过引入双向对比损失和辅助代理模型,进一步适配具体任务并提升黑盒迁移能力。该方法巧妙地将图像内容与对抗噪声解耦,实现了无需目标标签的大规模高效训练。
实验结果表明,AnyAttack 在多个开源 VLMs(如 CLIP, BLIP2, MiniGPT-4)的图像检索、分类和描述任务上,攻击成功率显著优于现有的最先进方法(提升约 15%-18%)。更令人震惊的是其强大的黑盒迁移能力,在完全未知的商业闭源模型(如 GPT-4o, Gemini, Claude Sonnet)上,攻击成功率达到了 30%-40%,而基线方法几乎失效。此外,该方法在保持高攻击性的同时,具备推理速度快、内存占用低的优势,证明了其作为通用对抗攻击基础模型的巨大潜力和现实威胁。
ViLex
Visual Lexicon: Rich Image Features in Language Space
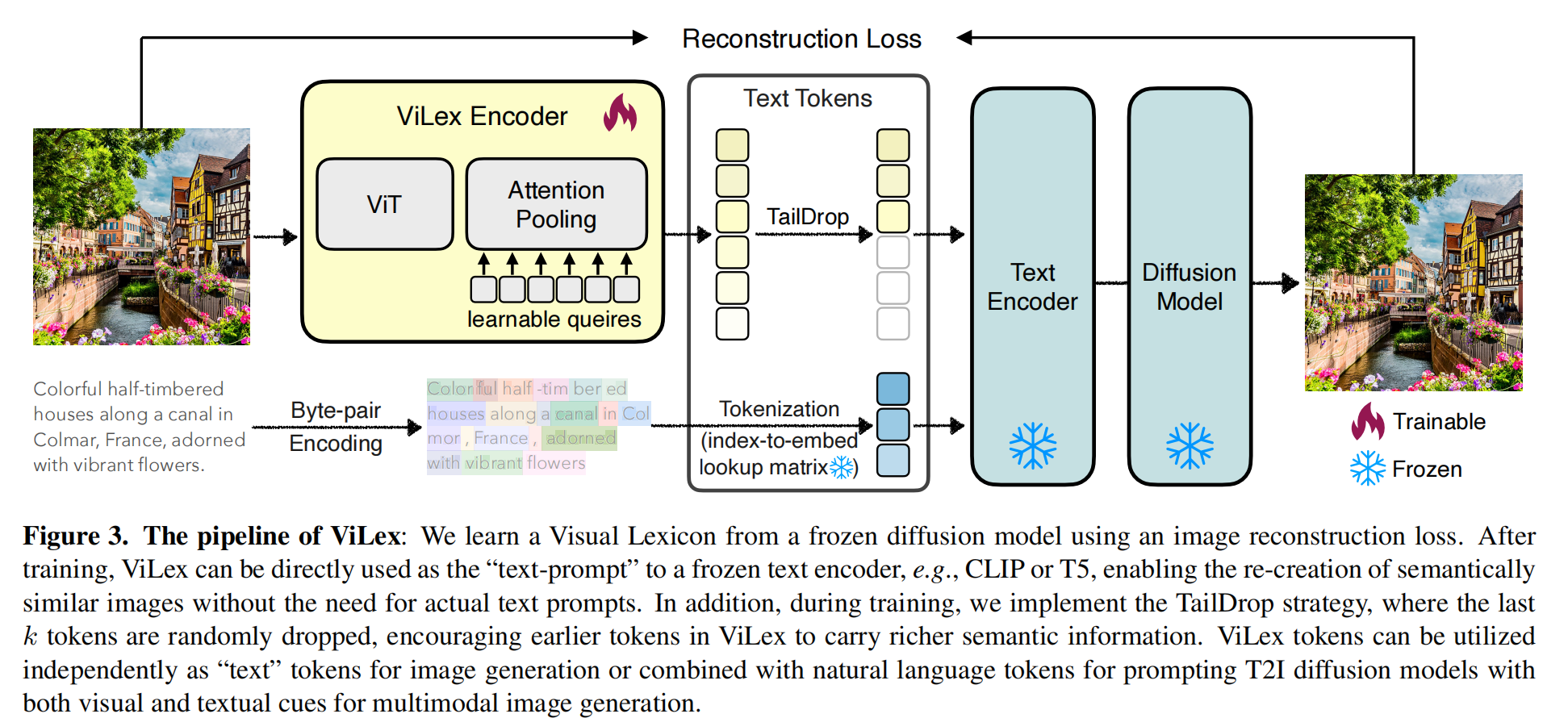

这篇论文直击计算机视觉领域长期存在的“理解”与“重建”难以兼得的痛点。传统的视觉模型往往顾此失彼:擅长语义理解的模型(如 CLIP)在生成图像时会丢失纹理和风格细节,而擅长高保真重建的模型(如 VAE)又缺乏深层的语义表达能力。现有的图像反转技术通常需要对每个图像进行耗时的微调,且无法灵活地将视觉内容与自然语言自由组合。作者的核心目标是寻找一种统一的图像表示法,既能像文本一样具备强大的语义组合性,又能保留丰富的视觉细节,从而同时胜任高质量的图像生成和复杂的视觉理解任务。
为了解决上述矛盾,作者提出了 ViLex(Visual Lexicon)范式,其核心创新在于将图像直接编码到预训练文本到图像(T2I)扩散模型的“文本词汇空间”中。该方法采用自监督的自动编码器架构:使用基于ViT的视觉编码器将图像映射为一系列连续的“视觉 tokens”,这些 tokens 在维度上与冻结的 T2I 模型(如Imagen)的文本嵌入对齐。训练过程中,扩散模型及其文本编码器完全保持冻结,仅通过最小化图像重建损失来训练视觉编码器。此外,作者引入了巧妙的 “TailDrop” 策略,即在训练时随机丢弃序列末尾的部分 tokens,迫使前面的 tokens 学习更核心的语义信息,从而实现从单 tokens 语义概括到多 tokens 细节还原的动态适应。
实验结果显示,ViLex在生成和理解两个维度均取得了突破性进展。在图像生成方面,即使仅使用1个视觉 tokens ,其重建质量也优于现有的离散化方法;当使用全部 75 个 tokens 时,能够完美还原图像的风格、布局和细微纹理。更重要的是,它实现了零样本的多模态生成,用户可以直接将视觉 tokens 插入自然语言提示中(例如“[视觉 tokens]加上梵高风格”),无需任何微调即可实现物体的重语境化和风格迁移。在视觉理解方面,将ViLex编码器集成到视觉 - 语言模型(如 PaliGemma)中,在15个基准测试上全面超越了强大的 SigLIP 基线,证明了其学到的特征具有极高的语义密度和判别力。
纵观全文,有几个看似“反直觉”的设计实则蕴含深意。首先,作者放弃直接适用 Visual Encoder 生成条件指导向量的路线,而选择从文本空间多绕一次的实现,是为了利用语言模型的通用接口和语义先验,让图像能像单词一样被大模型理解和组合,这是实现“文图无缝融合”的关键。其次,“TailDrop” 策略看似人为制造信息瓶颈,实则是通过课程学习的方式强制模型进行信息分层,确保前几个 tokens 承载核心语义,后几个 tokens 补充高频细节,从而赋予模型灵活的推理能力。最后,仅靠重建损失且冻结解码器就能获得 SOTA 的理解能力,揭示了“生成即理解”的深层逻辑:要驱动强大的冻结扩散模型精确重建,编码器必须提取出最本质的语义特征,这种高强度的重建约束实际上充当了极佳的语义蒸馏过程。
VisionArena
VisionArena: 230K Real World User-VLM Conversations with Preference Labels
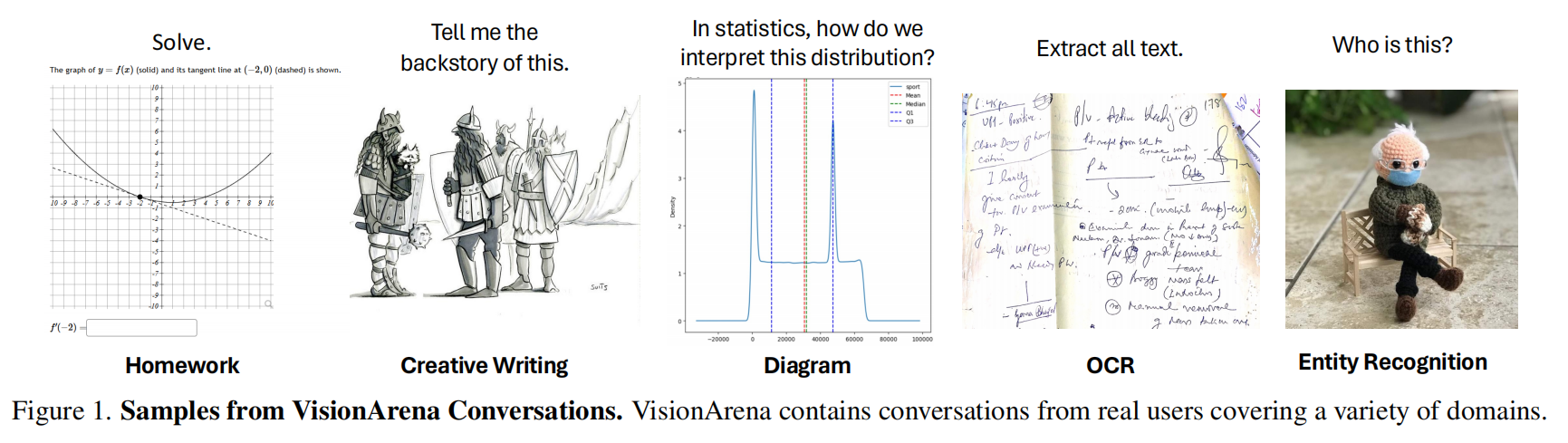
随着视觉语言模型(VLMs)的快速发展,现有的评估基准大多依赖于静态的、有标准答案的单轮任务(如图像描述或选择题),这种方式无法有效捕捉真实世界中用户与VLM交互的开放性、多轮性和主观偏好。这种评估方式与模型的实际应用场景存在巨大脱节,导致我们难以准确衡量VLM在复杂、动态的真实环境中的表现和人类对其的真实满意度。因此,社区亟需一个能够反映 authentic user-VLM interactions(真实的用户-VLM互动)的大规模数据集和评估框架,以推动VLM技术向更符合人类期望的方向发展。
为了解决上述问题,作者提出了 VisionArena,一个包含23万条真实世界用户-VLM对话的数据集。该数据集通过构建一个类似Chatbot Arena的平台收集而来,主要包含三个部分:(1) VisionArena-Chat (200k条),记录用户与指定模型的直接对话;(2) VisionArena-Battle (30k条),记录用户在匿名“对战模式”下对两个模型回答的偏好投票;(3) VisionArena-Bench (500个提示词),一个用于自动化评估的离线基准。在技术细节上,数据收集后经过了严格的清洗流程,包括使用自动化工具过滤不安全内容(NSFW)、移除个人身份信息(PII),并对非英语对话进行了筛选。为了分析用户意图,作者采用BERTopic框架对海量对话进行主题建模和聚类,从而识别出STEM、OCR、创意写作等核心问题类别。此外,他们还利用Bradley-Terry模型处理对战数据中的偏好投票,以生成可靠的模型排行榜。
VisionArena的分析与应用得出了多项重要成果。首先,数据分析揭示了当前VLM的优势与短板,例如模型在处理开放式的幽默和创意写作时高度依赖回复风格,而在需要复杂空间推理的任务上则普遍表现不佳。其次,其衍生的离线基准 VisionArena-Bench 被证明非常有效,它与在线Chatbot Arena官方排行榜的Spearman相关性高达97.3%,表明其能低成本、高效率地预测模型在真实用户中的排名。最后,论文展示了该数据集的巨大实用价值:仅在VisionArena-Chat数据的一个子集上进行微调,就使得Llama-3.2-11B基础模型在MMMU和WildVision等多个权威基准测试上取得了显著提升,性能甚至超越了参数量更大的模型,充分证明了VisionArena数据对于训练高性能、符合人类偏好的VLM具有关键作用。
IP-CLIP
Vision-Language Model IP Protection via Prompt-based Learning
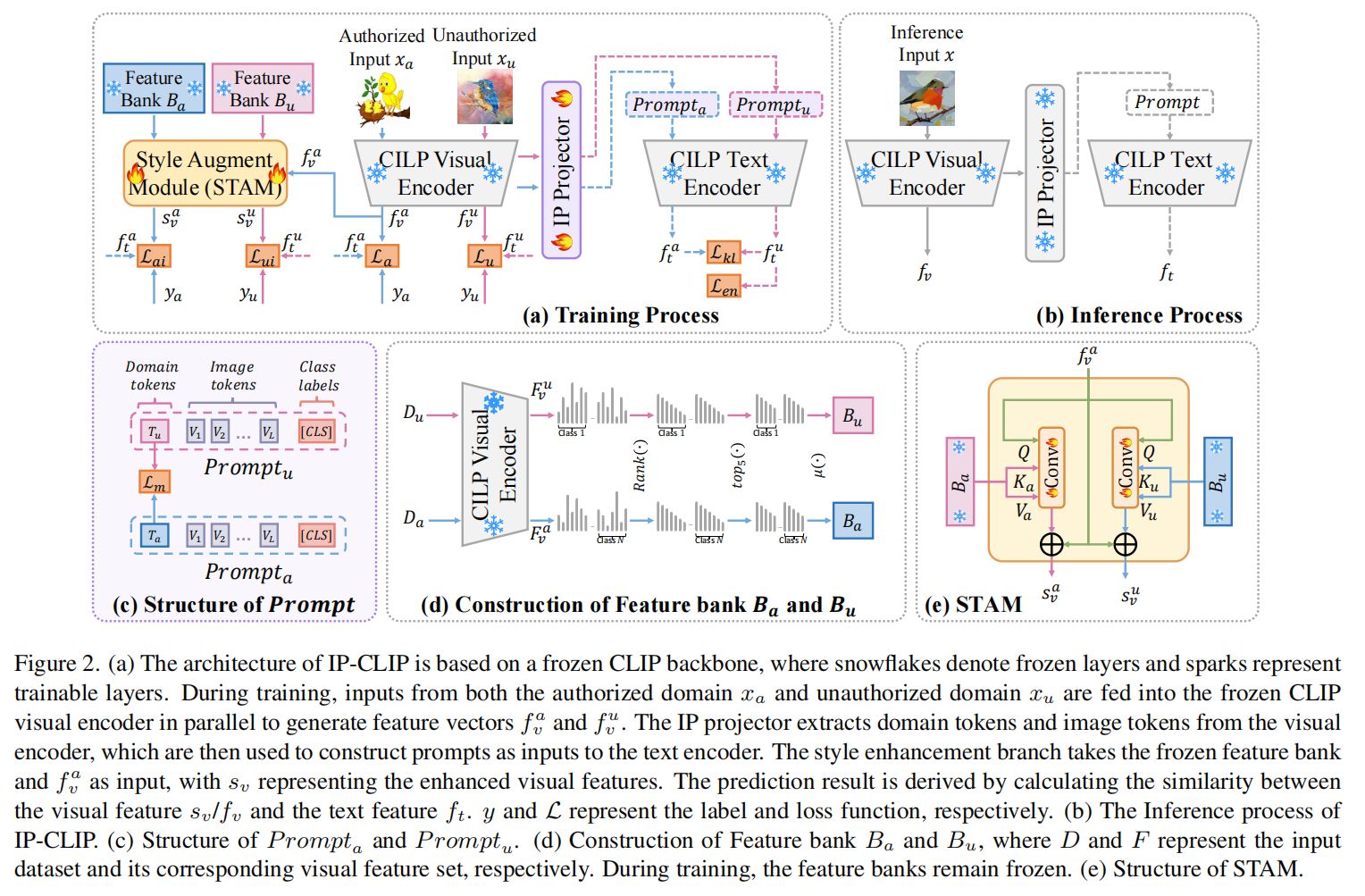
随着视觉 - 语言模型(如 CLIP)商业价值飙升,高昂的训练成本使其面临严重的知识产权侵权风险,特别是攻击者容易将授权模型非法迁移到未付费的特定数据域(如不同风格或场景)中使用;然而,现有的保护方法往往需要全量微调巨大模型导致成本过高,或缺乏对多模态语义的有效利用,难以在低开销下实现精准的“域锁定”。
论文提出 IP-CLIP 框架,采用参数高效的提示学习(Prompt-based Learning)策略,在冻结 CLIP 主干网络的前提下,仅通过训练轻量级的 IP-Prompt 模块来实现保护;该模块包含一个风格增强分支,利用特征库和注意力机制提取图像的域风格特征,生成特定的“域 Token”拼接到文本提示中,引导模型在授权域正常分类,而在检测到非授权域风格时故意输出错误预测或大幅降低性能。
在多个跨域数据集(如 Office-Home, DomainNet)上的实验表明,IP-CLIP 能以极低的计算成本(仅更新极少参数),在几乎不损失授权域性能(准确率下降 < 1%)的同时,使模型在非授权域上的准确率显著崩塌(大幅下降至随机水平);其综合保护指标优于现有非迁移学习基线,证明了该方法能有效防止模型被非法跨域滥用,且具备部署灵活性。
这篇文章的想法就是对于输入的图片,用一个 prompt 生成器去根据输入图片是否是授权的内容,来选择是增强文本 prompt 以增强类别识别,还是生成一个误导性的 prompt 来欺骗模型,从而导致分类识别失败。利用误导性 prompt 确实是一个经典且不错的方法,但是任务本身的价值并不大,因为它的保护仅仅只是在图像识别上。不过,类似的操作可以移植到风格迁移的那种图像条件生成上去,在这个使用场景下,对授权保护的需求可能会更大一些。
VideoEspresso
VideoEspresso: A Large-Scale Chain-of-Thought Dataset for Fine-Grained Video Reasoning via Core Frame Selection
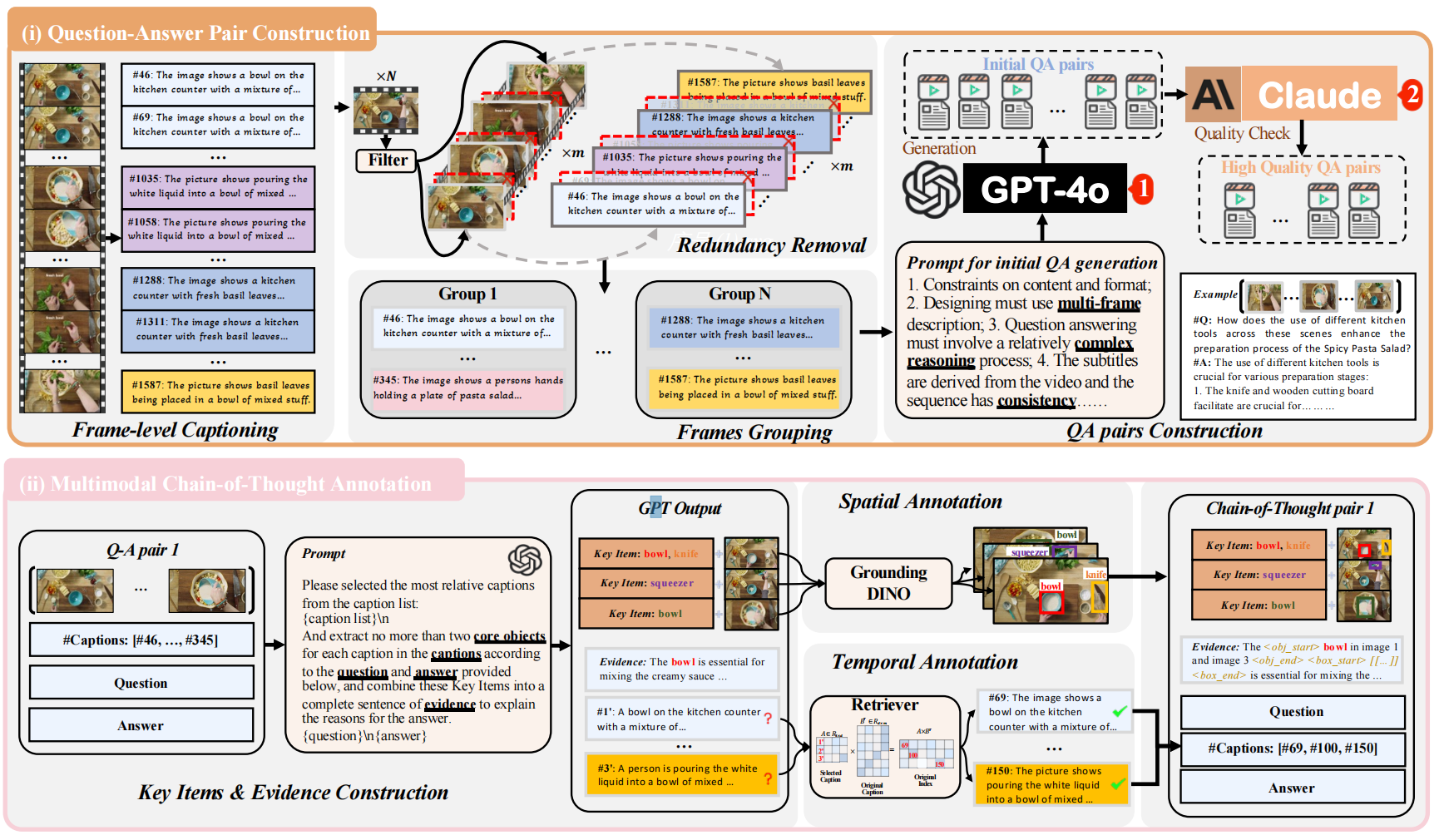


本文工作主要分为两个部分,分别是构建 VideoEspresso 视频QA数据集,和提出 Hybrid LVLMs Collaboration 视频推理框架两个部分。
VideoEspresso 视频QA数据集
- 构建背景:针对现有视频问答数据集依赖昂贵人工标注导致粒度粗糙,或自动构建方法因处理全量帧而充满冗余信息、缺乏细粒度时空逻辑的问题,急需一种能保留关键细节且包含中间推理步骤的大规模高质量数据。
- 构建过程:
- 冗余去除:利用轻量级模型,按照视频变化快慢自适应采样,为采样的每一帧生成帧描述 (Caption) 并计算语义相似度,过滤高度相似帧,提取高信息密度的“核心帧”序列。
- 问答生成:将核心帧按时间顺序每15帧划分为连续组,以在保持短时序逻辑连贯的同时避免长上下文引发的模型幻觉,进而将这些分组输入GPT-4o生成需多帧协同推理的复杂问答对并经由二次验证过滤。
- 多模态思维链标注:引导大模型提取关键物体及其时空位置(边界框+帧索引),构建包含“文本证据+空间坐标+时间索引”的完整推理链。
- 效果:构建了包含20万+高质量样本、覆盖14个细分推理任务的数据集;基于该数据集训练的模型在客观准确率上超越了GPT-4o等最强基线,且显著提升了推理的逻辑性和事实准确性。
Hybrid LVLMs Collaboration 视频推理框架
- 构建背景:为解决直接输入全量视频帧导致计算成本高昂(显存和FLOPs巨大)且冗余信息干扰模型注意力,以及传统端到端模型容易产生幻觉、缺乏可解释性证据的问题。
- 具体细节:
- 核心帧选择器:设计了一个由微小LVLM和LLM组成的轻量级插件,动态筛选出与问题最相关的极少数核心帧(平均仅2.36帧),大幅降低输入负载。
- 两阶段微调策略:对推理大模型进行分步训练,第一阶段强制模型学习从核心帧中定位并生成“多模态证据”,第二阶段基于生成的证据进行最终答案推理,实现思维过程的显式化。
- 结果:在保持甚至提升推理准确率(平均34.1%,超越GPT-4o 7.7%)的同时,将输入帧数减少至基准方法的1.8%,计算量(FLOPs)降低至14.74%,显存占用显著减少,实现了高效能与高精度的统一。
VDocRAG
VDocRAG: Retrieval-Augmented Generation over Visually-Rich Documents
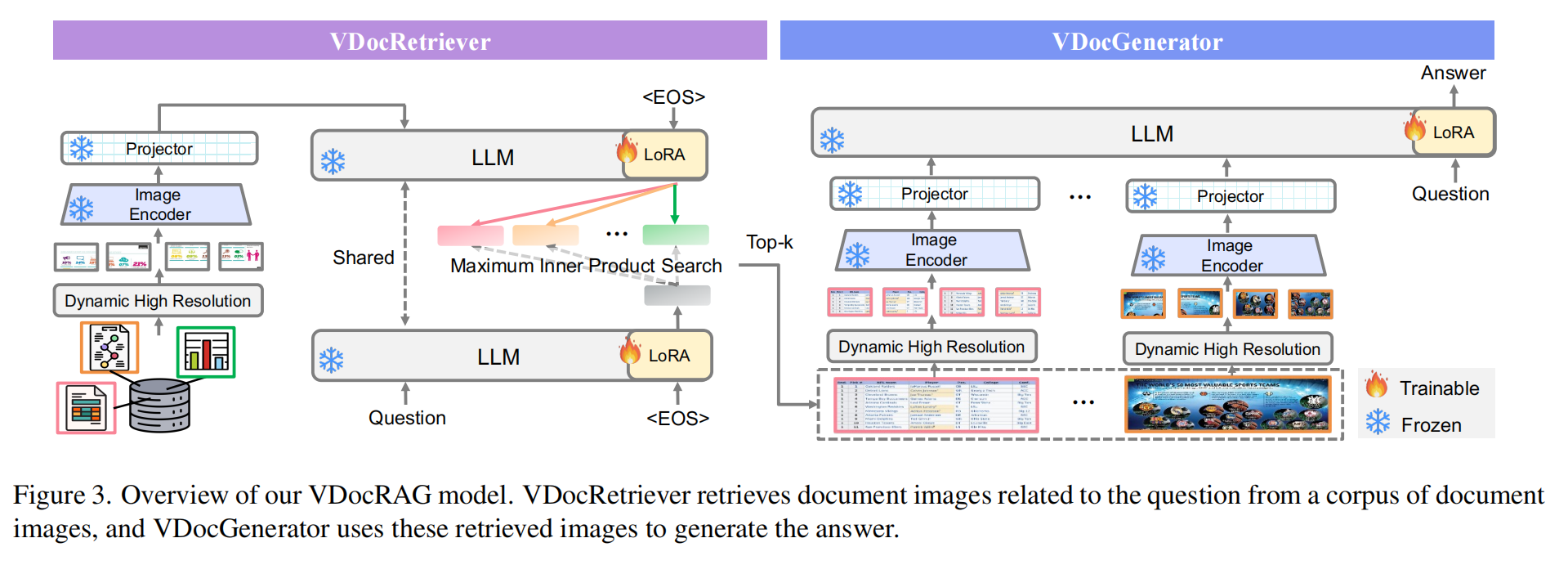
本文先构建了一个 OpenDocVQA 数据集,用于提供一个标准的视觉 RAG 基准。给定含有 个文档的图片(将 pdf 等文档统一转换成图片)集合 和一个给定的问题 ,OpenDocVQA 要求 RAG 大模型能够通过参考最相关的 个文档图像,输出针对问题 的回答 。
基于 OpenDocVQA 数据集,本文训练出了一个视觉检索模型 VDocRAG。VDocRAG 主要有两个模块,分别是检索部分 VDocRetriever 和回答部分 VDocGenerator。
- VDocRetriever 首先将文档图像动态切分为多个 大小的 Patches,经 ViT 编码与投影层映射为 LLM 维度的视觉 Token 序列(一个文档是一个 token 序列),并在末尾附加
<EOS>标记后输入模型,利用预训练阶段学到的自注意力机制(RCR/RCG任务),强制将分散在所有 Patch 中的复杂视觉语义信息“蒸馏”并压缩至最后一个<EOS>token 的隐藏状态,从而得到紧凑的文档向量 ;与此同时,对于用户问题 ,系统将其先分词为文本序列并在末尾同样附加<EOS>标记后输入同一模型,通过前向传播让<EOS>token 捕获整个问题的完整语义意图,提取其隐藏状态作为问题向量 ,最终通过计算 与 的余弦相似度进行最大内积搜索(Maximum Inner Product Search),从海量文档库中精准检索出 Top- 个最相关的视觉文档( 个文档就对应 个 )。 - 使用 Topk 筛选出最相关的 个文档后,VDocGenerator 就会将筛选出的文档和问题 共同输入给一个 VLM,让它生成对问题的回答。这里,筛选出的文档同样也是经过了 ViT 编码并投影到 LLM 维度的视觉 Token 序列,直接作为输入与问题文本一起输入给 VLM 进行端到端的生成。
- VDocRetriever 首先将文档图像动态切分为多个 大小的 Patches,经 ViT 编码与投影层映射为 LLM 维度的视觉 Token 序列(一个文档是一个 token 序列),并在末尾附加
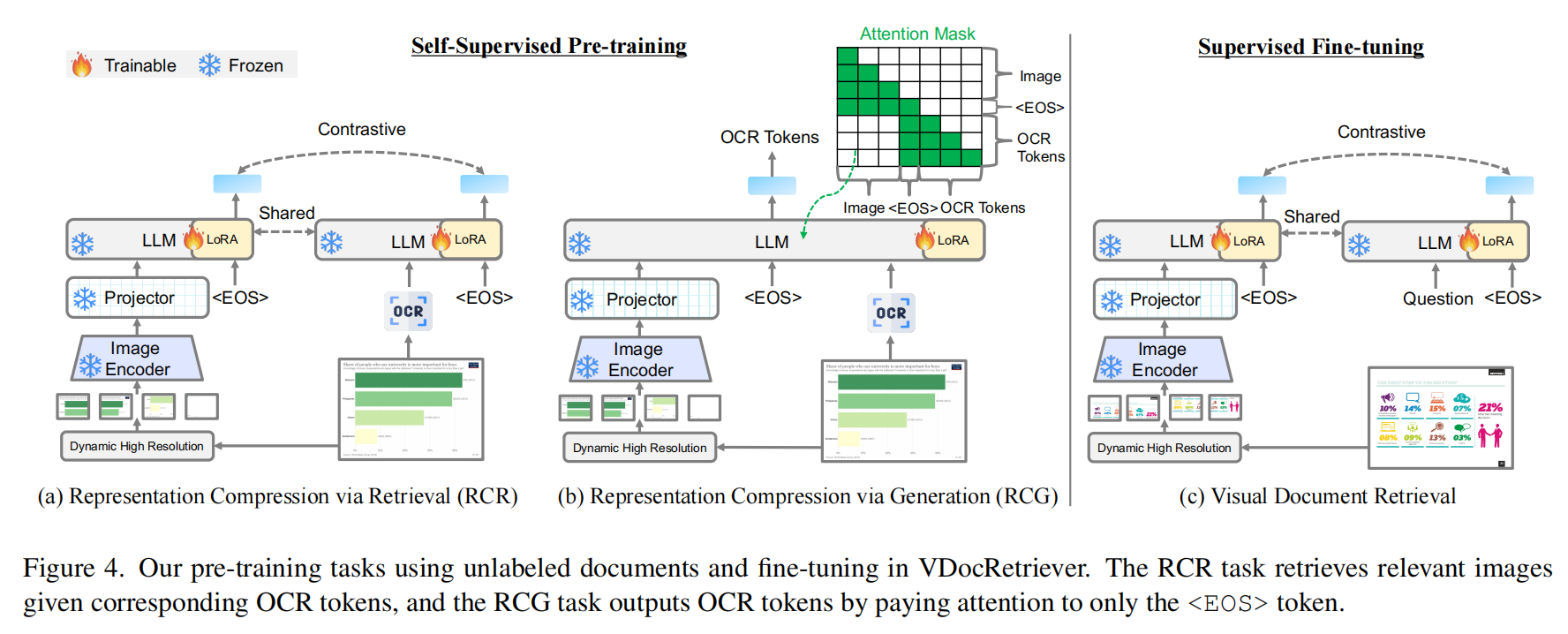
显然,检索的核心在于模型对 和 的构造能力上。作者在 VDocRetriever 的预训练阶段设计了两个自监督任务(RCR和RCG),强制模型将整张文档图像的所有视觉信息“蒸馏”并压缩进唯一的
<EOS>token 中,使其成为该文档的紧凑语义向量。- RCR (基于检索的对比学习):构建具备强判别力的语义索引。RCR 任务旨在解决“找得准”的问题,它通过最小化以下对比损失函数,强制文档图像的
<EOS>向量 () 与其对应的 OCR 文本向量 () 在特征空间中高度对齐,同时最大化与其他无关文档的距离: 其中 为正样本文档向量, 为批次内的负样本。该公式迫使模型学习到一个高区分度的嵌入空间:只有当 准确捕捉到文档的核心语义且与查询意图匹配时,分子项才会占主导;反之,若 包含噪声或偏离主题,分母中的负样本项将拉低分数。这确保了最终生成的 是一个纯净、高效的检索键值。 - RCG (基于生成的信息蒸馏):确保向量包含完整的细粒度细节。RCG 任务旨在解决“记得全”的问题,它设计了一种特殊的生成约束,屏蔽掉所有原始图像 Patch 的注意力,强制模型仅依赖
<EOS>向量来重构后续文本序列,其损失函数定义为: 这里的条件概率 意味着第 个字符的预测完全依赖于历史文本 和文档摘要向量 (即<EOS>),而无法直接看到具体的图像块。这一机制构成了严苛的信息瓶颈测试:如果 丢失了任何关键细节(如表格数字、特定词汇或布局关系),模型就无法以高概率生成正确的 ,导致 Loss 急剧上升。因此,该任务倒逼模型将所有分散的视觉信息无损地“压缩”进单一的 中,保证了检索向量的信息完备性。
- RCR (基于检索的对比学习):构建具备强判别力的语义索引。RCR 任务旨在解决“找得准”的问题,它通过最小化以下对比损失函数,强制文档图像的
模型的效果:
- 检索性能:在零样本(Zero-shot)设置下,显著优于BM25、CLIP及现有的视觉文档检索基线模型(如DSE, VisRAG-Ret),特别是在非文本主导的文档中。
- 生成性能:在InfoVQA, DUDE, ChartQA等多个基准上大幅超越基于文本的RAG。实验证明,即使使用相同的基座模型,仅改变输入形式(图像vs文本),VDocRAG也能取得更高分数。
- 效率优势:由于省去了耗时的OCR预处理步骤,其整体推理速度比传统文本RAG快约69%。
- 鲁棒性:在处理手写体模糊、表格错位等OCR容易出错的场景时,表现出更强的鲁棒性和准确性。
HyperCLIP
Understanding Fine-tuning CLIP for Open-vocabulary Semantic Segmentation in Hyperbolic Space
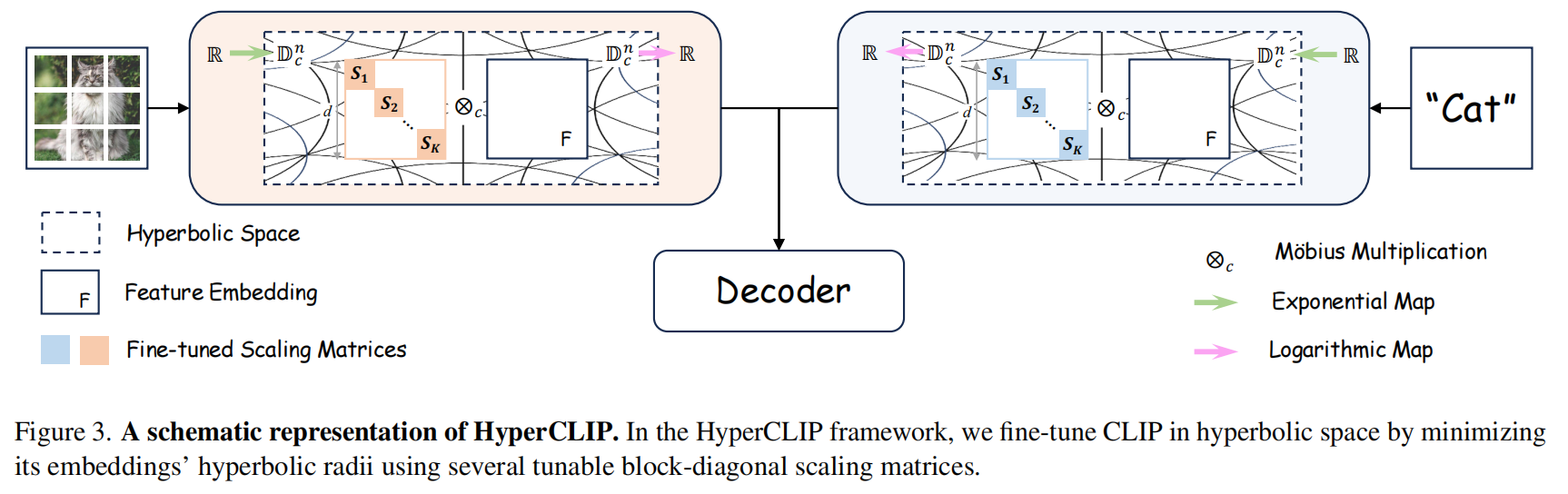
开放词汇语义分割任务要求模型能够基于任意文本描述对图像像素进行分类,突破预定义类别限制。CLIP作为强大的视觉-语言基础模型在此任务中表现突出,但存在一个关键矛盾:传统观点认为冻结CLIP文本编码器能保留其泛化能力,而最新研究却发现同时微调文本和图像编码器能显著提升性能。作者从层次对齐角度解释这一现象,发现微调过程中图像嵌入从图像级转变为像素级,这种层次结构的转变需要相应的文本嵌入调整来实现有效对齐。
作者提出了HyperCLIP——一种基于双曲几何的参数高效微调策略。双曲空间是一种具有负常曲率的非欧几里得几何空间,特别适合表示层次结构数据。在Poincaré球模型中,双曲空间定义为
其中 是曲率参数。双曲空间中的距离度量为:
其中 和 分别表示双曲减法和加法操作。点到原点的双曲半径(即层次深度)可表示为:
作者通过块对角缩放矩阵和Möbius矩阵乘法操作,调整CLIP文本嵌入的双曲半径,使其更好地与像素级视觉特征的层次结构对齐。
实验表明,HyperCLIP在三个基准测试上取得了开放词汇语义分割的最先进性能,仅需微调约4%的CLIP参数(5.6M参数)。研究发现,调整后的文本嵌入双曲半径从初始值7.5减小到约6.0时性能最佳,这验证了层次对齐的重要性。该方法还展现出良好的通用性,在开放词汇目标检测和全景分割任务上同样表现优异。值得注意的是,不同数据集上最优的双曲半径相对固定,这表明分割任务所需的语义粒度可能可以用双曲半径来量化。
What’s in the Image?
What's in the Image? A Deep-Dive into the Vision of Vision Language Models
视觉语言模型(Vision Language Models, VLMs)近年来在理解复杂视觉内容方面展现出卓越能力,但其内部处理视觉信息的机制仍不明确。尽管VLMs已被广泛应用于机器人、医疗影像分析、自动驾驶等领域,但它们通常被视为”黑盒”工具,缺乏对其内部视觉处理机制的理解。这种理解对于提高模型透明度、效率和在高风险应用中的可信度至关重要。本文旨在通过实证分析方法,深入探究VLMs如何处理和利用视觉信息。
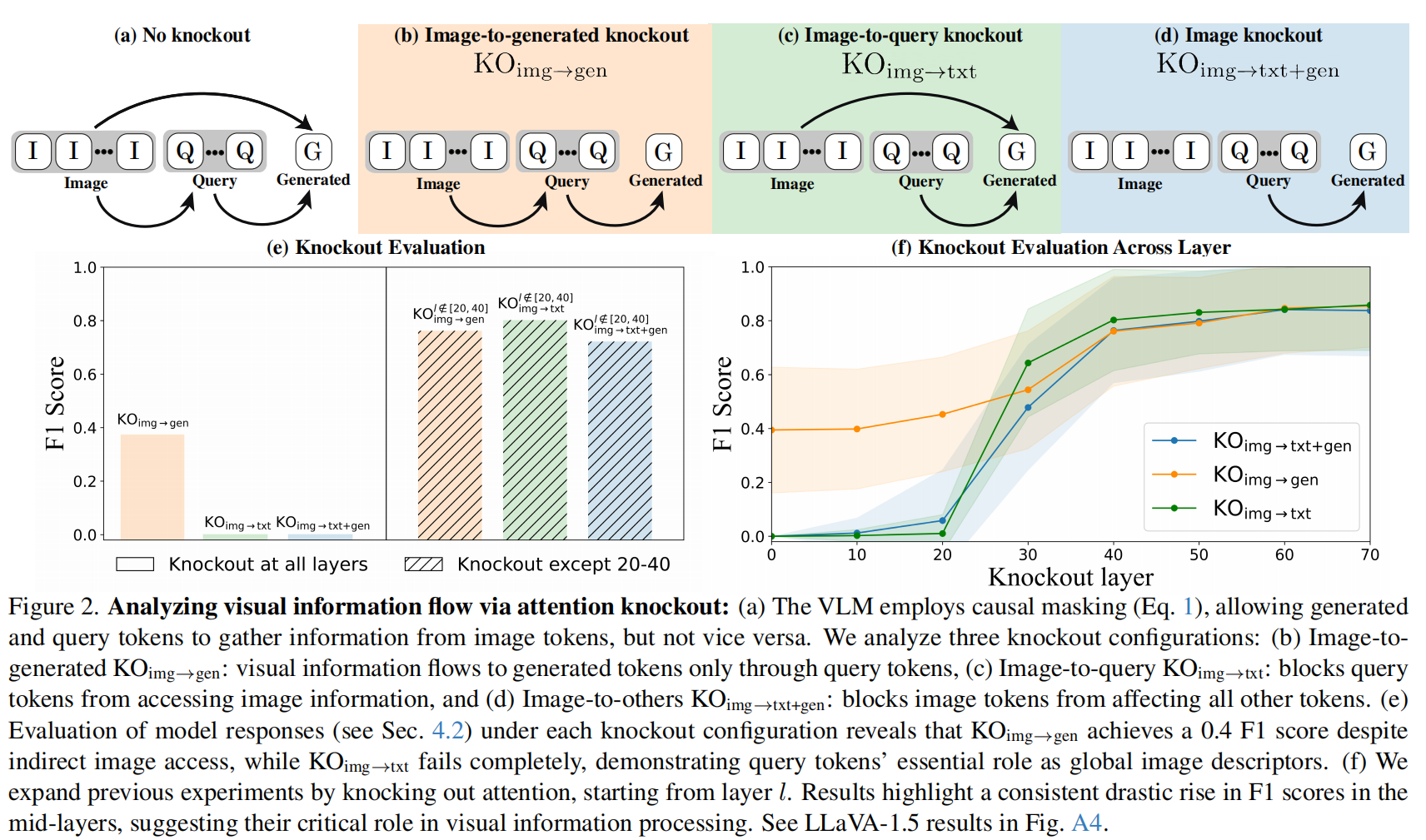
作者通过”注意力敲除”(attention knockout)技术,限制不同层对视觉信息的访问,来揭示模型内部工作机制。研究聚焦于三个核心问题:查询文本 tokens 在视觉信息处理中的作用、不同层在视觉-语言知识传递中的贡献,以及模型如何检索细粒度的视觉属性和对象细节。为验证这些发现,论文提出了两种新型评估协议:基于LLM的评估协议用于比较原始输出与修改后输出的一致性,以及利用现成的对象分割工具进行空间定位的自动评估。
研究得出了三个关键发现:(1) VLMs将高层次图像信息压缩到查询文本 tokens 中,即使阻断生成 tokens 直接访问图像 tokens,模型仍能产生描述性响应;(2) 视觉到语言的知识传递主要由中间层(约占所有层的25%)完成,而早期和晚期层贡献微乎其微;(3) 细粒度视觉属性和对象细节是通过生成 tokens 直接从图像 tokens 中以空间局部化方式提取的。基于这些发现,论文展示了”Image Re-prompting”技术,使用比完整上下文小20倍的压缩上下文,在视觉问答任务中仍能达到96%的性能。
VladVA
VladVA: Discriminative Fine-tuning of LVLMs
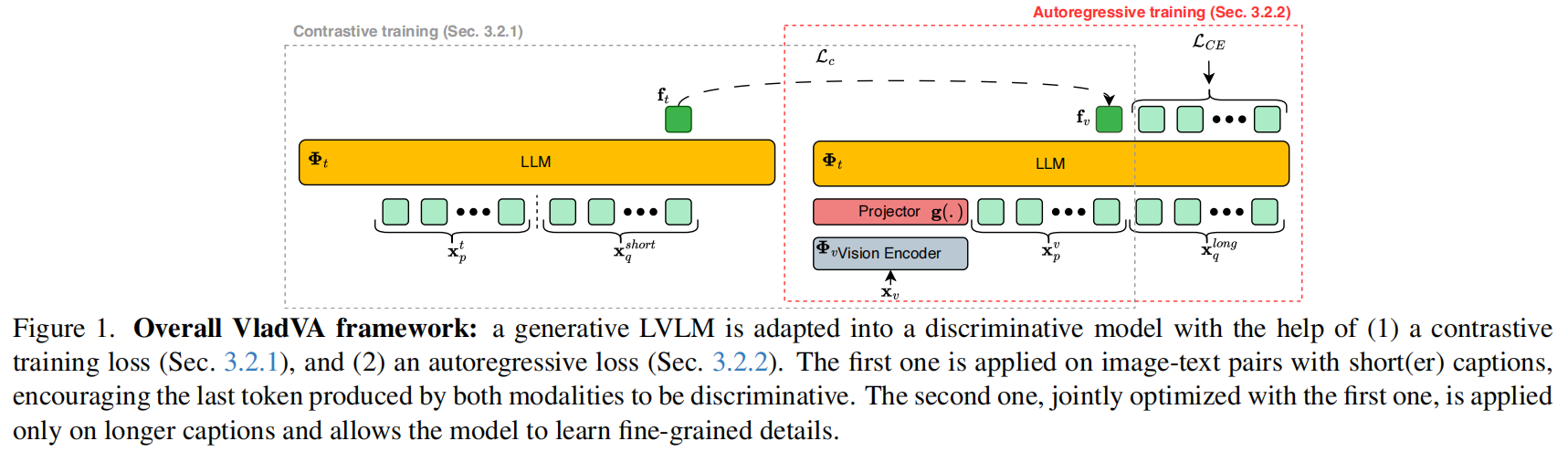
当前视觉-语言模型(VLMs)如CLIP虽在零样本任务中表现出色,但存在“词袋行为”和组合性理解不足的问题。而大型视觉-语言模型(LVLMs)虽具备强大的生成与推理能力,却因自回归训练方式难以直接用于判别任务(如图文检索)。近期工作E5-V尝试通过纯文本对比学习将LVLM转为判别模型,但忽略了图像-文本联合优化的潜力。本文旨在弥合这一鸿沟,提出一种新框架,将生成式LVLM转化为兼具强判别能力和组合性理解的模型,从而实现针对给定图像和给定文本的特定性判别(相似性计算)或生成(问答)任务。
VladVA 通过分粒度混合训练策略将判别性与组合性统一:针对短描述(< 30 tokens),采用对比损失 ,强制图像嵌入 与文本摘要嵌入 在余弦相似度空间中对齐,构建高区分度的全局判别向量;针对长描述(30–500 tokens),则引入自回归交叉熵损失 ,迫使模型在预测序列时显式关联视觉细节与复杂语言结构,从而习得细粒度组合推理能力。具体损失函数的公式如下:
在推理阶段,用户输入一张图像 和一段指令 (或仅图像):模型首先提取图像特征 ,并通过软提示将其转化为具有强判别性的“摘要Token”向量 (复用 的语义对齐能力);随后根据任务类型分路执行——若为检索/分类,直接计算查询文本与 的余弦相似度输出匹配结果;若为生成/问答,则将 作为前缀输入LLM,利用 习得的组合推理能力逐词预测生成包含详细视觉细节的自然语言描述,从而实现“一图多模态”的统一输出。
VladVA在多个基准上显著超越现有模型:在Flickr30K、COCO和nocaps的图文检索任务中,R@1指标比同规模SOTA模型提升4.7–7.0%,甚至超过参数量更大的EVA-CLIP(18B)。在组合性测试集SugarCrepe上,其在关系替换、属性添加等子任务上提升高达15%,尤其在“对象交换”任务(直接衡量词袋行为)上表现突出。消融实验证明,对比损失、自回归损失及参数高效组件均不可或缺。此外,模型在保持判别性能的同时,仍保留较强的生成能力。
Narrating the Video
Narrating the Video: Boosting Text-Video Retrieval via Comprehensive Utilization of Frame-Level Captions
在视频-文本检索(Text-Video Retrieval)领域,现有的主流方法通常依赖于CLIP等视觉语言预训练模型。然而,这些方法面临着两个主要挑战:一是跨模态鸿沟,即如何有效对齐异构的视觉与语言数据;二是时间信息捕捉不足。为了弥合鸿沟,现有研究尝试引入生成的辅助字幕(Caption),但大多采用单一的“视频级字幕”(Video-Level Caption)。这种方法往往只能概括关键场景,容易丢失视频中随时间变化的丰富细节(如连续动作和局部属性)。此外,生成模型固有的“幻觉”问题可能导致字幕包含错误信息,从而误导检索过程,导致性能下降。因此,论文旨在寻找一种能捕捉时序丰富信息且能过滤错误干扰的新框架。
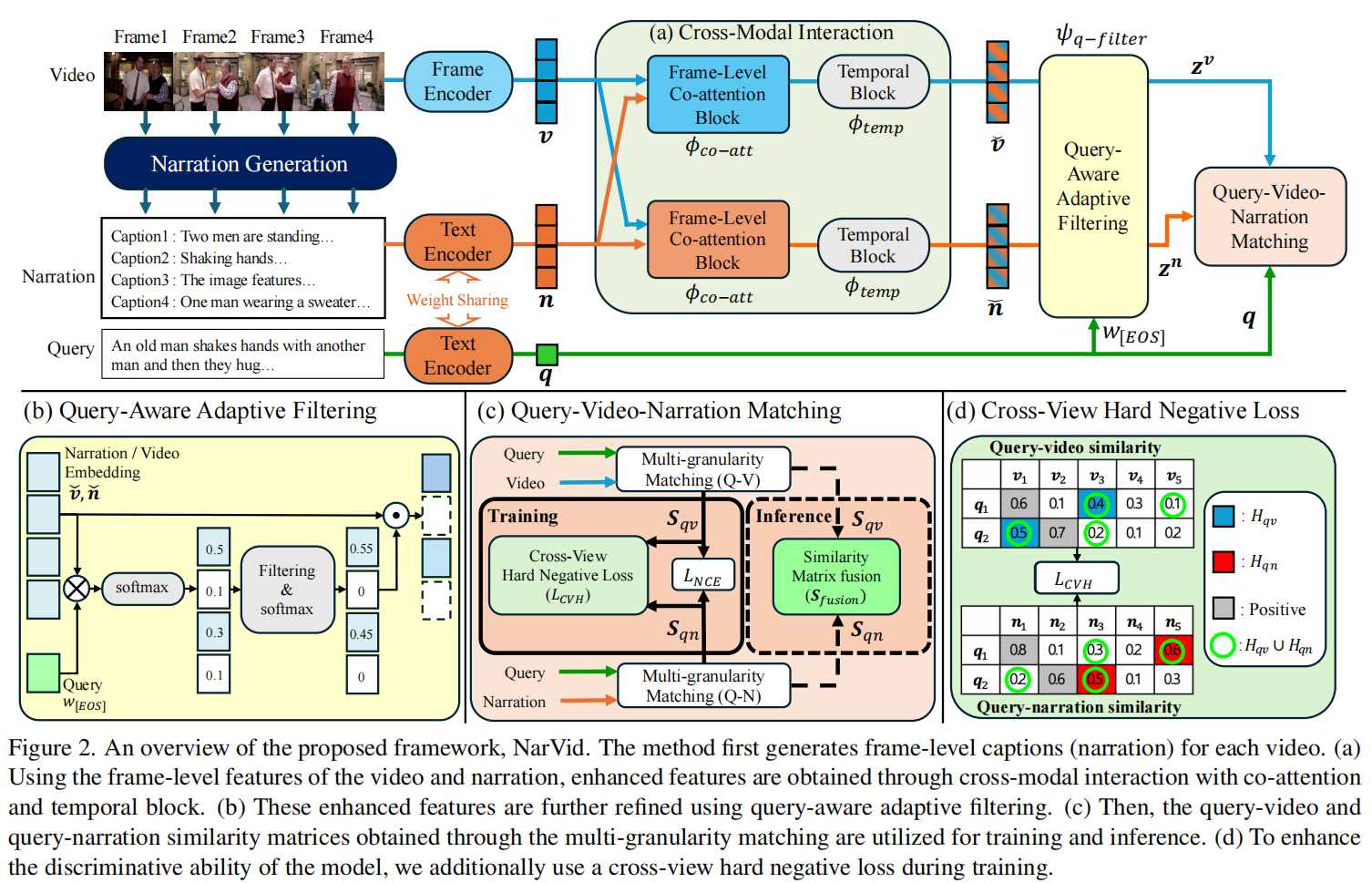
为了解决上述问题,论文提出了 NarVid (Narrating the Video) 框架。该框架的核心创新在于利用帧级字幕 (Frame-Level Captions) 构成的 “叙述(Narration)”,并将其贯穿于检索全过程。具体方法包含四个关键模块:
- 视频-叙述交互(Cross-Modal Interaction): 利用 Co-Attention 机制,让视频帧特征与对应的帧级字幕特征互相增强,并通过时间块(Temporal Block)捕捉时序依赖。
- 查询感知自适应过滤(Query-Aware Adaptive Filtering): 针对生成模型可能产生的幻觉,提出了一种基于核采样(Nucleus Sampling)的过滤机制。该机制根据查询文本(Query)的相似度,动态筛选掉无关或错误的帧/字幕特征,而非固定选取Top-k帧。
- 双模态匹配(Dual-Modal Matching): 在计算相似度时,不仅计算“查询-视频”的相似度,还额外计算“查询-叙述”的相似度,并将两者融合,利用叙述中的丰富语义作为补充。
- 跨视图难负样本损失(Cross-View Hard Negative Loss): 在训练阶段,结合“查询-视频”和“查询-叙述”两个视角来定义难负样本(Hard Negatives),促使模型学习更具判别性的特征。
NarVid 框架在四个主流基准数据集(MSR-VTT, MSVD, VATEX, DiDeMo)上均取得了State-of-the-Art (SOTA) 的成绩。在最具代表性的 MSR-VTT 数据集上,NarVid 的 Text-to-Video R@1 指标达到了 52.7%,显著优于基线模型 CLIP4Clip (44.5%) 和其他现有方法(如 Cap4Video 的 49.3%)。消融实验进一步证明了该方法的有效性:引入“叙述匹配”模块使 R@1 提升了 4.1%,而“自适应过滤”机制被证实能有效剔除无关信息,显著提升检索精度。实验结果充分验证了利用帧级叙述捕捉时间变化信息以及过滤错误特征的策略,能有效解决视频检索中的跨模态鸿沟问题。
Explaining Domain Shifts in Language
Explaining Domain Shifts in Language: Concept erasing for Interpretable Image Classification
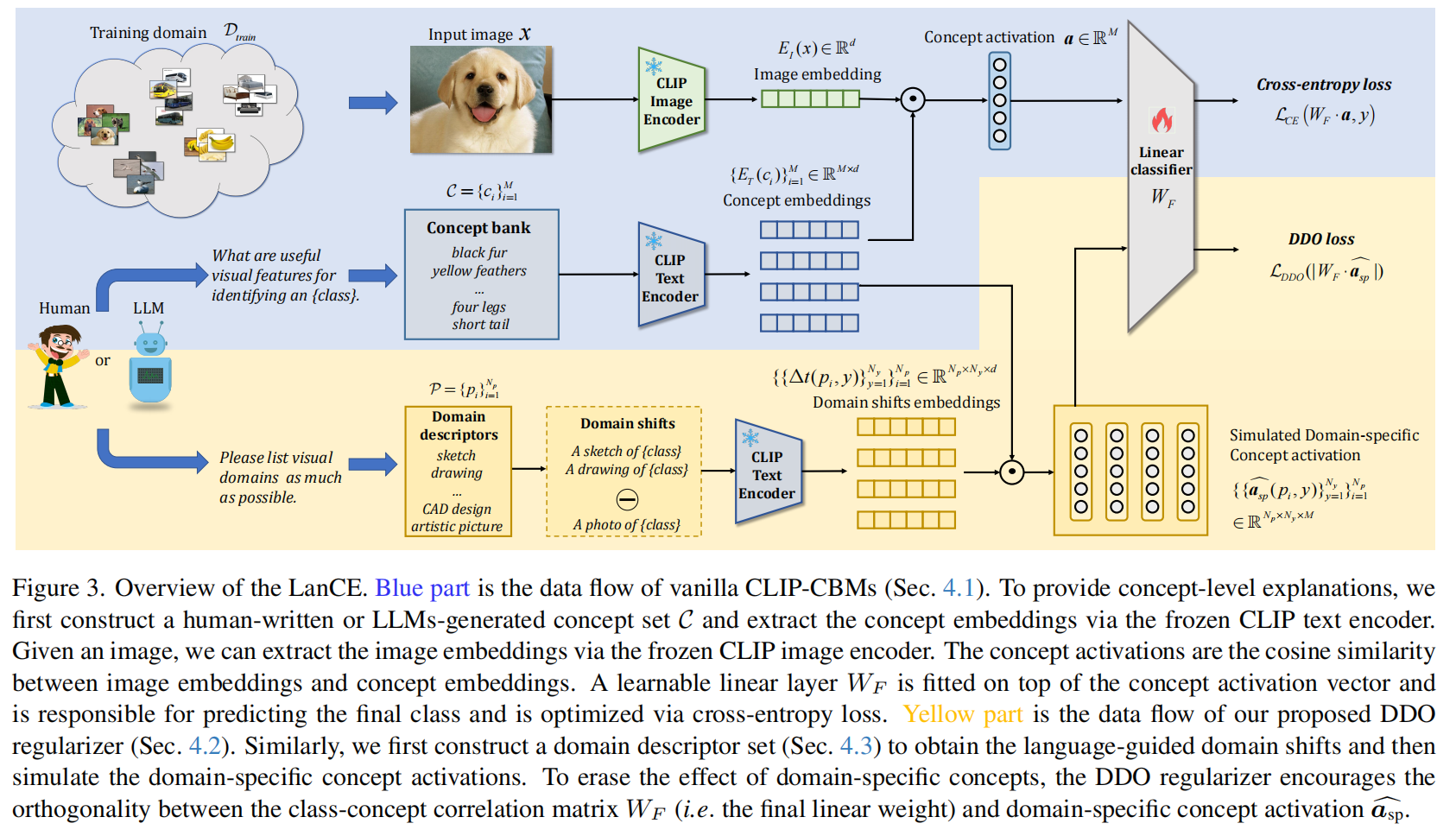
现有的概念瓶颈模型(CBMs)虽然通过人类可理解的概念(如颜色、纹理、形状)提升了模型的可解释性,但在面对未见过的视觉域(Out-of-Distribution, OOD)时,其泛化能力往往较差。论文指出,核心痛点在于这些模型倾向于依赖域特异性概念(例如训练数据中苹果通常是“红色”且具有“蜡质光泽”)。当测试数据发生域偏移(如从真实照片变为卡通或素描)时,这些特定特征消失,导致模型性能大幅下降。因此,如何在不牺牲可解释性的前提下,消除这些域特异性概念对分类决策的负面影响,是本文旨在解决的关键问题。
为了解决上述问题,作者提出了一种名为语言引导概念擦除(Language-guided Concept-Erasing, LanCE)的框架。该方法的核心创新在于利用大语言模型(LLM)和视觉语言模型(VLM)来辅助训练。具体而言,论文利用LLM(如GPT-3.5)生成大量未见域的描述符(如“素描”、“雕塑”、“3D模型”),并利用VLM(如CLIP)计算这些描述符在视觉空间中的差异方向。基于此,论文设计了一个即插即用的域描述符正交性(DDO)损失函数。该损失函数强制分类器的权重与模拟出的域特异性概念激活值保持正交,从而在不改变模型架构和增加推理成本的情况下,有效地“擦除”了有害的概念关联,迫使模型仅依赖域共享的通用特征(如物体形状)进行判断。
为了验证LanCE的有效性,研究在7个基准数据集上进行了评估,其中包括4个标准基准和3个新构建的极具挑战性的基准(涵盖从真实照片到卡通、雕塑及3D渲染的跨域场景)。实验结果表明,引入DDO正则化项后,模型在保持原始域(In-Distribution)分类精度几乎不变的同时,显著提升了在未见域(OOD)上的泛化能力。与现有的SOTA概念模型相比,LanCE在OOD准确率上平均提升了约3个百分点。此外,定性分析显示,经过LanCE训练的模型,其关注点确实从“颜色”、“背景”等干扰特征转移回了物体的核心形状特征,证明了该方法在提升鲁棒性和可解释性方面的双重优势。
PATHEVAL
Evaluating Vision-Language Models as Evaluators in Path Planning
尽管大语言模型(LLMs)和视觉语言模型(VLMs)展现出强大的推理能力,但它们在端到端的长程路径规划(End-to-End Path Planning)中表现不佳。这促使研究者思考一种新的范式:既然模型难以直接生成完美的路径,能否将其作为“评价者”(Evaluator)或“批评者”(Critic)来评估传统算法生成的路径质量?这一思路基于“评价比生成更容易”的直觉。然而,现有的研究缺乏对VLMs在复杂路径规划场景下作为评价者能力的系统评估,特别是缺乏对低级视觉感知(如精确的距离、角度、间隙感知)与高级常识推理相结合的考验。因此,作者旨在探究VLMs是否具备同时处理精细视觉细节和复杂语义指令的能力。
为了验证上述问题,作者提出了 PATHEVAL,这是一个可控且可扩展的基准测试。该基准包含14,550个任务,基于1,150个不同的复杂环境(如迷宫、波浪形障碍等)和15种决策场景(如消防车需最大化覆盖面积、大型卡车需最小化急转弯等)构建。
- 任务设计: VLM 需要在给定场景描述的前提下,比较两条路径(Path 1 和 Path 2)的图像(2D或3D),并选出更符合场景约束的路径。
- 核心挑战: 成功完成任务需要模型具备三种能力:属性抽象(从文本中理解什么是好路径)、低级感知(从图像中精确提取路径的几何特征,如最小间距、平滑度、急转弯数量)、信息整合(结合视觉感知和文本需求做出决策)。
实验评估了包括 GPT-4o 和多种开源模型(如 LLaVA, Qwen2-VL)在内的 9 个 SOTA VLMs,得出了以下关键结论:
- 视觉瓶颈(Visual Bottleneck): 模型在任务中的失败主要归因于视觉感知能力的不足,而非语言推理能力。当研究者直接提供路径的数值特征(绕过视觉)时,模型准确率大幅提升(如 Qwen2-VL 从 50.2% 升至 74.2%);但在仅看图像时,模型难以分辨细微的几何差异。
- 模型表现差异: GPT-4o 是唯一显著优于随机猜测的模型,但在 3D 图像中仍受视觉错觉困扰;大多数开源模型(如 LLaVA)表现接近随机水平(~50%),且存在严重的幻觉(Hallucination),即编造视觉细节来支持其错误的选择。
- 微调的局限性: 实验发现,简单的端到端微调无法解决视觉编码器(Vision Encoder)的感知缺陷。论文指出,需要针对特定任务对视觉编码器进行专门的判别性适应(Discriminative Adaptation),才能让 VLM 成为有效的路径评价者。
CoT-VLA
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
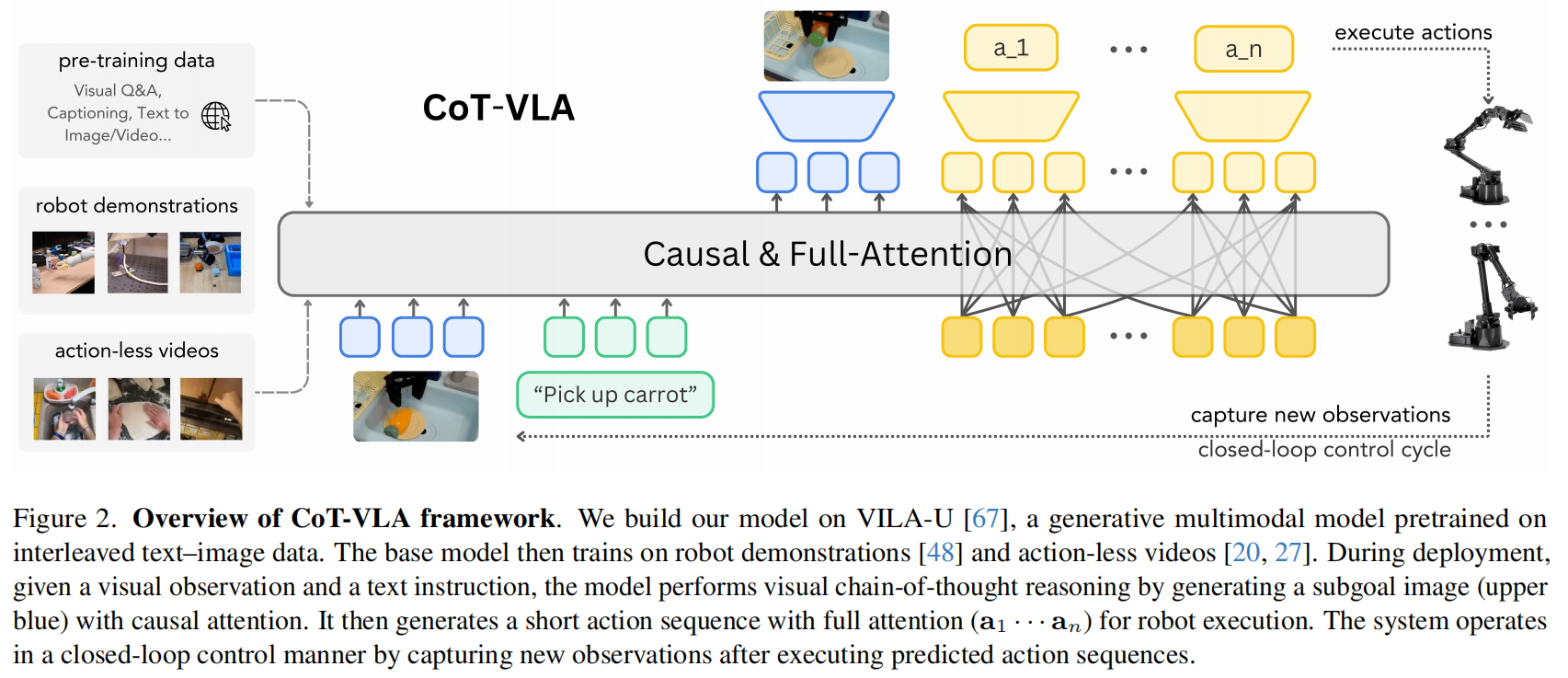
现有的视觉-语言-动作模型(Vision-Language-Action Models, VLAs)虽然通过利用大规模预训练的视觉-语言模型(VLMs)和机器人演示数据,在学习通用的传感器运动控制方面展现出了巨大潜力,但它们存在明显的局限性。目前的主流 VLA 方法(如 RT-1, OpenVLA 等)主要侧重于从观测(Observation)到动作(Action)的直接映射(Direct Input-Output Mapping)。这种范式缺乏中间的推理步骤,导致模型在处理需要复杂规划的长程任务时,缺乏时间上的推理和规划能力。此外,现有的 VLA 通常仅依赖带有动作标注的机器人演示数据,无法有效利用互联网上海量的、仅包含视频和语言描述的“无动作视频数据”(Action-less Videos),这限制了其视觉理解能力的进一步提升。
为了解决上述问题,论文提出了 CoT-VLA,这是一种引入了显式视觉思维链(Visual Chain-of-Thought, Visual CoT)推理的 VLA 模型。该方法的核心理念是让模型在行动前先进行“视觉思考”:模型不再直接预测动作,而是首先自回归地生成一张子目标图像(Subgoal Image),作为中间推理步骤,代表对未来状态的像素级规划;随后,模型基于当前观测和生成的子目标图像,生成一段短的动作序列(Action Chunk)来实现该目标。在架构设计上,CoT-VLA 基于能够理解和生成图像/文本的统一多模态基础模型 VILA-U,并引入了混合注意力机制(Hybrid Attention)——对图像/文本生成使用因果注意力,对动作预测使用全注意力,以支持并行动作解码。这种方法不仅解锁了利用 EPIC-KITCHENS 等无动作视频数据进行预训练的能力,还通过视觉推理增强了任务的可解释性。
CoT-VLA 在模拟环境和真实世界的机器人操作任务中均取得了卓越的表现,证明了视觉思维链的有效性。在 LIBERO 模拟基准测试中,CoT-VLA 的成功率达到了 81.13%(Spatial 套件),显著优于之前的 SOTA 模型 OpenVLA。在 真实世界实验中,无论是 Bridge-V2 平台还是仅有少量演示数据的 Franka-Tabletop 设置,CoT-VLA 都展现出了更强的泛化能力。特别是在 Franka-Tabletop 的长程任务中,其成功率达到了 69.0%,比 OpenVLA 高出了约 15%。消融实验证实,引入视觉思维链(Visual CoT)和混合注意力机制是性能提升的关键因素,且利用无动作视频数据进行预训练能显著提高模型在下游任务中的适应能力。
CoLLM
CoLLM: A Large Language Model for Composed Image Retrieval
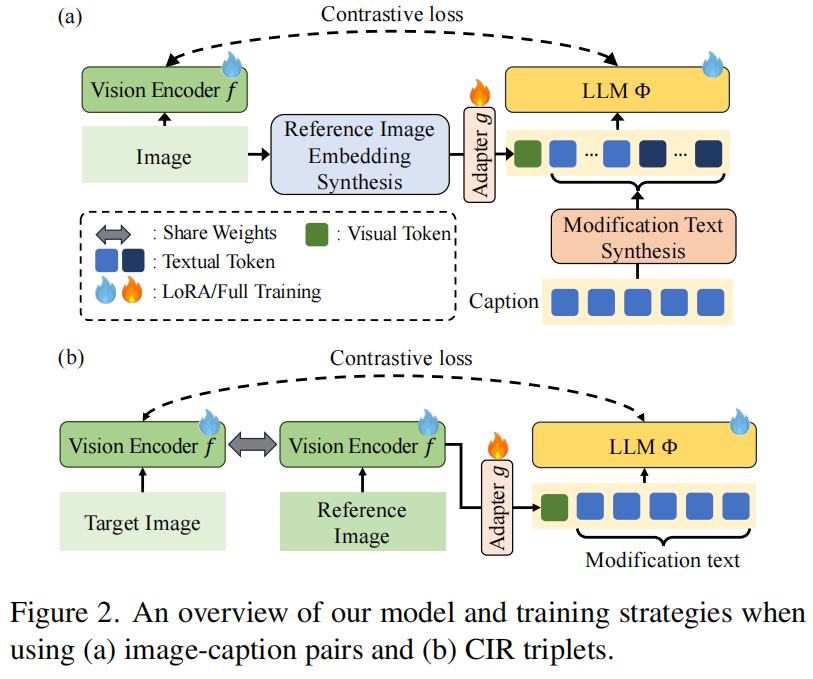 |  |
论文指出,当前的CIR研究面临四大核心挑战,导致难以在实际场景中广泛应用:
- 数据获取极其困难(Data Scarcity): 监督学习需要大量高质量的三元组数据(参考图、修改文本、目标图)。人工标注这些数据既昂贵又耗时,导致现有的CIR数据集规模小、覆盖域有限。
- 现有替代方案的局限性:
- 零样本方法: 依赖现成的图文对(Image-Caption Pairs),缺乏针对CIR任务的特定联合嵌入学习,效果受限。
- 合成数据集: 现有的合成数据(如LaSCo, WebCoVR)往往规模不足,且生成的修改文本生硬、缺乏多样性,无法模拟真实的人类查询习惯。
- 模型理解能力不足(Model Limitation): 现有的CIR模型通常使用浅层Transformer或简单的线性插值来融合图像和文本,缺乏对复杂语义关系的深度理解。
- 评估基准存在歧义(Evaluation Noise): 主流基准(如CIRR, Fashion-IQ)中存在大量歧义样本(即一个查询可能对应多个正确的答案),这导致模型评估结果不可靠,难以反映模型的真实性能。
为了解决上述问题,论文提出了 CoLLM 框架,这是一个基于大语言模型(LLM)的CIR解决方案,包含三个核心创新点:
基于图文对的动态三元组合成(Triplet Synthesis): CoLLM 不依赖人工标注的CIR三元组,而是利用海量现成的图文对进行训练。
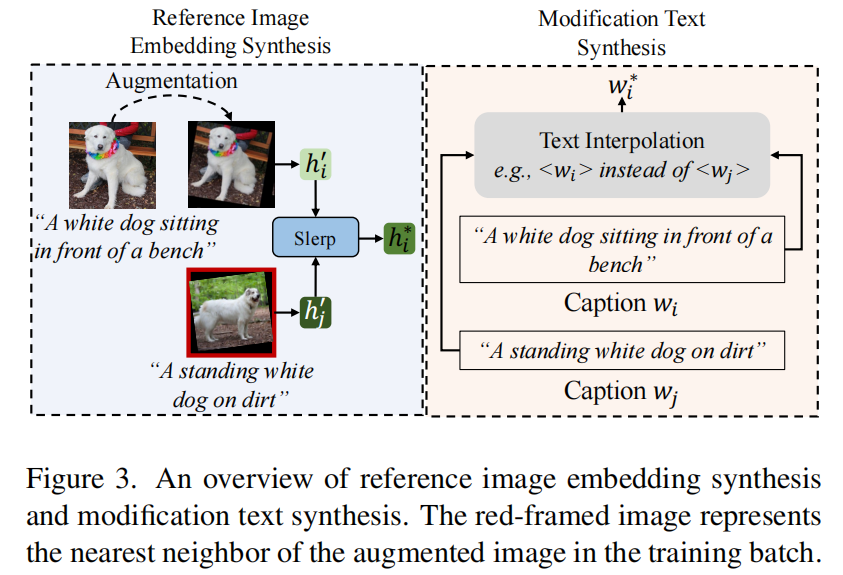
- 图像端: 利用球面线性插值(Slerp)在批次内找到最近邻图像,合成“参考图像嵌入”。
- 文本端: 利用预定义的模板(如“将A改为B”),结合原图和邻近图的描述,自动生成自然的“修改文本”。
- 这一策略使得模型可以在没有人工CIR数据的情况下进行监督训练。
基于LLM的深度查询组合(LLM-based Query Composition): 与传统方法使用浅层网络不同,CoLLM 利用预训练的 LLM(或专门的嵌入模型 LLEM) 来处理多模态查询。
- 模型将合成的参考图像嵌入和修改文本同时输入LLM。
- 利用LLM强大的世界知识和语义理解能力,深度挖掘视觉与语言之间的复杂关系,生成更精准的联合嵌入向量。
构建高质量数据集与基准(MTCIR & Refined Benchmarks):
- MTCIR数据集: 论文利用LLM生成了包含 340万 图像对和 1770万 修改文本的合成数据集。该数据集的特点是包含真实图像,并为每对图像提供多条简短、自然的修改文本(平均每对5.18条),覆盖多种属性。
- 精修基准测试集: 利用Claude 3 Sonnet对现有的CIRR和Fashion-IQ验证集进行清洗,剔除歧义样本并重写模糊的文本,从而提供更可靠的评估环境。
论文在多个标准CIR基准上进行了广泛实验,结果证明了CoLLM的优越性:
- SOTA 性能: CoLLM 在 CIRCO、CIRR 和 Fashion-IQ 等多个基准测试中均取得了 State-of-the-Art (SOTA) 的成绩。即使在不使用任何CIR三元组进行预训练的情况下,其表现也优于许多现有的零样本方法。
- 数据集有效性验证: 当使用论文提出的 MTCIR 数据集进行微调时,模型性能大幅提升。例如在CIRR数据集上,Recall@1 指标显著优于 MagicLens 和 CoVR2 等现有最佳模型,证明了合成数据的质量和有效性。
- 消融实验结论:
- LLEM优于LLM: 实验发现,专门用于检索任务微调的嵌入模型(如 E5-Mistral)比通用的生成式LLM表现更好。
- 评估基准的改进: 在经过清洗的“精修基准”上,CoLLM 依然保持领先,且模型排名在清洗前后保持一致,验证了新基准的可靠性。
- 数据质量为王: 尽管 MTCIR 的数据量级在合成数据中并非最大,但因其高质量和多样性,训练出的模型效果远超基于其他合成数据集训练的模型。
Beyond Sight
Beyond Sight: Towards Cognitive Alignment in LVLM via Enriched Visual Knowledge
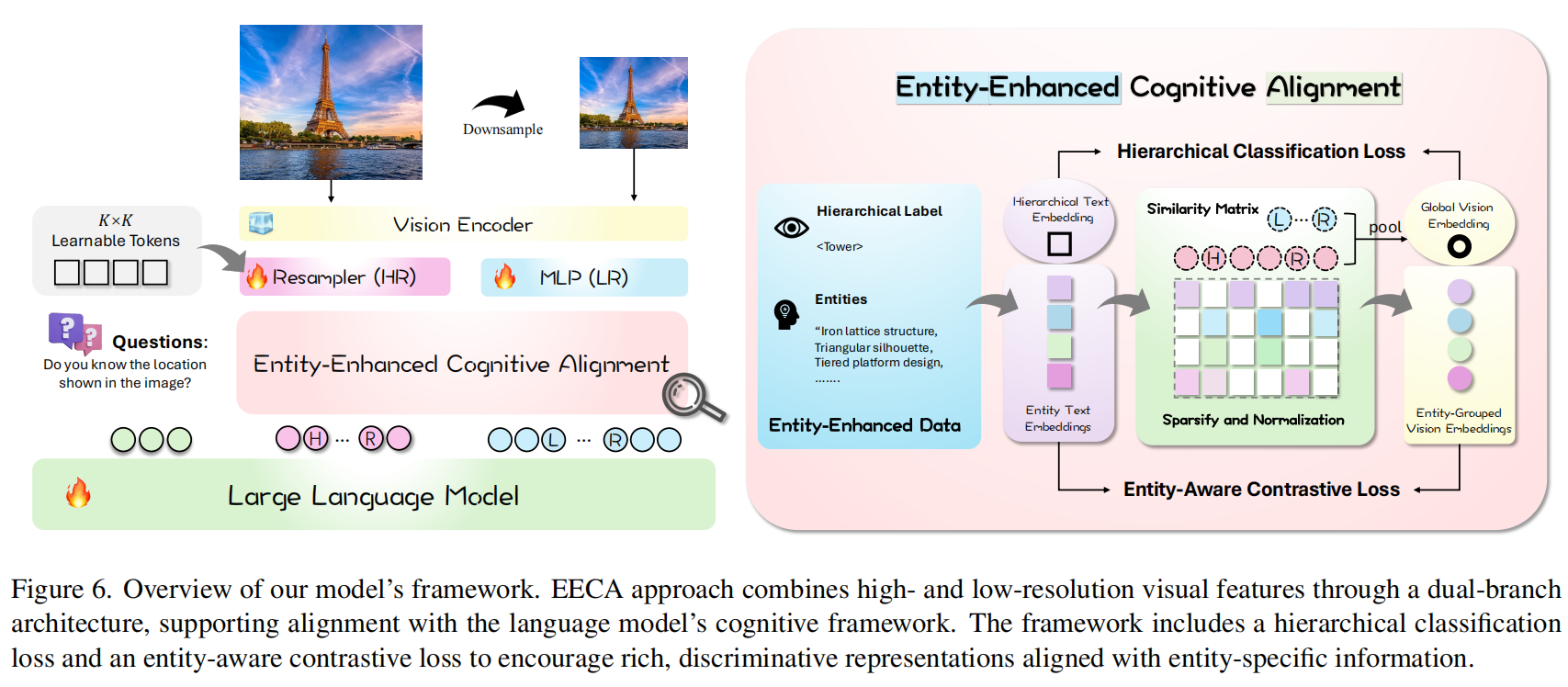
论文首先提出了一个核心疑问:“看见(Seeing)是否意味着知道(Knowing)?”研究者发现,即使是最先进的模型(如GPT-4o、Qwen2-VL),在面对标志性建筑图片时往往无法识别,尽管它们在纯文本问答中能准确描述该建筑。这揭示了**“认知不对齐”(Cognitive Misalignment)**这一根本问题:视觉编码器(VE)提取的特征与大语言模型(LLM)的认知框架之间存在断层。作者通过构建多粒度地标数据集(MGLD)进行分析,发现单纯增加数据量无效,反而会引入“VE-Unknown”数据(即视觉特征模糊、缺乏区分度的数据),这些数据阻碍了视觉与语言模态的有效整合。
为了解决上述问题,论文提出了实体增强认知对齐(Entity-Enhanced Cognitive Alignment, EECA)框架,旨在让视觉Token“模仿”VE-Known的特征,从而打开LVLM的“认知之眼”。该方法包含两个核心部分:首先,设计了一个双分支视觉架构,结合高分辨率(HR)和低分辨率(LR)特征,利用HR分支捕捉丰富的细节信息;其次,引入了多粒度监督机制,包含“实体感知对比损失(Entity-Aware Contrastive Loss)”和“分层分类损失(Hierarchical Classification Loss)”。前者强制高分辨率Token与LLM嵌入空间中的实体特征对齐,后者则通过层级标签建立跨类别的区分能力,从而确保视觉Token既丰富又具有判别力。
实验结果验证了EECA在提升LVLM认知对齐方面的有效性。在地标识别任务中,EECA不仅在VE-Known数据上表现出色,更显著提升了模型对原本难以识别的VE-Unknown数据的理解能力。研究显示,数据质量远胜于数量:仅使用25k数据训练的EECA模型,其性能就能达到甚至超越使用125k基线数据训练的模型水平。此外,消融实验证明,引入实体感知监督和分层分类损失是性能提升的关键因素,该方法在不同类型的视觉数据上均展现出了卓越的鲁棒性和泛化能力。
AnySat
AnySat: One Earth Observation Model for Many Resolutions, Scales, and Modalities
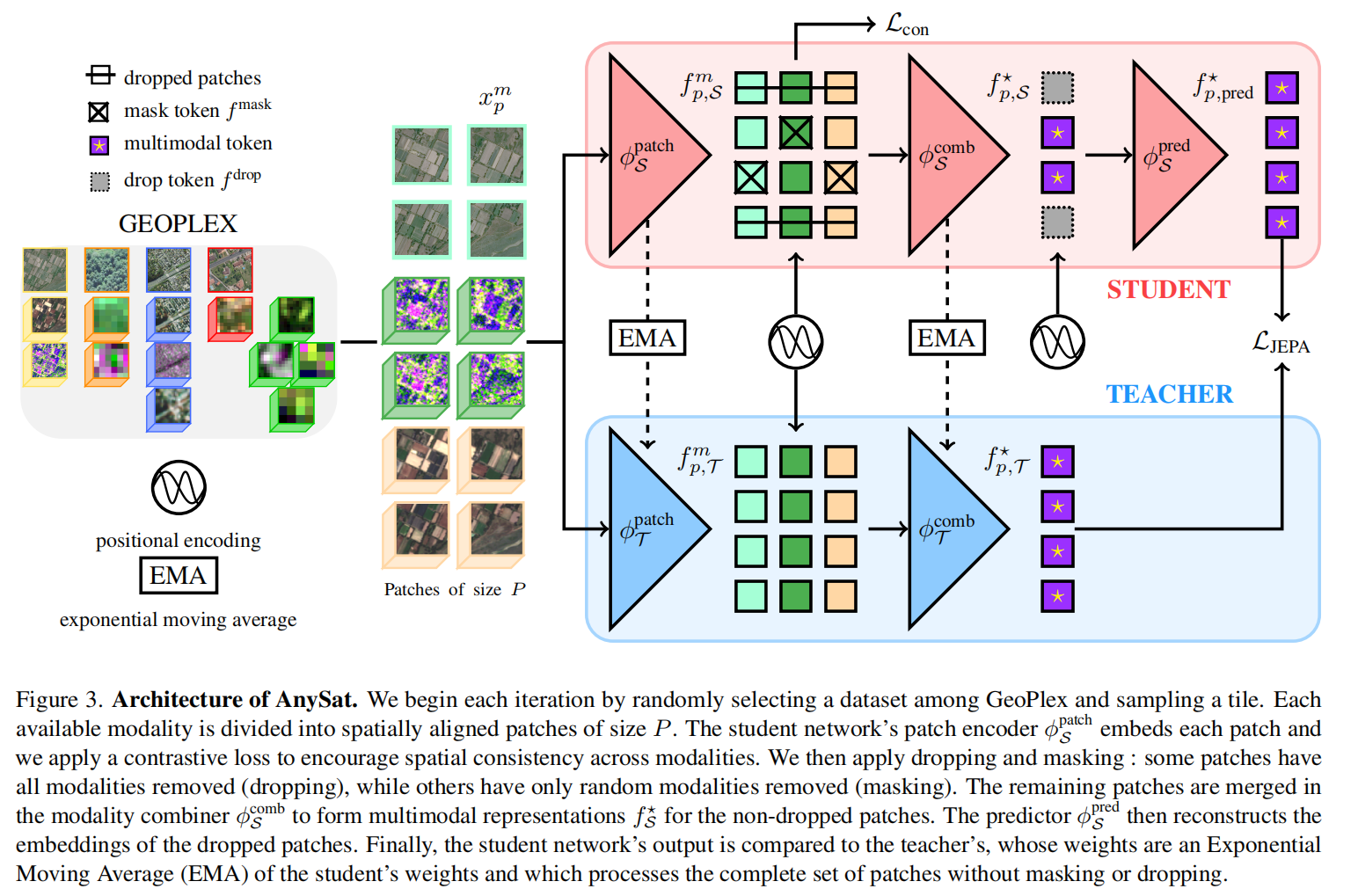
遥感(Earth Observation, EO)数据与自然图像(如RGB照片)存在本质差异,表现出极高的异构性。现有的EO基础模型通常针对单一特定数据集(如仅Sentinel-2)进行训练,往往要求固定的输入配置(如特定的分辨率、波段数或模态组合)。这种刚性设计导致模型无法直接应用于不同传感器配置的数据,一旦遇到分辨率或模态不同的场景,往往需要重新训练或进行复杂的调整,这违背了基础模型应具备的通用性和灵活性。遥感数据在空间分辨率(从0.2米到250米)、时间频率(单时相到时间序列)和光谱模态(光学、雷达等)上存在巨大差异,因此亟需一种能够无缝集成多源异构数据的统一架构。
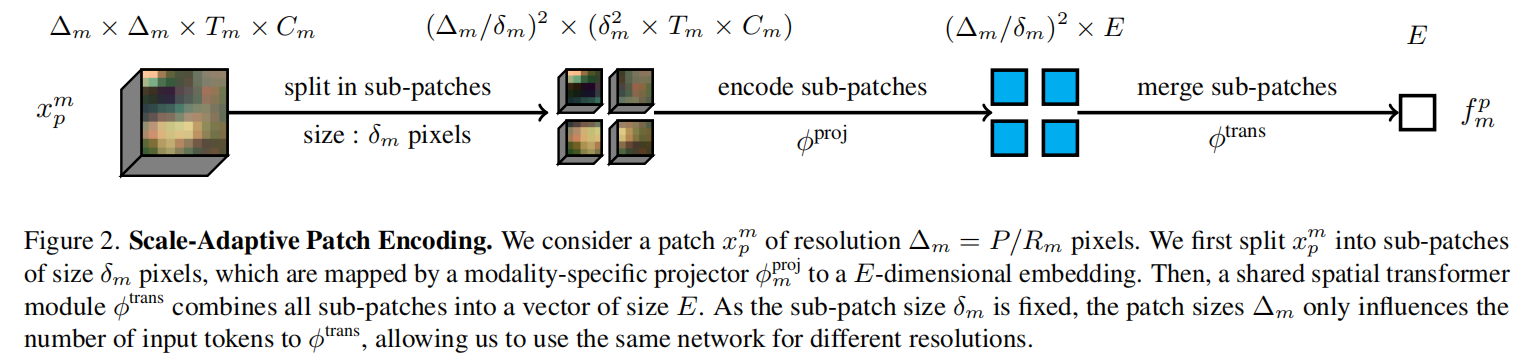
为了解决上述问题,论文提出了 AnySat,这是一种基于**联合嵌入预测架构(JEPA)和尺度自适应块编码(Scale-Adaptive Patch Encoding)**的通用地球观测模型。
- 尺度自适应编码(核心创新):AnySat不直接处理原始Patch,而是将其细分为固定物理尺寸的Sub-patches。这一机制使得模型能够处理任意大小的输入Patch和任意的空间分辨率,而无需改变网络参数,实现了参数在不同分辨率下的共享。
- JEPA自监督学习:不同于传统的掩码自编码器(MAE)试图在像素级重建图像,AnySat采用JEPA框架,在特征空间而非像素空间进行预测。它利用一个“学生网络”预测被遮挡区域的特征,并使其逼近由“教师网络”(通过EMA更新)提取的目标特征。这种方法避开了多模态数据在像素级重建的困难,直接学习语义一致的高层特征。
- 多模态融合:通过Modality-Combiner网络,利用交叉注意力机制将不同模态(如SAR和光学)在同一空间位置的特征进行融合。
AnySat在包含GeoPlex内部测试集和6个外部数据集的广泛评估中,展现了卓越的泛化能力和SOTA(State-of-the-Art)性能:
- 多任务SOTA表现:在9个下游任务(包括土地覆盖分类、树种识别、作物分类、洪水监测和变化检测等)中,AnySat均达到了最佳性能。例如,在TreeSatAI-TS上加权F1分数提升了0.9,在PASTIS-HD上分割mIoU提升了0.2。
- 强大的泛化能力:AnySat成功应用于未参与训练的传感器配置。例如,尽管训练数据中没有HLS(Harmonized Landsat-Sentinel)数据,AnySat通过微调新投影层,其在HLS Burn Scar检测任务上的表现超越了在海量HLS数据上训练的同类模型(如Prithvi)。
- 高效性与线性探测:得益于JEPA学习到的高质量特征,AnySat在仅使用线性探测(Linear Probing,即冻结主干网络仅训练线性分类器)的情况下,也能在Sen1Floods11等数据集上取得极具竞争力的结果,证明了其特征表达的鲁棒性。