

Self-Distillation (Motivation & Definition)
- Self-distillation can be read as: the model teaches itself. During training we maintain a student and a teacher; the teacher is not an externally trained model but is usually an exponential moving average (EMA / momentum encoder) of the student parameters.
- Compared to classical knowledge distillation, there are no human labels and no separate pretrained teacher. The supervision signal comes from the idea that “different augmented views of the same image should agree.”
Emerging Properties in Self-Supervised Vision Transformers (DINOv1, 2021)
Overview
This paper proposes DINO, a self-distillation framework with no labels, to pretrain ViTs. Besides the fact that the DINO method works quite well on this kind of architecture, there are also two interesting properties emerging from the learned features:
DINO features can be naturally applied for semantic segmentation (without fine-tuning):
- Just segment scenes with a nearest neighbor between consecutive frames can lead to competitive results on DAVIS-2017 benchmark;
- Different attention heads capture different semantic concepts (object parts, objects, background, etc).
DINO features also excel at classification tasks:
- Linear probing on ImageNet achieves 80.1% top-1 accuracy (ViT-B/8);
- k-NN classification (k=20) on ImageNet achieves 74.5% top-1 accuracy (ViT-S/16).
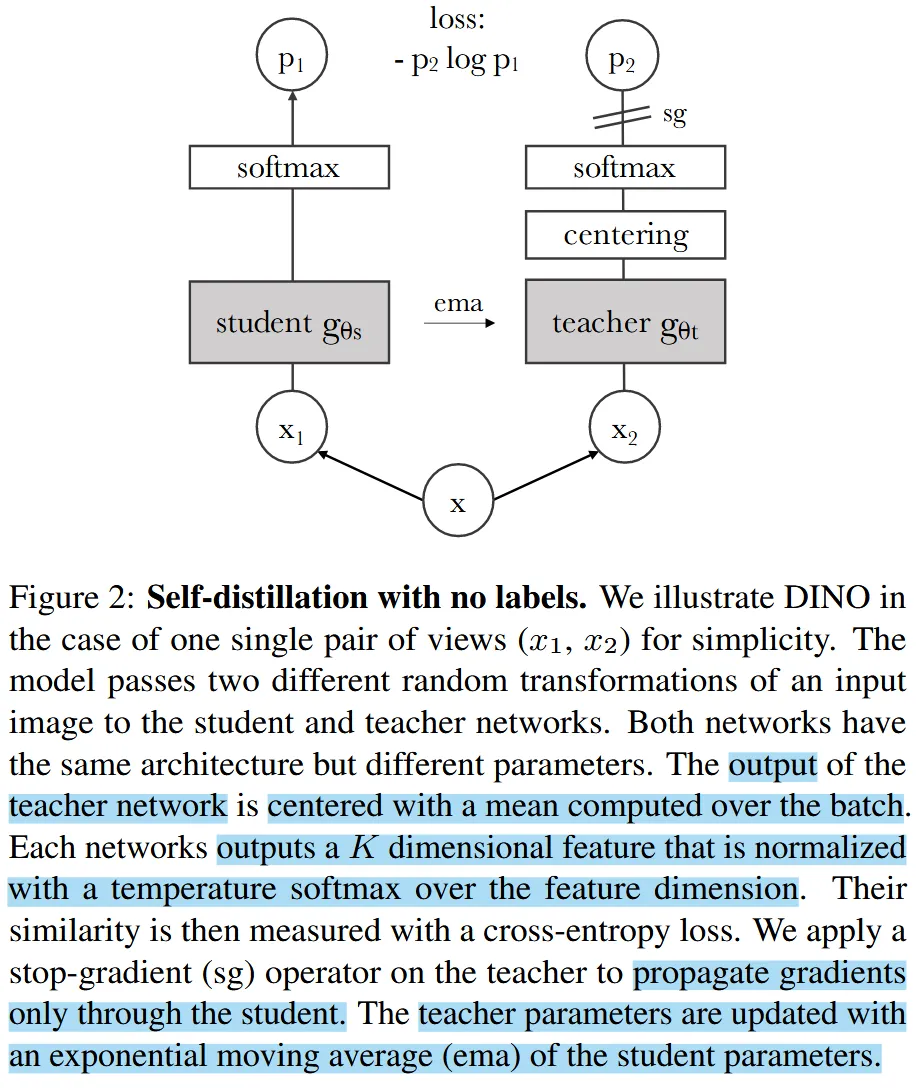
Self-Distillation means the DINO method involves two models—a student model and a teacher model, and both of the model share the same architecure but different parameters. Given a batch of input images , apply two different random transformations on it to get two views and .
- For the student model, after being feed with , it will output features ; then apply a Softmax operation with temperature on ‘s feature dimension to get a student probability distribution .
- For the teacher model, after output features when given , firstly center by subtracting a mean vector (dynamically updated during training), then apply the same Softmax operation with temperature to get the teacher probability distribution .
Finally, we want the two distributions to be as close as possible, so we minimize the cross-entropy loss between them:
Note that only the student model is updated by back-propagation; the teacher model’s parameters are updated by an exponential moving average (EMA) of the student model’s parameters:
# gs, gt: student and teacher
# C: center buffer
# tps, tpt: student/teacher temperature
# m_net, m_center: EMA momentum for network and center
gt.params = gs.params
for x in loader:
x_1, x_2 = augment_1(x), augment_2(x) # random augmentations
z_s1, z_s2 = gs(x_1), gs(x_2) # student forward
z_t1, z_t2 = gt(x_1), gt(x_2) # teacher forward
p_s1, p_s2 = softmax(z_s1 / tps), softmax(z_s2 / tps) # student prob
p_t1, p_t2 = softmax((z_t1 - C) / tpt), softmax((z_t2 - C) / tpt) # teacher prob
loss = 0.5 * (CE(p_t1, p_s2) + CE(p_t2, p_s1)) # cross-entropy loss
loss.backward()
gs_optimizer.zero_grad()
gs_optimizer.step() # update student
# update teacher by EMA
for p_s, p_t in zip(gs.params, gt.params):
p_t.data = m_net * p_t.data + (1 - m_net) * p_s.data
# update center
C = m_center * C + (1 - m_center) * mean([z_t1, z_t2])Technical Details
- Random Augmentation Strategy
Two major types of augmentations are applied here:- BYOL’s augmentation: color jittering, Gaussian blur and solarization;
- Multi-crop: each input image is transformed into 2 global views (224x224, covering most of the image) and 6–10 local crops (96x96, randomly sampled patches), constructing a set of views . The teacher only processes the global views, while the student processes all views (global + local). This design encourages the student to learn consistent representations across scales and promotes fine-grained semantic understanding—critical for downstream dense prediction tasks like segmentation.
Actual loss function:
Centering to Prevent Collapse
While there are multiple stablizing methods including constrastive loss, clustering constraints, predictor and batch normalizations, only a centering and sharpening of the momentum teacher outputs (via using a low value of ) is enough to avoid model collapse—a degenerate solution where all inputs map to the same feature.- Centering avoids the collapse induced by a dominant dimension, but encourages a uniform distribution.
- Sharpening prevents the model from outputting uniform distributions across all dimensions, while allowing some dimensions to dominate.
[CLS] token
An extra learnable token is prepended to the sequence, which acts to aggregate global information from the entire sequence. Although [CLS] token is primarily designed for supervised classification tasks, considering by adding a aggregative token can obtain similar benefits, we continue to use this name in DINO. A projection head is applied to the [CLS] token output to produce a global representation.Attention Maps for Different Heads Different attention heads in the pretrained ViT capture different semantic concepts. For example, some heads focus on object parts, while others attend to whole objects or background regions. This diversity in attention patterns allows the model to learn rich and varied representations that are useful for downstream tasks like segmentation.

Writing Tricks
Major Issue:
- Information Loss: Supervised pretraining usually reduces the rich visual information in an image to a single concept (label).
- Unlabeled Scales Up: Supervised pretraining requires large labeled datasets, which does not scale well with the increasing number of images.
Motivation: Self-supervised works well on NLP tasks, can be transferred to vision tasks?
Key Design: Like knowledge distillation.
iBOT: Image BERT Pre-Training with Online Tokenizer
- Paper: https://arxiv.org/abs/2111.07832
- One-liner: extends DINO-style self-distillation from mostly global/CLS supervision to token-level targets, and combines it with masked image modeling.
How to think about it
- DINO is closer to “make whole-image representations consistent across views”, while iBOT also “makes patch/token predictions consistent”.
- In practice, iBOT often yields better fine-grained features (more friendly to detection/segmentation).
DINOv2: Learning Robust Visual Features Without Any Labels
- Paper: https://arxiv.org/abs/2304.07193
- One-liner: scales the DINO/iBOT-style self-distillation recipe and refines training details to obtain very strong frozen features.
Main upgrades (reproduction-oriented)
- Larger/cleaner data and improved training recipe (augmentations, regularization, optimization hyperparameters).
- Uses token-level training signals (aligned with iBOT) plus more stable training details.
- The resulting ViT features transfer well to classification/retrieval/segmentation/depth, acting as a “general-purpose vision backbone”.