

前序工作
基本介绍
SAM3 (Segment Anything Model 3) 是 Meta AI 研究院开发的一款强大的图像分割模型,能够在各种图像上进行高效的分割任务。
Okay, clone 完项目的代码后,在 README.md 中可以看到 SAM3 的基本结构图。
模型结构
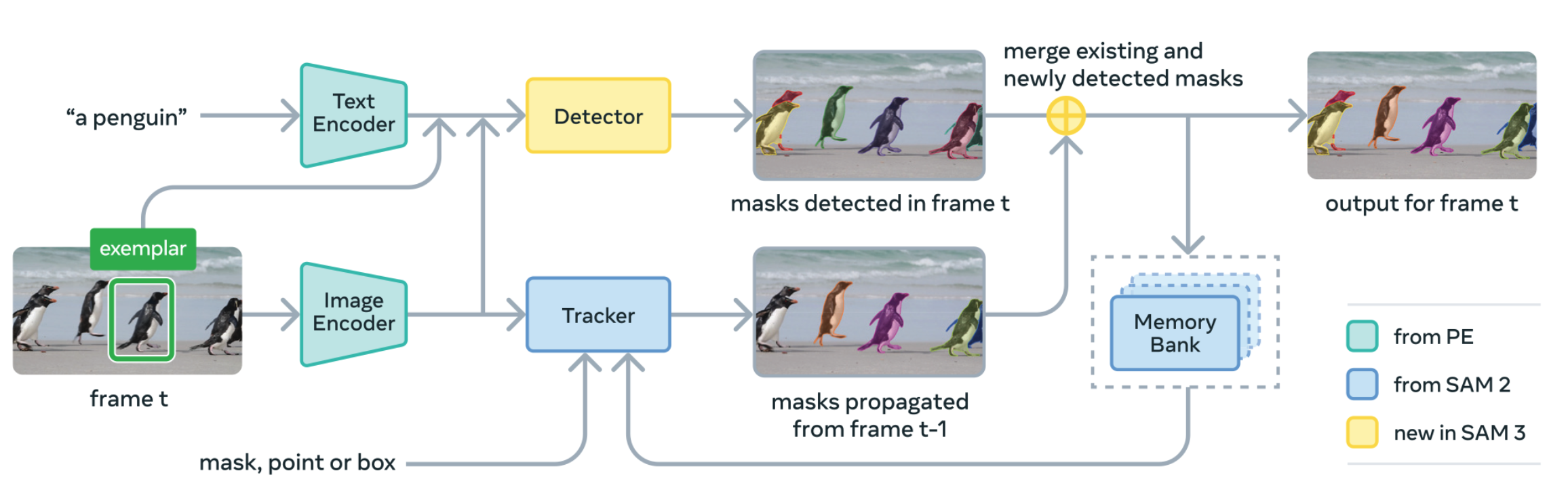
README.md 中是这样介绍 SAM3 的:
SAM 3 is a unified foundation model for promptable segmentation in images and videos. It can detect, segment, and track objects using text or visual prompts such as points, boxes, and masks. Compared to its predecessor SAM 2, SAM 3 introduces the ability to exhaustively segment all instances of an open-vocabulary concept specified by a short text phrase or exemplars. Unlike prior work, SAM 3 can handle a vastly larger set of open-vocabulary prompts. It achieves 75-80% of human performance on our new SA-CO benchmark which contains 270K unique concepts, over 50 times more than existing benchmarks.
This breakthrough is driven by an innovative data engine that has automatically annotated over 4 million unique concepts, creating the largest high-quality open-vocabulary segmentation dataset to date. In addition, SAM 3 introduces a new model architecture featuring a presence token that improves discrimination between closely related text prompts (e.g., “a player in white” vs. “a player in red”), as well as a decoupled detector–tracker design that minimizes task interference and scales efficiently with data.
相较于 SAM2,SAM3 的改进主要体现在以下几个方面:
- 能力质变:从依赖点、框的视觉提示进化为理解开放词汇文本,能自动找出画面中所有符合描述(如“穿红衣的球员”)的实例。
- 架构解耦:采用 Detector(负责理解语义)与Tracker(负责时序传播)分离的设计,共享主干网络以减少任务干扰并提升扩展性。
- 判别精准:引入 Presence Token 机制,专门用于区分相似文本描述(如颜色、属性差异),显著提升了语义判别的准确率。
配置环境
参考 README.md 中的说明,作如下配置(注意这个只适用于 Linux/macOS 系统)
conda create -n sam3 python=3.12 -y
conda activate sam3
cd sam3
pip install torch==2.10.0 torchvision --index-url https://download.pytorch.org/whl/cu128
pip install -e .
# Additional dependencies for training and evaluation
# For running example notebooks
pip install -e ".[notebooks]"
# For development
pip install -e ".[train,dev]"
# Optional dependencies for faster inference
pip install einops ninja
pip install flash-attn-3 --no-deps --index-url https://download.pytorch.org/whl/cu128
pip install git+https://github.com/ronghanghu/cc_torch.gitPython 3.12 以上版本将弃用 pkg_resources 模块,而且在 Windows 版本的 Python 解释器中,这个模块已经被完全移除了,但是 SAM3 开发是在 Linux 上进行的,而且还使用了这个古老的模块,因此在 Windows 系统上直接安装 SAM3 的依赖会遇到兼容性问题。 对于 Windows 系统,建议使用 WSL 来配置环境。如果已经安装好了 UV,可以使用如下 pyproject.toml 来配置环境:
[build-system]
requires = ["setuptools>=61", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "sam_unified"
version = "0.1.0"
description = "Unified Segment Anything Model (SAM 2 & 3) implementation"
readme = "README.md"
requires-python = ">=3.12"
license = {text = "MIT"}
authors = [
{name = "Meta AI Research"}
]
classifiers = [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
]
dependencies = [
"torch>=2.7",
"torchvision",
"timm>=1.0.17",
"numpy>=1.26,<2",
"tqdm",
"ftfy==6.1.1",
"regex",
"iopath>=0.1.10",
"typing_extensions",
"huggingface_hub",
"pillow",
"einops",
"pycocotools",
"psutil",
"triton",
"scipy",
"opencv-python",
"modelscope",
]
[project.optional-dependencies]
dev = [
"pytest",
"pytest-cov",
"black==24.2.0",
"ufmt==2.8.0",
"ruff-api==0.1.0",
"usort==1.0.2",
"gitpython==3.1.31",
"yt-dlp",
"pandas",
"opencv-python",
"pycocotools",
"numba",
"python-rapidjson",
]
notebooks = [
"matplotlib",
"jupyter",
"notebook",
"ipywidgets",
"ipycanvas",
"ipympl",
"pycocotools",
"decord",
"opencv-python",
"einops",
"scikit-image",
"scikit-learn",
]
train = [
"hydra-core",
"submitit",
"tensorboard",
"zstandard",
"scipy",
"torchmetrics",
"fvcore",
"fairscale",
"scikit-image",
"scikit-learn",
]
[tool.setuptools.packages.find]
include = ["sam2*", "sam3*"]
[tool.uv]
index-url = "https://mirrors.aliyun.com/pypi/simple/"
extra-index-url = ["https://download.pytorch.org/whl/cu128"]
index-strategy = "unsafe-best-match"预训练模型下载
SAM3 的模型权重不像 SAM, SAM2 那样提供了 .pt 权重文件,而是必须通过 huggingface 平台获取,而且还需要提交使用申请。
考虑到申请 SAM3 的模型权重非常的容易被拒绝,这里推荐使用魔塔社区先下载模型权重,再用 huggingface 加载的方式:
# 确保已经安装了 modelscope
pip install modelscope
# 下载 SAM3 模型权重
modelscope download --model facebook/sam3
# 下载 SAM3.1 模型权重
modelscope download --model facebook/sam3.1下载完成后,在 modelscope 的本地 repo 文件中可以直接看到 sam3.pt 和 sam3.1_multiplex.pt 的权重文件的,这个时候可以直接使用
model = build_sam3_image_model(load_from_HF=False, checkpoint_path="your/path/to/sam3.pt")的方式来加载模型权重了,下面的接口展示也是以这个加载方式为例。需要注意的是,如果是 Windows WSL 加载模型的话,路径开头不是 Windows 格式,而是 /mnt/d (D 盘) 这样的格式。
官方使用接口
数据类型 Debug
由于 SAM3 的发布时间距今并不长,因此官方代码中仍然存在不少的 bugs。在运行官方接口之前,需要先修改 sam3/sam3/perflib/fused.py 中的 addmm_act() 函数:
def addmm_act(activation, linear, mat1):
if torch.is_grad_enabled():
raise ValueError("Expected grad to be disabled.")
self = linear.bias.detach()
mat2 = linear.weight.detach()
# keep the original dtype so we can cast the result back
out_dtype = linear.weight.dtype if hasattr(linear, "weight") else mat1.dtype
self = self.to(torch.bfloat16)
mat1 = mat1.to(torch.bfloat16)
mat2 = mat2.to(torch.bfloat16)
mat1_flat = mat1.view(-1, mat1.shape[-1])
if activation in [torch.nn.functional.relu, torch.nn.ReLU]:
y = addmm_act_op(self, mat1_flat, mat2.t(), beta=1, alpha=1, use_gelu=False)
return y.view(mat1.shape[:-1] + (y.shape[-1],)).to(out_dtype)
if activation in [torch.nn.functional.gelu, torch.nn.GELU]:
y = addmm_act_op(self, mat1_flat, mat2.t(), beta=1, alpha=1, use_gelu=True)
return y.view(mat1.shape[:-1] + (y.shape[-1],)).to(out_dtype)
raise ValueError(f"Unexpected activation {activation}")修改完成后,就可以运行下列代码了。
单张图像预测——文本提示
import torch
from PIL import Image
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
# Load the model
model = build_sam3_image_model(load_from_HF=False, checkpoint_path="your/path/to/sam3.pt")
print(model.device)
processor = Sam3Processor(model)
# Load an image
image = Image.open("input.jpg")
inference_state = processor.set_image(image)
# Prompt the model with text
output = processor.set_text_prompt(state=inference_state, prompt="A man in the red.")
# Get the masks, bounding boxes, and scores
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]输出的 output 是一个字典,格式如下:
{
"original_height": int, # 输入图像的原始高度 H
"original_width": int, # 输入图像的原始宽度 W
# 视觉-语言骨干网络输出(SAM3VLBackbone)
"backbone_out": dict( # 主干网络的输出特征图
"vision_features": Tensor, # 多尺度视觉特征图 [B, 256, 72, 72]
"vision_pos_enc": list[Tensor], # 位置编码(多层级),len=3
"backbone_fpn": list[Tensor], # FPN 各层输出,len=3
"sam2_backbone_out": dict | None, # SAM2 兼容模式输出
# 文本提示编码器输出
"language_features": Tensor, # 文本语义特征 (seq_len, B, 256)
"language_mask": boolean Tensor, # Attention掩码 (B, seq_len)
"language_embeds": Tensor, # Token级嵌入 (seq_len, B, 1024)
),
# 几何提示编码器输出
"geometric_prompt": Prompt Object, # 编码后的点、框、掩码几何提示
# 检测解码器最终输出
"masks_logits": Tensor, # 原始logits (N, 1, H, W)
"masks": boolean Tensor, # 二值掩码 (N, 1, H, W)
"boxes": Tensor, # 边界框 (N, 4) (x1, y1, x2, y2)
"scores": Tensor, # 置信度分数 (N, )
}视频预测器修改
考虑到我们使用的不是 huggingface 上的模型权重,因此需要为 sam3/sam3/model/sam3_video_predictor.py 添加 load_from_HF 参数:
class Sam3VideoPredictor(Sam3BasePredictor):
def __init__(
self,
checkpoint_path=None,
load_from_HF=True, # 新增参数,控制是否从 huggingface 加载模型权重
bpe_path=None,
has_presence_token=True,
geo_encoder_use_img_cross_attn=True,
strict_state_dict_loading=True,
async_loading_frames=False,
video_loader_type="cv2",
apply_temporal_disambiguation: bool = True,
compile: bool = False,
):
super().__init__()
self.async_loading_frames = async_loading_frames
self.video_loader_type = video_loader_type
from sam3.model_builder import build_sam3_video_model
self.model = (
build_sam3_video_model(
checkpoint_path=checkpoint_path,
load_from_HF=load_from_HF, # 传递参数控制加载方式
bpe_path=bpe_path,
has_presence_token=has_presence_token,
geo_encoder_use_img_cross_attn=geo_encoder_use_img_cross_attn,
strict_state_dict_loading=strict_state_dict_loading,
apply_temporal_disambiguation=apply_temporal_disambiguation,
compile=compile,
)
.cuda()
.eval()
)
# 其余功能函数不做修改
...这是因为 build_sam3_video_model 函数中确实有 load_from_HF 的参数控制,但是在 Sam3VideoPredictor 的构造函数中并没有传递这个参数,因此默认是从 huggingface 加载模型权重的,这样就会导致我们无法使用本地下载的模型权重了。
结合文本提示的视频预测
from sam3.model_builder import build_sam3_video_predictor
def video_predict(video_path: str, text_prompt: str, sam3_checkpoint_path: str = "your/path/to/sam3.pt"):
# 加载模型
video_predictor = build_sam3_video_predictor(
load_from_HF=False,
checkpoint_path=sam3_checkpoint_path
)
# 开启一个 session,逐帧把视频的 RGB 像素压缩成特征图
start_response = video_predictor.handle_request(
request=dict(
type="start_session",
resource_path=video_path,
)
)
# 得到 session_id,后续的所有请求都要带上这个 ID,底层才能把它们关联到同一个视频上,进行正确的时序跟踪和掩码传播
# 模型可以同时处理不同的 sessions,每个 session 代表一个视频,互不干扰
session_id = start_response["session_id"]
print("Session started with ID:", session_id)
# 为当前的 session 增加文本提示,触发给定帧的 Mask 预测
response = video_predictor.handle_request(
request=dict(
type="add_prompt",
session_id=session_id,
frame_index=0, # 可以是任意的帧
text=text_prompt,
)
)
# 观察初始检测到多少个与文本提示相关的对象(Mask),这些对象都会被记录,并在整个视频中被跟踪
output = response["outputs"]
print(f"The number of initial predicted objects related to the prompt \"{text_prompt}\" is ", len(output.get("out_binary_masks", [])))
print("---------- Starting Video Propagation ----------")
outputs_per_frame = {}
for stream_resp in video_predictor.handle_stream_request(
request=dict(
type="propagate_in_video",
session_id=session_id,
)
):
f_idx = stream_resp["frame_index"] # 异步执行,实际上 tqdm 的进度条和帧预测的时间进度是不同的,预测帧的操作比特征提取的操作要慢好几个时间步
outputs_per_frame[f_idx] = stream_resp["outputs"]
return outputs_per_frame
video_path = "your/path/to/video.mp4" # 或者 "your/path/to/image_folder" (JPG 图像文件夹或视频文件)
text_prompt = "People"
outputs_per_frame = video_predict(video_path, text_prompt)输出的 outputs_per_frame 是一个字典套字典,键是帧索引,值是一个包含预测结果的字典。每一帧的预测结果的字典格式如下:
{
# 对象标识
"out_obj_ids": np.ndarray[int64], # 形状: (N,),跟踪对象的唯一ID
# 置信度分数
"out_probs": np.ndarray[float32], # 形状: (N,),每个对象的检测置信度
# 边界框(归一化坐标)
"out_boxes_xywh": np.ndarray[float32], # 形状: (N, 4),格式: [x_center, y_center, width, height]
# ⚠️ 注意:是中心点坐标 + 宽高,且是归一化的(0-1范围)
# 二值掩码
"out_binary_masks": np.ndarray[bool], # 形状: (N, H, W),每个对象的像素级分割掩码,这个也是最常用的预测掩码结果
# 帧统计信息
"frame_stats": {
"num_obj_tracked": int, # 当前成功跟踪的对象数量
"num_obj_dropped": int # 丢失/被丢弃的对象数量
}
}SAM3 接口文档
本文档记录了 SAM 3 (包括 SAM 3.1 Multiplex) 项目中所有的核心预测类、特征提取类、核心组件极其所有的内部方法。相较于 SAM 2,SAM 3/3.1 在架构的广度与抽象调度上进行了成倍扩充,以支持多目标(Multiplex)、视觉-语言多模态关联(Text/Vision-Language Prompts)及高并发会话(Session)。
1. 顶层分发控制器与预测机 (Predictors & Top-level Wrappers)
1.1 Sam3BasePredictor (model/sam3_base_predictor.py)
类作用: SAM 3 和 SAM 3.1 视频预测器的共享底层基类,提供统一的推流、请求接管与长驻内存的会话注册表(Session Manager)机制。负责会话管理(启动、重置、关闭)、请求分发(handle_request / handle_stream_request)以及通用的 add_prompt / propagate_in_video / remove_object / reset_session / close_session 方法。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
model | nn.Module 或 None | None | 底层 SAM3 模型,子类必须设置 |
_all_inference_states | Dict[str, dict] | {} | 会话ID到推理状态的映射,记录多个视频独立追踪并发状态 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 无 | 无 | 初始化基础预测器,设置 model 和 _all_inference_states 为 None/空字典 |
handle_request | request: dict (type: str, …) | dict 或抛出异常 | 根据请求类型分发到对应方法(start_session, add_prompt, remove_object, reset_session, cancel_propagation, close_session) |
handle_stream_request | request: dict (type: str, …) | 生成器,yield dict | 处理流式请求,目前仅支持 propagate_in_video 类型,返回帧结果流 |
start_session | resource_path: strsession_id: str 或 Noneoffload_video_to_cpu: bool = False | {"session_id": str} | 启动新推理会话,加载视频资源,初始化模型状态,分配唯一会话ID |
add_prompt | session_id: strframe_idx: inttext: str 或 Nonepoints: [P,2] 或 Nonepoint_labels: [P] 或 Noneclear_old_points: bool = Truebounding_boxes: [B,4] 或 Nonebounding_box_labels: [B] 或 Noneclear_old_boxes: bool = Trueoutput_prob_thresh: float = 0.5obj_id: int 或 None | {"frame_index": int, "outputs": dict} | 在指定视频帧添加文本、点和/或框提示,运行单帧推理,返回临时输出 |
remove_object | session_id: strframe_idx: int = 0obj_id: int = 0is_user_action: bool = True | {"frame_index": int, "outputs": dict} | 从跟踪中移除对象,清理相关状态,返回更新后的掩码(可能为空) |
cancel_propagation | session_id: str | {"is_success": bool} | 取消正在进行的传播(如果模型支持) |
propagate_in_video | session_id: strpropagation_direction: str = “both”start_frame_idx: int 或 Nonemax_frame_num_to_track: int 或 Noneoutput_prob_thresh: float = 0.5**kwargs | 生成器,yield {"frame_index": int, "outputs": dict} | 将已添加的提示传播到所有视频帧,支持正向、反向或双向传播 |
reset_session | session_id: str | {"is_success": bool} | 重置会话到初始状态,清空所有提示和跟踪结果 |
close_session | session_id: strrun_gc_collect: bool = True | {"is_success": bool} | 关闭会话,释放资源,可选运行垃圾回收 |
_get_session | session_id: str | dict (会话对象) | 内部方法,根据会话ID获取会话字典,不存在则抛出异常 |
_extend_expiration_time | session: dict | 无 | 更新会话的最后使用时间,用于会话过期跟踪 |
shutdown | 无 | 无 | 关闭预测器,清空所有会话 |
1.2 Sam3MultiplexVideoPredictor (model/sam3_multiplex_video_predictor.py)
类作用: 面向用户的 SAM 3.1 Multiplex(多路复用多目标追踪)预测容器。集成了 BF16 精度上下文和 Torch Dynamo (torch.compile) 预热机制。包装了 Sam3MultiplexTrackingWithInteractivity,提供 bf16 自动转换、预热编译、会话过期管理以及从 Sam3BasePredictor 继承的 handle_request / handle_stream_request 分发 API。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
model | Sam3MultiplexTrackingWithInteractivity | 无 | 底层多路复用跟踪模型 |
session_expiration_sec | int | 1200 | 会话过期时间(秒) |
default_output_prob_thresh | float | 0.5 | 默认输出概率阈值 |
async_loading_frames | bool | True | 是否异步加载视频帧 |
bf16_context | torch.autocast | 启用 bfloat16 的上下文 | 用于 Flash Attention 内核的 bfloat16 自动转换上下文 |
_all_inference_states (继承) | Dict[str, dict] | {} | 来自 Sam3BasePredictor 的会话映射 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | model: Sam3MultiplexTrackingWithInteractivitysession_expiration_sec: int = 1200default_output_prob_thresh: float = 0.5async_loading_frames: bool = Truewarm_up: bool = False | 无 | 初始化预测器,设置模型和配置,启用 TF32 和 BF16,可选预热编译 |
_extend_expiration_time | session: dict | 无 | 更新会话的最后使用时间,并存储会话过期超时时间 |
注意:此类继承自 Sam3BasePredictor,因此也拥有所有基类方法(handle_request、start_session、add_prompt 等)。
1.3 Sam3VideoPredictor (model/sam3_video_predictor.py)
类作用: 非复用(Non-multiplex)版本的基础 SAM 3 Tracker 的对外用户封装,保持了与 SAM 2 SAM2VideoPredictor 极为相似的接口风格(以向后兼容单目标/精简模式追踪)。继承自 Sam3BasePredictor,负责加载 SAM3 视频模型,提供单 GPU 推理。同时包含多 GPU 扩展类 Sam3VideoPredictorMultiGPU 以支持分布式推理。
属性表格 (Sam3VideoPredictor):
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
model | nn.Module | 无 | 通过 build_sam3_video_model 构建的 SAM3 视频模型 |
async_loading_frames | bool | False | 是否异步加载视频帧 |
video_loader_type | str | "cv2" | 视频加载器类型(如 “cv2”) |
_all_inference_states (继承) | Dict[str, dict] | {} | 来自 Sam3BasePredictor 的会话映射 |
方法表格 (Sam3VideoPredictor):
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | checkpoint_path: str 或 Nonebpe_path: str 或 Nonehas_presence_token: bool = Truegeo_encoder_use_img_cross_attn: bool = Truestrict_state_dict_loading: bool = Trueasync_loading_frames: bool = Falsevideo_loader_type: str = “cv2”apply_temporal_disambiguation: bool = Truecompile: bool = False | 无 | 初始化预测器,构建 SAM3 视频模型并移至 GPU |
remove_object | session_id: strframe_idx: int = 0obj_id: int = 0is_user_action: bool = True | {"is_success": bool} | 移除跟踪对象(简化 API,直接调用模型的 remove_object) |
_get_session_stats | 无 | str | 获取活动会话统计信息和 GPU 内存使用情况 |
_get_torch_and_gpu_properties | 无 | str | 获取 PyTorch 和 GPU 属性字符串 |
类 Sam3VideoPredictorMultiGPU (继承自 Sam3VideoPredictor):
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
gpus_to_use | List[int] | 当前 GPU 设备列表 | 要使用的 GPU ID 列表 |
rank | int | 从环境变量 RANK 读取 | 当前进程的排名 |
world_size | int | 从环境变量 WORLD_SIZE 读取 | 进程总数 |
rank_str | str | 自动生成 | 排名和世界大小的字符串表示 |
device | torch.device | cuda:{gpus_to_use[rank]} | 当前进程的设备 |
has_shutdown | bool | False | 是否已关闭 |
command_queues | Dict[int, mp.Queue] | None | 与工作进程通信的命令队列 |
result_queues | Dict[int, mp.Queue] | None | 结果队列 |
worker_pids | Dict[int, int] | None | 工作进程的 PID |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | *model_args, gpus_to_use=None, **model_kwargs | 无 | 初始化多 GPU 预测器,设置分布式环境,启动工作进程 |
handle_request | request: dict | dict | 分发请求到所有工作进程(主进程) |
handle_stream_request | request: dict | 生成器,yield dict | 分发流式请求到所有工作进程 |
_start_worker_processes | *model_args, **model_kwargs | 无 | 启动工作进程 |
_start_nccl_process_group | 无 | 无 | 初始化 NCCL 进程组,执行预热 all-reduce |
_find_free_port | 无 | int | 查找空闲端口用于分布式通信 |
_worker_process_command_loop (静态方法) | rank, world_size, command_queue, result_queue, model_args, model_kwargs, gpus_to_use, parent_pid | 无 | 工作进程的命令循环,监听并执行命令 |
shutdown | 无 | 无 | 关闭所有工作进程,销毁进程组 |
1.4 Sam3Processor (model/sam3_image_processor.py)
类作用: 面向单张/多张无关图像推理过程的封装调度机,自动处理 torchvision.transforms.v2 以及基础数据状态对齐。负责图像预处理、文本/几何提示添加、前向推理及结果后处理。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
model | nn.Module | 无 | 底层 SAM3 模型 |
resolution | int | 1008 | 输入图像分辨率(调整大小后的边长) |
device | str 或 torch.device | "cuda" | 计算设备 |
transform | torchvision.transforms.v2.Compose | 预处理流水线 | 图像转换:缩放、归一化等 |
confidence_threshold | float | 0.5 | 置信度阈值,用于过滤预测结果 |
find_stage | FindStage | 预初始化的查找阶段对象 | 包含文本ID、图像ID等,用于前向传播 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | model: nn.Moduleresolution: int = 1008device: str = “cuda”confidence_threshold: float = 0.5 | 无 | 初始化处理器,设置模型、分辨率、设备及预处理流水线 |
set_image | image: PIL.Image 或 Tensor 或 np.ndarraystate: dict 或 None | state: dict | 设置单张图像,提取主干特征并存入状态字典 |
set_image_batch | images: List[PIL.Image]state: dict 或 None | state: dict | 设置图像批次,提取主干特征并存入状态字典 |
set_text_prompt | prompt: strstate: dict | state: dict | 设置文本提示,运行推理,返回更新后的状态(包含检测框、掩码、分数) |
add_geometric_prompt | box: List[float] ([center_x, center_y, width, height],归一化到 [0,1])label: bool (True 为正,False 为负)state: dict | state: dict | 添加几何框提示,运行推理,返回更新后的状态 |
reset_all_prompts | state: dict | 无 | 清除所有提示和结果,重置状态字典中的相关键 |
set_confidence_threshold | threshold: floatstate: dict 或 None | state: dict 或 None | 设置置信度阈值,若提供状态则重新过滤结果 |
_forward_grounding | state: dict | state: dict | 内部前向传播,调用模型的 forward_grounding,处理输出并更新状态 |
2. 视频与时序追踪逻辑引擎 (Video & Tracking Base Models)
2.1 Sam3TrackerBase (model/sam3_tracker_base.py)
类作用: SAM 3 视频跟踪的核心基类,整合图像主干网络、Transformer 编码器模块和过去帧记忆的 Cross-Attention 系统。负责管理时序记忆、特征融合、SAM 头推理以及帧间跟踪状态维护。继承自 torch.nn.Module,是所有跟踪器的基础架构。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
backbone | nn.Module | 无 | 图像主干网络,用于提取视觉特征 |
num_feature_levels | int | 3 | 特征金字塔层级数量 |
max_obj_ptrs_in_encoder | int | 从参数传入 (默认 16) | 编码器中最大对象指针数量 |
mask_downsample | nn.Conv2d | Conv2d(1, 1, kernel_size=4, stride=4) | 将 GT 掩码下采样到 stride 4 的卷积层 |
transformer | nn.Module | 无 | 仅编码器的 Transformer,用于融合当前帧视觉特征与过去帧记忆 |
hidden_dim | int | transformer.d_model | Transformer 隐藏维度 |
maskmem_backbone | nn.Module | 无 | 记忆编码器骨干网络(如 SimpleMaskEncoder) |
mem_dim | int | hidden_dim 或 maskmem_backbone.out_proj.weight.shape[0] | 记忆特征维度 |
num_maskmem | int | 从参数传入 (默认 7) | 可访问的记忆数量(1 输入帧 + 6 历史帧) |
maskmem_tpos_enc | nn.Parameter | torch.zeros(num_maskmem, 1, 1, mem_dim) | 记忆的时间位置编码 |
no_mem_embed | nn.Parameter | torch.zeros(1, 1, hidden_dim) | 表示无记忆嵌入的 token |
no_mem_pos_enc | nn.Parameter | torch.zeros(1, 1, hidden_dim) | 无记忆位置编码 |
sigmoid_scale_for_mem_enc | float | 20.0 | 记忆编码器 sigmoid 缩放因子 |
sigmoid_bias_for_mem_enc | float | -10.0 | 记忆编码器 sigmoid 偏置 |
non_overlap_masks_for_mem_enc | bool | 从参数传入 (默认 False) | 是否在记忆编码中对掩码应用非重叠约束 |
memory_temporal_stride_for_eval | int | 从参数传入 (默认 1) | 评估时记忆库的时间步长(类似 XMem 的 r 参数) |
multimask_output_in_sam | bool | 从参数传入 (默认 False) | 是否在初始条件帧上输出多个掩码 |
multimask_min_pt_num | int | 从参数传入 (默认 1) | 使用多掩码输出的最小点数 |
multimask_max_pt_num | int | 从参数传入 (默认 1) | 使用多掩码输出的最大点数 |
multimask_output_for_tracking | bool | 从参数传入 (默认 False) | 是否在跟踪时也使用多掩码输出 |
image_size | int | 从参数传入 (默认 1008) | 输入图像尺寸 |
backbone_stride | int | 从参数传入 (默认 14) | 图像主干输出步长 |
low_res_mask_size | int | image_size // backbone_stride * 4 | 低分辨率掩码尺寸 |
input_mask_size | int | low_res_mask_size * 4 | 输入掩码尺寸 |
forward_backbone_per_frame_for_eval | bool | 从参数传入 (默认 False) | 评估时是否逐帧前向传播主干网络以避免 OOM |
offload_output_to_cpu_for_eval | bool | 从参数传入 (默认 False) | 评估时是否将输出卸载到 CPU 内存以避免 GPU OOM |
trim_past_non_cond_mem_for_eval | bool | 从参数传入 (默认 False) | 评估时是否修剪过去的非条件帧记忆以节省内存 |
sam_mask_decoder_extra_args | dict 或 None | 从参数传入 (默认 None) | 传递给 SAM 掩码解码器的额外参数 |
no_obj_ptr | nn.Parameter | torch.zeros(1, hidden_dim) | 无对象指针 |
no_obj_embed_spatial | nn.Parameter | torch.zeros(1, mem_dim) | 空间记忆的无对象嵌入 |
sam_prompt_encoder | PromptEncoder | 构建时创建 | SAM 提示编码器 |
sam_mask_decoder | MaskDecoder | 构建时创建 | SAM 掩码解码器 |
obj_ptr_proj | MLP | MLP(hidden_dim, hidden_dim, hidden_dim, 3) | 对象指针投影层 |
obj_ptr_tpos_proj | nn.Linear | Linear(hidden_dim, mem_dim) | 对象指针时间位置投影层 |
max_cond_frames_in_attn | int | 从参数传入 (默认 -1,无限制) | 注意力中最大条件帧数 |
keep_first_cond_frame | bool | 从参数传入 (默认 False) | 是否始终保留第一个条件帧 |
use_memory_selection | bool | 从参数传入 (默认 False) | 是否使用记忆选择(类似 SAM2Long) |
mf_threshold | float | 从参数传入 (默认 0.01) | 记忆选择的阈值 |
compile_all_components | bool | 从参数传入 (默认 False) | 是否编译所有组件 |
device (property) | torch.device | 自动计算 | 模型参数所在的设备 |
初始化参数表格 (传递给 __init__ 的配置):
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
backbone | nn.Module | 无 | 图像主干网络 |
transformer | nn.Module | 无 | 仅编码器的 Transformer |
maskmem_backbone | nn.Module | 无 | 记忆编码器骨干网络 |
num_maskmem | int | 7 | 可访问的记忆数量 |
image_size | int | 1008 | 输入图像尺寸 |
backbone_stride | int | 14 | 图像主干输出步长 |
max_cond_frames_in_attn | int | -1 | 注意力中最大条件帧数(-1 表示无限制) |
keep_first_cond_frame | bool | False | 是否始终保留第一个条件帧 |
multimask_output_in_sam | bool | False | 是否在初始条件帧上输出多个掩码 |
multimask_min_pt_num | int | 1 | 使用多掩码输出的最小点数 |
multimask_max_pt_num | int | 1 | 使用多掩码输出的最大点数 |
multimask_output_for_tracking | bool | False | 是否在跟踪时也使用多掩码输出 |
forward_backbone_per_frame_for_eval | bool | False | 评估时是否逐帧前向传播主干网络 |
memory_temporal_stride_for_eval | int | 1 | 评估时记忆库的时间步长 |
offload_output_to_cpu_for_eval | bool | False | 评估时是否将输出卸载到 CPU 内存 |
trim_past_non_cond_mem_for_eval | bool | False | 评估时是否修剪过去的非条件帧记忆 |
non_overlap_masks_for_mem_enc | bool | False | 是否在记忆编码中对掩码应用非重叠约束 |
max_obj_ptrs_in_encoder | int | 16 | 编码器中最大对象指针数量 |
sam_mask_decoder_extra_args | dict 或 None | None | 传递给 SAM 掩码解码器的额外参数 |
compile_all_components | bool | False | 是否编译所有组件 |
use_memory_selection | bool | False | 是否使用记忆选择 |
mf_threshold | float | 0.01 | 记忆选择的阈值 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 见上表 | 无 | 初始化跟踪器基类,构建 SAM 头组件 |
_get_tpos_enc | rel_pos_list, device, max_abs_pos=None, dummy=False | tensor: [len(rel_pos_list), mem_dim] | 获取时间位置编码 |
_build_sam_heads | 无 | 无 | 构建 SAM 风格的提示编码器和掩码解码器 |
_forward_sam_heads | backbone_features, point_inputs=None, mask_inputs=None, high_res_features=None, multimask_output=False, gt_masks=None | 元组: (low_res_multimasks, high_res_multimasks, ious, low_res_masks, high_res_masks, obj_ptr, object_score_logits) | 前向传播 SAM 提示编码器和掩码头 |
_use_mask_as_output | backbone_features, high_res_features, mask_inputs | 元组: (low_res_masks, high_res_masks, ious, low_res_masks, high_res_masks, obj_ptr, object_score_logits) | 直接将二进制掩码输入转换为输出掩码 logits,绕过 SAM |
forward | input: BatchedDatapoint, is_inference=False | 抛出 NotImplementedError | 抽象前向方法,需在子类中实现 |
forward_image | img_batch | dict: 骨干网络输出 | 获取输入批次的图像特征 |
_prepare_backbone_features | backbone_out | 元组: (backbone_out, vision_feats, vision_pos_embeds, feat_sizes) | 准备并展平视觉特征(类似 MDETR_API) |
_prepare_backbone_features_per_frame | img_batch, img_ids | 元组: (image, vision_feats, vision_pos_embeds, feat_sizes) | 为给定图像 ID 动态计算图像骨干特征 |
cal_mem_score | object_score_logits, iou_score | float: 记忆分数 | 计算当前掩码被记入历史追踪记忆池的重要程度 |
frame_filter | output_dict, track_in_reverse, frame_idx, num_frames, r | List[int]: 有效帧索引列表 | 帧级时序筛选器,抛弃置信度低的信息 |
_prepare_memory_conditioned_features | frame_idx, is_init_cond_frame, current_vision_feats, current_vision_pos_embeds, feat_sizes, output_dict, num_frames, track_in_reverse=False, use_prev_mem_frame=True | tensor: [B, C, H, W] | 将当前帧的视觉特征与先前记忆融合 |
_encode_new_memory | image, current_vision_feats, feat_sizes, pred_masks_high_res, object_score_logits, is_mask_from_pts, output_dict=None, is_init_cond_frame=False | 元组: (maskmem_features, maskmem_pos_enc) | 将当前图像及其预测编码为记忆特征 |
forward_tracking | backbone_out, input, return_dict=False | list 或 dict: 所有帧的输出 | 在每个帧上执行视频跟踪(并采样校正点击) |
track_step | frame_idx, is_init_cond_frame, current_vision_feats, current_vision_pos_embeds, feat_sizes, image, point_inputs, mask_inputs, output_dict, num_frames, track_in_reverse=False, run_mem_encoder=True, prev_sam_mask_logits=None, use_prev_mem_frame=True | dict: 当前帧的输出 | 单帧跟踪步骤,处理提示并生成掩码预测 |
_use_multimask | is_init_cond_frame, point_inputs | bool: 是否使用多掩码输出 | 决定是否在 SAM 头中使用多掩码输出 |
_apply_non_overlapping_constraints | pred_masks | tensor: 应用非重叠约束后的掩码 | 对预测掩码应用非重叠约束(在批量维度) |
_compile_all_components | 无 | 无 | 编译所有模型组件以加速推理 |
_maybe_clone | x | tensor: 克隆或原始张量 | 如果 compile_all_components 为 True 则克隆张量 |
静态方法:
concat_points(old_point_inputs, new_points, new_labels): 将新点和标签添加到先前的点输入中(添加到末尾)。
2.2 Sam3MultiplexTracking 等族系 (sam3_multiplex_tracking.py)
类作用: SAM 3.1 多路复用(Multiplex)多目标跟踪的核心实现族系,继承自 Sam3MultiplexBase(进而继承 Sam3VideoBase)。承担同时跟踪数十个甚至上百个交织目标的复杂管理任务,支持多GPU分布式推理、热启动延迟(hotstart)、掩码确认(masklet confirmation)、批处理后处理等高级特性。族系包含三个主要类:Sam3MultiplexTracking(基础版本)、Sam3MultiplexTrackingProd(生产版本,支持批处理视频)和 Sam3MultiplexTrackingWithInteractivity(交互增强版本,支持用户操作历史记录与部分传播)。
2.2.1 Sam3MultiplexTracking 基础类
继承关系: Sam3MultiplexTracking → Sam3MultiplexBase → Sam3VideoBase
属性表格 (Sam3MultiplexTracking 特有属性):
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
image_size | int | 1008 | 输入图像尺寸 |
image_mean | tuple | (0.5, 0.5, 0.5) | 图像归一化均值 |
image_std | tuple | (0.5, 0.5, 0.5) | 图像归一化标准差 |
compile_model | bool | False | 是否编译模型加速推理 |
postprocess_batch_size | int | 1 | 后处理批大小(积累多少帧后运行后处理) |
TEXT_ID_FOR_TEXT | int | 0 | 文本提示的文本ID |
TEXT_ID_FOR_VISUAL | int | 1 | 视觉提示的文本ID |
TEXT_ID_FOR_GEOMETRIC | int | 2 | 几何提示的文本ID |
从 Sam3MultiplexBase 继承的核心属性:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
tracker | Sam3MultiplexTrackerPredictor | 无 | SAM2 跟踪器预测器 |
detector | Sam3MultiplexDetector | 无 | 多路复用检测器 |
score_threshold_detection | float | 0.5 | 检测输出概率阈值(用于NMS和检测-跟踪匹配) |
image_only_det_thresh | float | 0.5 | 仅图像输入的检测阈值 |
det_nms_thresh | float | 0.0 | 检测NMS的IoU阈值 |
det_nms_use_iom | bool | False | 是否在NMS中使用IoM(交小比)而非IoU |
assoc_iou_thresh | float | 0.5 | 检测-跟踪匹配的IoU阈值(宽松阈值,如0.1) |
trk_assoc_iou_thresh | float | 0.5 | 跟踪关联的IoU阈值(严格阈值,如0.5) |
new_det_thresh | float | 0.5 | 检测作为新对象添加的阈值 |
hotstart_delay | int | 0 | 热启动延迟帧数(0表示禁用) |
hotstart_unmatch_thresh | int | 3 | 热启动期间未匹配帧数阈值(超过则移除对象) |
hotstart_dup_thresh | int | 3 | 热启动期间重叠对象帧数阈值(超过则移除对象) |
suppress_unmatched_only_within_hotstart | bool | True | 是否仅在热启动期间抑制未匹配对象 |
init_trk_keep_alive | int | 0 | 初始跟踪保持活跃帧数 |
max_trk_keep_alive | int | 8 | 最大跟踪保持活跃帧数 |
min_trk_keep_alive | int | -4 | 最小跟踪保持活跃帧数 |
suppress_overlapping_based_on_recent_occlusion_threshold | float | 0.0 | 基于最近遮挡的重叠对象抑制阈值 |
allow_unoccluded_to_suppress | bool | False | 是否允许未遮挡对象抑制遮挡对象 |
decrease_trk_keep_alive_for_empty_masklets | bool | False | 是否为空掩码减少跟踪保持活跃计数 |
o2o_matching_masklets_enable | bool | False | 是否启用匈牙利匹配以匹配现有掩码 |
suppress_det_close_to_boundary | bool | False | 是否抑制边界附近的检测 |
fill_hole_area | int | 16 | 填充空洞的面积阈值 |
sprinkle_removal_area | int | 16 | 洒点移除的面积阈值 |
max_num_objects | int | 128 | 跨所有GPU跟踪的最大对象数(-1表示无限制) |
max_num_kboxes | int | 20 | 最大关键框数量 |
recondition_every_nth_frame | int | -1 | 每N帧重新条件化(-1表示禁用) |
use_iom_recondition | bool | False | 是否在重新条件化中使用IoM |
iom_thresh_recondition | float | 0.8 | 重新条件化的IoM阈值 |
iou_thresh_recondition | float | 0.8 | 重新条件化的IoU阈值 |
is_multiplex | bool | False | 是否为多路复用模式 |
running_in_prod | bool | False | 是否在生产环境(FBInfra)中运行 |
masklet_confirmation_enable | bool | False | 是否启用掩码确认 |
masklet_confirmation_consecutive_det_thresh | int | 3 | 掩码确认所需的连续检测帧数 |
reconstruction_bbox_iou_thresh | float | 0.0 | 重建边界框的IoU阈值 |
reconstruction_bbox_det_score | float | 0.5 | 重建边界框的检测分数 |
reapply_no_object_pointer | bool | False | 是否为抑制对象重新应用无对象指针 |
use_batched_grounding | bool | False | 是否使用批处理接地 |
batched_grounding_batch_size | int | 1 | 批处理接地的批大小 |
bucket_capacity | int | 从 tracker.multiplex_controller 获取 | 多路复用桶容量(仅当 is_multiplex=True 时有效) |
rank | int | 从环境变量 RANK 读取 | 当前进程排名 |
world_size | int | 从环境变量 WORLD_SIZE 读取 | 进程总数 |
_dist_pg_cpu | torch.distributed.ProcessGroup 或 None | None | CPU进程组(惰性初始化) |
_profiler | torch.profiler.profile 或 None | None | PyTorch性能分析器 |
_profiling_enabled | bool | 从环境变量 ENABLE_PROFILING 读取 | 是否启用性能分析 |
初始化参数表格 (传递给 Sam3MultiplexTracking.__init__ 的参数):
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
image_size | int | 1008 | 输入图像尺寸 |
image_mean | tuple | (0.5, 0.5, 0.5) | 图像归一化均值 |
image_std | tuple | (0.5, 0.5, 0.5) | 图像归一化标准差 |
compile_model | bool | False | 是否编译模型加速推理 |
postprocess_batch_size | int | 1 | 后处理批大小 |
**kwargs | dict | {} | 传递给父类 Sam3MultiplexBase 的其余参数 |
注: **kwargs 包含所有 Sam3MultiplexBase 的初始化参数(见上表)。
方法表格 (Sam3MultiplexTracking 核心方法):
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | image_size=1008, image_mean=(0.5,0.5,0.5), image_std=(0.5,0.5,0.5), compile_model=False, postprocess_batch_size=1, **kwargs | 无 | 初始化多路复用跟踪器,设置图像处理参数和编译选项 |
_construct_initial_input_batch | inference_state: dict, images: List[torch.Tensor] | 无(修改 inference_state) | 构建初始的 BatchedDatapoint 输入批次,包含图像批次、查找文本批次和查找输入 |
_get_visual_prompt | inference_state: dict, frame_idx: int, boxes_cxcywh: Tensor, box_labels: Tensor | 元组: (boxes_cxcywh, box_labels, geometric_prompt) | 根据边界框和标签创建视觉提示的几何提示对象 |
init_state | resource_path: str, offload_video_to_cpu=False, async_loading_frames=False, use_torchcodec=False, use_cv2=False, input_is_mp4=False | inference_state: dict | 初始化推理状态,加载视频帧,构建输入批次,设置初始状态 |
reset_state | inference_state: dict | 无(修改 inference_state) | 重置推理状态到初始状态,清除所有提示和跟踪结果 |
_get_processing_order | inference_state: dict, start_frame_idx: int 或 None, max_frame_num_to_track: int 或 None, reverse: bool | 元组: (processing_order: range, end_frame_idx: int) | 根据起始帧、最大跟踪帧数和方向确定处理顺序 |
propagate_in_video | inference_state: dict, start_frame_idx=None, max_frame_num_to_track=None, reverse=False, output_prob_thresh=0.5, compute_stability_score=False, is_instance_processing=False, **kwargs | 生成器,yield (frame_idx: int, output: dict) | 将提示传播到视频的所有帧,支持热启动延迟和批处理后处理 |
_run_single_frame_inference | inference_state: dict, frame_idx: int, reverse: bool, is_instance_processing=False | out: dict | 执行单帧推理,更新推理状态,返回对象ID到掩码/分数的映射 |
_postprocess_output | inference_state: dict, out: dict, removed_obj_ids=None, suppressed_obj_ids=None, unconfirmed_obj_ids=None | postprocessed_out: dict | 后处理输出:过滤被移除/抑制/未确认的对象,生成最终掩码、分数和边界框 |
_cache_frame_outputs | inference_state: dict, frame_idx: int, obj_id_to_mask: dict | 无(修改 inference_state["cached_frame_outputs"]) | 缓存帧输出到推理状态中,供后续获取 |
_compile_model | 无 | 无 | 编译模型组件以加速推理(如果 compile_model=True) |
remove_object | inference_state: dict, obj_id: int, is_user_action=True | 无(修改 inference_state) | 从跟踪中移除指定对象,清理相关状态 |
add_prompt | inference_state: dict, frame_idx: int, text=None, points=None, point_labels=None, clear_old_points=True, bounding_boxes=None, bounding_box_labels=None, clear_old_boxes=True, output_prob_thresh=0.5, obj_id=None | 元组: (frame_idx: int, output: dict) | 在指定帧添加文本、点或框提示,运行单帧推理,返回临时输出 |
从 Sam3MultiplexBase 继承的重要方法:
_det_track_one_frame(...): 执行单帧检测与跟踪(SPMD方式)_det_track_one_frame_impl(...):_det_track_one_frame的具体实现all_gather_cpu(...),all_gather_python_obj_cpu(...),broadcast_cpu(...): 分布式CPU通信_start_profiling(...),_stop_profiling(...): 性能分析控制
2.2.2 Sam3MultiplexTrackingProd 生产版本类
继承关系: Sam3MultiplexTrackingProd → Sam3MultiplexTracking
类作用: 支持批处理视频处理的生产版本,可处理大型视频的小批次块以管理内存或跨多个调用分布处理。通过持久化生成器状态(热启动缓冲区、移除对象ID等)在推理状态中跨生成器实例化,支持批处理处理。
特有属性:
generator_state(在inference_state中): 包含hotstart_buffer,hotstart_removed_obj_ids,unconfirmed_obj_ids_per_frame,postprocess_yield_list,用于跨批处理持久化状态。
特有方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
init_state | resource_path: str, offload_video_to_cpu=False, async_loading_frames=False, use_torchcodec=False, use_cv2=False, input_is_mp4=False | inference_state: dict | 重写父类方法,初始化生成器状态 |
reset_state | inference_state: dict | 无 | 重写父类方法,重置生成器状态 |
propagate_in_video | inference_state: dict, start_frame_idx=None, max_frame_num_to_track=None, reverse=False, output_prob_thresh=0.5, compute_stability_score=False, is_instance_processing=False, is_last_batch=True | 生成器,yield (frame_idx: int, output: dict) | 重写父类方法,支持批处理处理,is_last_batch 参数控制缓冲区刷新 |
2.2.3 Sam3MultiplexTrackingWithInteractivity 交互增强版本类
继承关系: Sam3MultiplexTrackingWithInteractivity → Sam3MultiplexTracking
类作用: 支持用户交互操作的增强版本,维护用户操作历史记录,支持部分传播(仅传播用户编辑的对象)与完整传播的智能切换,提供更细粒度的交互控制。
特有属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
use_prev_mem_frame | bool | False | 是否为添加点操作使用先前记忆帧 |
use_stateless_refinement | bool | False | 是否启用无状态细化行为 |
refinement_detector_cond_frame_removal_window | int | 120 (30*4) | 用户细化帧附近移除检测器条件帧的窗口大小 |
特有方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | use_prev_mem_frame=False, use_stateless_refinement=False, refinement_detector_cond_frame_removal_window=120, **kwargs | 无 | 初始化交互增强跟踪器 |
init_state | resource_path: str, offload_video_to_cpu=False, async_loading_frames=False, use_torchcodec=False, use_cv2=False, input_is_mp4=False | inference_state: dict | 重写父类方法,初始化动作历史记录和SAM2推理状态 |
reset_state | inference_state: dict | 无 | 重写父类方法,重置动作历史记录 |
_init_new_sam2_state | inference_state: dict | new_sam2_state: dict | 初始化新的SAM2推理状态 |
cancel_propagation | inference_state: dict | 无 | 取消正在进行的传播,重置模型状态 |
fetch_and_process_single_frame_results | inference_state: dict, frame_idx: int | 元组: (frame_idx: int, postprocessed_out: dict) | 获取并处理单帧的缓存结果 |
propagate_in_video | inference_state: dict, start_frame_idx=None, max_frame_num_to_track=None, reverse=False, output_prob_thresh=0.5, compute_stability_score=False, is_instance_processing=False, is_last_batch=False | 生成器,yield (frame_idx: int, output: dict) | 重写父类方法,根据动作历史智能选择传播类型(完整/部分/获取) |
parse_action_history_for_propagation | inference_state: dict | 元组: (propagation_type: str, obj_ids: List[int]) | 解析动作历史记录以确定传播类型和相关对象ID |
add_action_history | inference_state: dict, action_type: str, obj_ids: List[int] 或 None, frame_idx: int 或 None | 无 | 添加用户动作到历史记录 |
remove_object | inference_state: dict, obj_id: int, is_user_action=True | 无 | 重写父类方法,记录移除动作到历史记录 |
add_prompt | inference_state: dict, frame_idx: int, text=None, points=None, point_labels=None, clear_old_points=True, bounding_boxes=None, bounding_box_labels=None, clear_old_boxes=True, output_prob_thresh=0.5, obj_id=None | 元组: (frame_idx: int, output: dict) | 重写父类方法,记录提示添加动作到历史记录 |
2.3 Sam3VideoBase (sam3_video_base.py)
类作用: SAM 3 视频跟踪的基础类,继承自 torch.nn.Module,整合检测器(detector)和跟踪器(tracker)两大核心组件,实现检测-跟踪匹配、热启动延迟(hotstart)、掩码确认(masklet confirmation)、非极大值抑制(NMS)、分布式推理等核心跟踪逻辑。作为预测器(Predictor)和跟踪器(Tracker)之间的中间抽象层,隔离业务逻辑与模型拓扑,提供统一的单帧推理流程 _det_track_one_frame。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
detector | nn.Module | 无 | 检测器模型,负责图像特征提取与目标检测 |
tracker | nn.Module | 无 | 跟踪器模型,负责时序记忆与掩码预测 |
score_threshold_detection | float | 0.5 | 检测输出概率阈值(进入NMS与检测-跟踪匹配) |
det_nms_thresh | float | 0.0 | 检测NMS的IoU阈值 |
assoc_iou_thresh | float | 0.5 | 检测-跟踪匹配的IoU阈值(宽松阈值,如0.1) |
trk_assoc_iou_thresh | float | 0.5 | 跟踪关联的IoU阈值(严格阈值,如0.5) |
new_det_thresh | float | 0.0 | 检测作为新对象添加的阈值 |
hotstart_delay | int | 0 | 热启动延迟帧数(0表示禁用) |
hotstart_unmatch_thresh | int | 3 | 热启动期间未匹配帧数阈值(超过则移除对象) |
hotstart_dup_thresh | int | 3 | 热启动期间重叠对象帧数阈值(超过则移除对象) |
suppress_unmatched_only_within_hotstart | bool | True | 是否仅在热启动期间抑制未匹配对象 |
init_trk_keep_alive | int | 0 | 初始跟踪保持活跃帧数 |
max_trk_keep_alive | int | 8 | 最大跟踪保持活跃帧数 |
min_trk_keep_alive | int | -4 | 最小跟踪保持活跃帧数 |
suppress_overlapping_based_on_recent_occlusion_threshold | float | 0.0 | 基于最近遮挡的重叠对象抑制阈值 |
suppress_det_close_to_boundary | bool | False | 是否抑制边界附近的检测 |
decrease_trk_keep_alive_for_empty_masklets | bool | False | 是否为空掩码减少跟踪保持活跃计数 |
o2o_matching_masklets_enable | bool | False | 是否启用匈牙利匹配以匹配现有掩码 |
fill_hole_area | int | 16 | 填充空洞的面积阈值 |
max_num_objects | int | -1 | 跨所有GPU跟踪的最大对象数(-1表示无限制) |
num_obj_for_compile | int | 自动计算 | 为torch.compile缓存创建的对象数 |
recondition_every_nth_frame | int | -1 | 每N帧重新条件化(-1表示禁用) |
masklet_confirmation_enable | bool | False | 是否启用掩码确认 |
masklet_confirmation_consecutive_det_thresh | int | 3 | 掩码确认所需的连续检测帧数 |
reconstruction_bbox_iou_thresh | float | 0.0 | 重建边界框的IoU阈值 |
reconstruction_bbox_det_score | float | 0.0 | 重建边界框的检测分数 |
rank | int | 从环境变量 RANK 读取 | 当前进程排名 |
world_size | int | 从环境变量 WORLD_SIZE 读取 | 进程总数 |
_dist_pg_cpu | torch.distributed.ProcessGroup 或 None | None | CPU进程组(惰性初始化) |
device (property) | torch.device | 自动计算 | 模型参数所在的设备 |
初始化参数表格 (传递给 Sam3VideoBase.__init__ 的配置):
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
detector | nn.Module | 无 | 检测器模型 |
tracker | nn.Module | 无 | 跟踪器模型 |
score_threshold_detection | float | 0.5 | 检测输出概率阈值 |
det_nms_thresh | float | 0.0 | 检测NMS的IoU阈值 |
assoc_iou_thresh | float | 0.5 | 检测-跟踪匹配的IoU阈值(宽松) |
trk_assoc_iou_thresh | float | 0.5 | 跟踪关联的IoU阈值(严格) |
new_det_thresh | float | 0.0 | 检测作为新对象添加的阈值 |
hotstart_delay | int | 0 | 热启动延迟帧数 |
hotstart_unmatch_thresh | int | 3 | 热启动期间未匹配帧数阈值 |
hotstart_dup_thresh | int | 3 | 热启动期间重叠对象帧数阈值 |
suppress_unmatched_only_within_hotstart | bool | True | 是否仅在热启动期间抑制未匹配对象 |
init_trk_keep_alive | int | 0 | 初始跟踪保持活跃帧数 |
max_trk_keep_alive | int | 8 | 最大跟踪保持活跃帧数 |
min_trk_keep_alive | int | -4 | 最小跟踪保持活跃帧数 |
suppress_overlapping_based_on_recent_occlusion_threshold | float | 0.0 | 基于最近遮挡的重叠对象抑制阈值 |
decrease_trk_keep_alive_for_empty_masklets | bool | False | 是否为空掩码减少跟踪保持活跃计数 |
o2o_matching_masklets_enable | bool | False | 是否启用匈牙利匹配以匹配现有掩码 |
suppress_det_close_to_boundary | bool | False | 是否抑制边界附近的检测 |
fill_hole_area | int | 16 | 填充空洞的面积阈值 |
max_num_objects | int | -1 | 跨所有GPU跟踪的最大对象数(-1表示无限制) |
recondition_every_nth_frame | int | -1 | 每N帧重新条件化(-1表示禁用) |
masklet_confirmation_enable | bool | False | 是否启用掩码确认 |
masklet_confirmation_consecutive_det_thresh | int | 3 | 掩码确认所需的连续检测帧数 |
reconstruction_bbox_iou_thresh | float | 0.0 | 重建边界框的IoU阈值 |
reconstruction_bbox_det_score | float | 0.0 | 重建边界框的检测分数 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 见上表 | 无 | 初始化视频跟踪基类 |
_det_track_one_frame | frame_idx: int, num_frames: int, reverse: bool, input_batch: BatchedDatapoint, geometric_prompt: Any, tracker_states_local: List[Any], tracker_metadata_prev: Dict[str, Any], feature_cache: Dict, orig_vid_height: int, orig_vid_width: int, is_image_only: bool = False, allow_new_detections: bool = True | 元组: (obj_id_to_mask: dict, obj_id_to_score: dict, tracker_states_local_new: List, tracker_metadata_new: dict, frame_stats: dict, tracker_obj_scores_global: list) | 核心方法: 执行单帧检测-跟踪推理(SPMD方式),包含5个步骤:1) 骨干网络与检测;2) 跟踪器传播;3) 更新规划;4) 更新执行;5) 输出构建 |
run_backbone_and_detection | frame_idx: int, num_frames: int, input_batch: BatchedDatapoint, geometric_prompt: Any, feature_cache: Dict, reverse: bool, allow_new_detections: bool | det_out: dict (bbox, mask, scores) | 运行骨干网络和检测器,提取检测结果并缓存骨干特征 |
run_tracker_propagation | frame_idx: int, num_frames: int, reverse: bool, tracker_states_local: List[Any], tracker_metadata_prev: Dict[str, Any] | 元组: (tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor) | 传播本地跟踪器状态,收集全局掩码预测 |
run_tracker_update_planning_phase | frame_idx: int, num_frames: int, reverse: bool, det_out: dict, tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any], tracker_states_local: List[Any], is_image_only: bool = False | 元组: (tracker_update_plan: dict, tracker_metadata_new: dict) | 规划跟踪器更新:决定哪些对象添加/移除/重新条件化,生成更新计划 |
run_tracker_update_execution_phase | frame_idx: int, num_frames: int, reverse: bool, det_out: dict, tracker_states_local: List[Any], tracker_update_plan: dict, orig_vid_height: int, orig_vid_width: int, feature_cache: Dict | tracker_states_local_new: List[Any] | 执行跟踪器更新:根据计划更新本地跟踪器状态,编码新记忆 |
_suppress_detections_close_to_boundary | boxes: Tensor (N,4 xyxy 归一化), margin: float = 0.025 | keep: Tensor (bool) | 抑制图像边界附近的检测框 |
_recondition_masklets | frame_idx: int, tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any], det_out: dict, tracker_states_local: List[Any] | reconditioned_obj_ids: set | 重新条件化掩码(当对象被遮挡后重新出现时恢复) |
_suppress_overlapping_based_on_recent_occlusion | tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any], det_out: dict | suppressed_obj_ids: set | 基于最近遮挡历史抑制重叠对象 |
_create_planning_metadata | tracker_metadata_prev: dict | planning_metadata: dict | 创建用于规划阶段的元数据 |
_post_execution_phase_hook | tracker_states_local: List[Any], tracker_metadata_new: dict | 无 | 执行阶段后的钩子函数,可被子类覆盖 |
build_outputs | frame_idx: int, num_frames: int, reverse: bool, det_out: dict, tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any], tracker_update_plan: dict, orig_vid_height: int, orig_vid_width: int, reconditioned_obj_ids: set, det_to_matched_trk_obj_ids: dict | obj_id_to_mask: dict | 构建最终输出字典(对象ID到掩码的映射) |
_propogate_tracker_one_frame_local_gpu | tracker_states_local: List[Any], frame_idx: int, reverse: bool | 元组: (obj_ids_local: List[int], low_res_masks_local: Tensor, obj_scores_local: Tensor) | 在本地GPU上传播跟踪器状态,获取当前帧的掩码预测 |
_associate_det_trk | det_bboxes: Tensor, det_masks: Tensor, det_scores: Tensor, trk_masks: Tensor, trk_scores: Tensor, trk_metadata: dict, frame_idx: int, reverse: bool | 元组: (det_to_matched_trk_idx: dict, trk_to_matched_det_idx: dict, det_scores_for_matched: Tensor, det_masks_for_matched: Tensor, det_bboxes_for_matched: Tensor) | 关联检测与跟踪:计算IoU匹配,返回匹配映射 |
_assign_new_det_to_gpus | new_det_num: int, prev_workload_per_gpu: List[int] | gpu_ids: List[int] | 分配新检测对象到各GPU,实现负载均衡 |
_process_hotstart | frame_idx: int, det_out: dict, tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any] | 元组: (removed_obj_ids: set, suppressed_obj_ids: set) | 处理热启动逻辑:移除未匹配或重叠的对象 |
_tracker_update_memories | tracker_states_local: List[Any], obj_ids: List[int], frame_idx: int, feature_cache: Dict, orig_vid_height: int, orig_vid_width: int | 无 | 更新跟踪器记忆:为指定对象编码新记忆 |
_tracker_add_new_objects | tracker_states_local: List[Any], new_det_inds: List[int], det_out: dict, frame_idx: int, feature_cache: Dict, orig_vid_height: int, orig_vid_width: int | new_obj_ids: List[int] | 添加新对象到跟踪器状态 |
_tracker_remove_object | tracker_states_local: List[Any], obj_id: int | 无 | 从跟踪器状态中移除单个对象 |
_tracker_remove_objects | tracker_states_local: List[Any], obj_ids: List[int] | 无 | 批量移除对象 |
_initialize_metadata | 无 | metadata: dict | 初始化跟踪器元数据(全局对象ID映射等) |
update_masklet_confirmation_status | frame_idx: int, det_out: dict, tracker_metadata_prev: Dict[str, Any], tracker_update_plan: dict | 元组: (unconfirmed_obj_ids: set, confirmed_obj_ids: set) | 更新掩码确认状态:基于连续检测匹配确认对象 |
forward | input: BatchedDatapoint, is_inference: bool = False | 抛出 NotImplementedError | 抽象前向方法,需在子类中实现 |
_load_checkpoint | ckpt_path: str, strict: bool = True | 无 | 加载检查点 |
prep_for_evaluator | video_frames: List[Image], tracking_res: dict, scores_labels: dict | 无 | 为评估器准备数据格式 |
_encode_prompt | **kwargs | 无 | 编码提示(占位符,需子类实现) |
_drop_new_det_with_obj_limit | new_det_fa_inds: np.ndarray, det_scores_np: np.ndarray, num_to_keep: int | new_det_fa_inds: np.ndarray | 根据对象限制丢弃新检测 |
_init_dist_pg_cpu | 无 | 无 | 初始化CPU进程组 |
broadcast_python_obj_cpu | python_obj_list: list, src: int | 无 | 广播Python对象到所有CPU进程 |
_get_objects_to_suppress_based_on_most_recently_occluded | tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any], det_out: dict | suppressed_obj_ids: set | 基于最近被遮挡的对象确定需要抑制的对象 |
静态方法:
_convert_to_numpy(self): 将张量转换为NumPy数组。_create_cpu_metadata(self, trk_obj_ids, det_masks): 创建CPU元数据。
2.4 Sam3MultiplexBase (sam3_multiplex_base.py)
类作用: SAM 3.1 多路复用(Multiplex)跟踪的中间抽象层,继承自 Sam3VideoBase,为多路复用跟踪添加特定配置和功能。引入多路复用控制器(bucket capacity)、批处理接地(batched grounding)、生产环境标志(running_in_prod)、性能分析等特性,是多路复用跟踪族系(Sam3MultiplexTracking等)的直接父类。
继承关系: Sam3MultiplexBase → Sam3VideoBase
属性表格 (特有属性,不包括继承的属性):
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
tracker | Sam3MultiplexTrackerPredictor | 无 | 多路复用跟踪器预测器(类型特定) |
detector | Sam3MultiplexDetector | 无 | 多路复用检测器(类型特定) |
image_only_det_thresh | float | 0.5 | 仅图像输入的检测阈值 |
det_nms_use_iom | bool | False | 是否在NMS中使用IoM(交小比)而非IoU |
is_multiplex | bool | False | 是否为多路复用模式 |
running_in_prod | bool | False | 是否在生产环境(FBInfra)中运行 |
allow_unoccluded_to_suppress | bool | False | 是否允许未遮挡对象抑制遮挡对象 |
sprinkle_removal_area | int | 16 | 洒点移除的面积阈值 |
max_num_objects | int | 128 | 跨所有GPU跟踪的最大对象数(默认128) |
max_num_kboxes | int | 20 | 最大关键框数量 |
use_iom_recondition | bool | False | 是否在重新条件化中使用IoM |
iom_thresh_recondition | float | 0.8 | 重新条件化的IoM阈值 |
iou_thresh_recondition | float | 0.8 | 重新条件化的IoU阈值 |
reapply_no_object_pointer | bool | False | 是否为抑制对象重新应用无对象指针 |
use_batched_grounding | bool | False | 是否使用批处理接地 |
batched_grounding_batch_size | int | 1 | 批处理接地的批大小 |
bucket_capacity | int | 从 tracker.multiplex_controller 获取 | 多路复用桶容量(仅当 is_multiplex=True 时有效) |
_profiler | torch.profiler.profile 或 None | None | PyTorch性能分析器 |
_frame_count | int | 0 | 帧计数(用于性能分析) |
_profile_save_dir | str | /tmp/profiling | 性能分析结果保存目录 |
_profiling_enabled | bool | 从环境变量 ENABLE_PROFILING 读取 | 是否启用性能分析 |
初始化参数表格 (传递给 Sam3MultiplexBase.__init__ 的特有参数):
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
tracker | Sam3MultiplexTrackerPredictor | 无 | 多路复用跟踪器预测器 |
detector | Sam3MultiplexDetector | 无 | 多路复用检测器 |
ckpt_path | str 或 None | None | 检查点路径(传统加载方式) |
sam3_ckpt_path | str 或 None | None | SAM3检查点路径(新加载方式) |
image_only_det_thresh | float | 0.5 | 仅图像输入的检测阈值 |
det_nms_use_iom | bool | False | 是否在NMS中使用IoM |
allow_unoccluded_to_suppress | bool | False | 是否允许未遮挡对象抑制遮挡对象 |
sprinkle_removal_area | int | 16 | 洒点移除的面积阈值 |
max_num_objects | int | 128 | 跨所有GPU跟踪的最大对象数 |
max_num_kboxes | int | 20 | 最大关键框数量 |
use_iom_recondition | bool | False | 是否在重新条件化中使用IoM |
iom_thresh_recondition | float | 0.8 | 重新条件化的IoM阈值 |
iou_thresh_recondition | float | 0.8 | 重新条件化的IoU阈值 |
is_multiplex | bool | False | 是否为多路复用模式 |
running_in_prod | bool | False | 是否在生产环境中运行 |
reapply_no_object_pointer | bool | False | 是否为抑制对象重新应用无对象指针 |
use_batched_grounding | bool | False | 是否使用批处理接地 |
batched_grounding_batch_size | int | 1 | 批处理接地的批大小 |
**kwargs | dict | {} | 传递给父类 Sam3VideoBase 的其余参数 |
注: 此外还继承所有 Sam3VideoBase 的初始化参数(如 score_threshold_detection、hotstart_delay 等)。
方法表格 (特有方法,不包括继承的方法):
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 见上表 | 无 | 初始化多路复用基类,设置多路复用特定配置 |
all_gather_cpu | tensor_list: List[Tensor], tensor: Tensor | 无 | 在CPU进程组上执行all-gather操作 |
all_gather_python_obj_cpu | object_list: List[Any], python_obj: Any | 无 | 在CPU进程组上收集Python对象 |
broadcast_cpu | x: Tensor, src: int | 无 | 在CPU进程组上广播张量 |
_start_profiling | frame_idx: int | bool: 是否已启动性能分析 | 启动PyTorch性能分析器(如果启用) |
_stop_profiling | 无 | 无 | 停止性能分析器并保存跟踪文件 |
_det_track_one_frame_impl | frame_idx: int, num_frames: int, reverse: bool, input_batch: BatchedDatapoint, geometric_prompt: Any, tracker_states_local: List[Any], tracker_metadata_prev: Dict[str, Any], feature_cache: Dict, orig_vid_height: int, orig_vid_width: int, is_image_only: bool = False | 元组: (obj_id_to_mask: dict, obj_id_to_score: dict, tracker_states_local_new: List, tracker_metadata_new: dict, frame_stats: dict, tracker_obj_scores_global: list) | _det_track_one_frame 的具体实现,包含性能分析包装 |
_deepcopy | x: Any | 深拷贝的对象 | 深度复制对象(用于跟踪器状态复制) |
_count_buckets_in_states | tracker_states_local: List[Any] | int: 桶数量 | 计算本地跟踪器状态中的桶数量(用于多路复用容量检查) |
_process_hotstart_gpu | frame_idx: int, det_out: dict, tracker_low_res_masks_global: Tensor, tracker_obj_scores_global: Tensor, tracker_metadata_prev: Dict[str, Any] | 元组: (removed_obj_ids: set, suppressed_obj_ids: set) | GPU版本的热启动处理 |
注: 此类继承所有 Sam3VideoBase 的方法(如 run_backbone_and_detection、run_tracker_propagation 等)。
3. 多模态、视觉/语言大一统主干 (Backbones & V-L Models)
3.1 Sam3Image & Sam3ImageOnVideoMultiGPU (sam3_image.py / multiplex_detector)
类作用: SAM 3 多模态图像检测与分割模型,支持文本提示(“Find Object”)的视觉-语言联合推理。作为检测器核心,处理图像特征提取、几何提示编码、Transformer编码器-解码器推理和分割头预测,为视频跟踪提供单帧检测能力。
继承关系:
Sam3Image→torch.nn.ModuleSam3ImageOnVideoMultiGPU→Sam3Image
3.1.1 Sam3Image 基类
类常量:
| 常量名 | 值 | 作用描述 |
|---|---|---|
TEXT_ID_FOR_TEXT | 0 | 文本提示的ID,用于文本特征编码 |
TEXT_ID_FOR_VISUAL | 1 | 视觉提示的ID,用于视觉特征编码 |
TEXT_ID_FOR_GEOMETRIC | 2 | 几何提示的ID,用于几何特征编码 |
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
backbone | SAM3VLBackbone | 无 | 视觉-语言骨干网络,提取图像和文本特征 |
geometry_encoder | nn.Module | 无 | 输入几何编码器,编码框、点等几何提示 |
transformer | nn.Module | 无 | Transformer模型,执行编码器-解码器推理 |
hidden_dim | int | transformer.d_model | Transformer隐藏维度 |
num_feature_levels | int | 1 | 特征层级数 |
segmentation_head | nn.Module 或 None | None | 分割头模型,预测最终掩码 |
o2m_mask_predict | bool | True | 是否预测O2M(一对多)掩码 |
dot_prod_scoring | nn.Module 或 None | None | 点积评分头,用于对象检测评分 |
use_act_checkpoint_seg_head | bool | True | 分割头是否使用激活检查点以节省显存 |
interactivity_in_encoder | bool | True | 编码器中是否启用交互性 |
matcher | nn.Module 或 None | None | 匹配器,用于训练时匹配预测与目标 |
num_interactive_steps_val | int | 0 | 验证时的交互步数 |
use_dot_prod_scoring | bool | True | 是否使用点积评分(否则使用线性分类器) |
instance_dot_prod_scoring | nn.Module 或 None | None | 实例点积评分头(当separate_scorer_for_instance=True时) |
class_embed | nn.Linear 或 None | None | 线性分类嵌入层(当use_dot_prod_scoring=False时) |
instance_class_embed | nn.Linear 或 None | None | 实例分类嵌入层(当separate_scorer_for_instance=True时) |
supervise_joint_box_scores | bool | False | 是否监督联合框分数(仅当使用存在性token/分数时相关) |
detach_presence_in_joint_score | bool | False | 联合评分中是否分离存在性(仅当使用存在性token/分数时相关) |
use_instance_query | bool | True | 是否使用实例查询 |
multimask_output | bool | True | 是否输出多掩码(多掩码输出模式) |
inst_interactive_predictor | SAM3InteractiveImagePredictor 或 None | None | 实例交互预测器,用于实例级交互推理 |
dac | bool | transformer.decoder.dac | 是否启用DAC(检测器-跟踪器协作) |
device (property) | torch.device | 自动计算 | 模型参数所在的设备 |
初始化参数表格 (传递给 Sam3Image.__init__ 的参数):
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
backbone | SAM3VLBackbone | 无 | 视觉-语言骨干网络,必须提供 |
transformer | nn.Module | 无 | Transformer模型,必须提供 |
input_geometry_encoder | nn.Module | 无 | 输入几何编码器,必须提供 |
segmentation_head | nn.Module | None | 分割头模型 |
num_feature_levels | int | 1 | 特征层级数 |
o2m_mask_predict | bool | True | 是否预测O2M(一对多)掩码 |
dot_prod_scoring | nn.Module | None | 点积评分头 |
use_instance_query | bool | True | 是否使用实例查询 |
multimask_output | bool | True | 是否输出多掩码 |
use_act_checkpoint_seg_head | bool | True | 分割头是否使用激活检查点 |
interactivity_in_encoder | bool | True | 编码器中是否启用交互性 |
matcher | nn.Module | None | 匹配器 |
use_dot_prod_scoring | bool | True | 是否使用点积评分 |
supervise_joint_box_scores | bool | False | 是否监督联合框分数 |
detach_presence_in_joint_score | bool | False | 联合评分中是否分离存在性 |
separate_scorer_for_instance | bool | False | 是否为实例使用单独的评分器 |
num_interactive_steps_val | int | 0 | 验证时的交互步数 |
inst_interactive_predictor | SAM3InteractiveImagePredictor | None | 实例交互预测器 |
**kwargs | dict | {} | 其他参数 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 见上表初始化参数 | 无 | 初始化SAM3图像检测器 |
_get_img_feats | backbone_out: dict, img_ids: Tensor | 元组: (backbone_out, img_feats, img_pos_embeds, vis_feat_sizes) | 从骨干网络输出中提取图像特征,返回特征列表和位置嵌入 |
_encode_prompt | backbone_out: dict, find_input: FindStage, geometric_prompt: Prompt, visual_prompt_embed=None, visual_prompt_mask=None, encode_text=True, prev_mask_pred=None | 元组: (prompt: Tensor, prompt_mask: Tensor, backbone_out: dict) | 编码几何提示(框、点)和文本提示,生成统一的提示张量和掩码 |
_run_encoder | backbone_out: dict, find_input: FindStage, prompt: Tensor, prompt_mask: Tensor, encoder_extra_kwargs=None | 元组: (backbone_out: dict, encoder_out: dict, feat_tuple: tuple) | 运行Transformer编码器,编码图像特征和提示,返回编码器输出 |
_run_decoder | pos_embed: Tensor, memory: Tensor, src_mask: Tensor, out: dict, prompt: Tensor, prompt_mask: Tensor, encoder_out: dict | 元组: (out: dict, hs: Tensor) | 运行Transformer解码器,生成对象查询、边界框和分数预测 |
_update_scores_and_boxes | out: dict, hs: Tensor, reference_boxes: Tensor, prompt: Tensor, prompt_mask: Tensor, dec_presence_out=None, is_instance_prompt=False | 无(修改out字典) | 更新分数和边界框预测:计算分类分数和边界框坐标 |
_run_segmentation_heads | out: dict, backbone_out: dict, img_ids: Tensor, vis_feat_sizes: list, encoder_hidden_states: Tensor, prompt: Tensor, prompt_mask: Tensor, hs: Tensor | 无(修改out字典) | 运行分割头,预测最终掩码,添加到输出字典 |
_get_best_mask | out: dict | prev_mask_pred: Tensor | 从输出中选择最佳掩码,下采样以匹配图像分辨率 |
forward_grounding | backbone_out: dict, find_input: FindStage, find_target: Any, geometric_prompt: Prompt, **kwargs | out: dict | 完整接地推理流程:编码提示 → 编码器 → 解码器 → 分割头 |
_postprocess_out | out: dict, multimask_output: bool = False | out: dict | 后处理输出:多掩码输出模式下选择最佳掩码 |
_get_geo_prompt_from_find_input | find_input: FindStage | geometric_prompt: Prompt | 从查找输入构建初始几何提示 |
_get_dummy_prompt | num_prompts=1 | geometric_prompt: Prompt | 创建虚拟几何提示(用于无提示推理) |
forward | input: BatchedDatapoint | previous_stages_out: SAM3Output | 主前向方法:处理批处理数据点,支持多步交互推理 |
_compute_matching | out: dict, targets: dict | 无(修改out字典) | 计算预测与目标之间的匹配索引 |
back_convert | targets: Any | batched_targets: dict | 将目标转换为批处理格式 |
predict_inst | inference_state: dict, **kwargs | 元组: (masks: np.ndarray, scores: np.ndarray, logits: np.ndarray) | 实例级预测:使用实例交互预测器进行单实例推理 |
predict_inst_batch | inference_state: dict, *args, **kwargs | 元组: (masks_list: List[np.ndarray], scores_list: List[np.ndarray], logits_list: List[np.ndarray]) | 批处理实例级预测:批量处理多个实例 |
device (property) | 无 | torch.device | 返回模型参数所在的设备 |
3.1.2 Sam3ImageOnVideoMultiGPU 多GPU视频处理扩展类
类作用: 支持多GPU视频处理的SAM3图像检测器扩展,通过分布式计算和缓存机制加速视频帧处理,实现高效的批处理推理。为Sam3VideoBase提供多GPU检测支持。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
rank | int | 从环境变量 RANK 读取 | 当前进程排名 |
world_size | int | 从环境变量 WORLD_SIZE 读取 | 进程总数 |
async_all_gather | bool | True | 是否异步聚集张量 |
gather_backbone_out | bool | 自动判断 | 是否聚集骨干网络输出(默认仅对SAM3VLBackbone聚集) |
| 所有父类属性 | - | - | 继承自Sam3Image的所有属性 |
初始化参数表格:
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
*args | 任意 | 无 | 传递给父类Sam3Image.__init__的位置参数 |
async_all_gather | bool | True | 是否异步聚集张量 |
gather_backbone_out | bool 或 None | None | 是否聚集骨干网络输出(None时自动判断) |
**kwargs | dict | {} | 传递给父类Sam3Image.__init__的关键字参数 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | *args, async_all_gather=True, gather_backbone_out=None, **kwargs | 无 | 初始化多GPU图像检测器,设置分布式参数 |
forward_video_grounding_multigpu | backbone_out: dict, find_inputs: List[FindStage], geometric_prompt: Prompt, frame_idx: int, num_frames: int, multigpu_buffer: dict, track_in_reverse=False, return_sam2_backbone_feats=False, run_nms=False, nms_prob_thresh=None, nms_iou_thresh=None, **kwargs | 元组: (out: dict, backbone_out: dict) | 核心方法: 在多GPU环境下执行视频接地推理,使用缓存机制加速处理 |
_build_multigpu_buffer_next_chunk | backbone_out: dict, find_inputs: List[FindStage], geometric_prompt: Prompt, frame_idx_begin: int, frame_idx_end: int, num_frames: int, multigpu_buffer: dict, run_nms=False, nms_prob_thresh=None, nms_iou_thresh=None | 无(修改multigpu_buffer字典) | 构建多GPU缓冲区下一块:每个GPU计算一个帧的检测输出并聚集到所有GPU |
_gather_tensor | x: Tensor | 元组: (output_list: List[Tensor], handle 或 None) | 聚集张量到所有GPU:执行NCCL all_gather操作,支持异步模式 |
注意:Sam3ImageOnVideoMultiGPU 继承了 Sam3Image 的所有方法,因此也拥有所有基类方法(forward_grounding、_encode_prompt、_run_encoder 等)。
3.2 SAM3VLBackbone (vl_combiner.py / vitdet.py / necks.py)
类作用: Visual-Language Backbone(视觉-语言骨干网络)。将视觉骨干网络(Vision Transformer,来自Hiera或VitDet,负责密集像素特征提取)与语言编码器(Text Encoder,负责理解文本提示如”红色的车”)组合在一起,但不进行特征融合。主要作为方便包装器,统一处理两个骨干网络的激活检查点和编译优化。
文件位置:
- 主类:
model/vl_combiner.py - 视觉骨干:
model/necks.py(Sam3DualViTDetNeck,Sam3TriViTDetNeck) - 文本编码器: 外部提供(如CLIP、BERT等)
3.2.1 SAM3VLBackbone 基类
继承关系: SAM3VLBackbone → torch.nn.Module
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
vision_backbone | Sam3DualViTDetNeck | 无 | 视觉骨干网络,提取多尺度图像特征 |
language_backbone | nn.Module | 无 | 语言编码器,编码文本提示和边界框 |
scalp | int | 0 | 标量参数:丢弃最低分辨率特征的数量(如scalp=1丢弃最底层特征) |
act_ckpt_whole_vision_backbone | bool | False | 是否对整个视觉骨干网络启用激活检查点(节省显存) |
act_ckpt_whole_language_backbone | bool | False | 是否对整个语言骨干网络启用激活检查点 |
初始化参数表格:
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
visual | Sam3DualViTDetNeck | 无 | 视觉骨干网络,必须提供 |
text | nn.Module | 无 | 文本编码器,必须提供 |
compile_visual | bool | False | 是否使用torch.compile编译视觉骨干网络以加速推理 |
act_ckpt_whole_vision_backbone | bool | False | 是否对整个视觉骨干网络启用激活检查点 |
act_ckpt_whole_language_backbone | bool | False | 是否对整个语言骨干网络启用激活检查点 |
scalp | int | 0 | 丢弃最低分辨率特征的数量 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 见上表初始化参数 | 无 | 初始化视觉-语言骨干网络 |
forward | samples: Tensor (图像批次), captions: List[str] (标题列表), input_boxes: Tensor 或 None (输入边界框), additional_text: List[str] 或 None (附加文本) | output: dict | 完整前向传播:调用forward_image和forward_text,返回包含视觉和语言特征的字典 |
forward_image | samples: Tensor | output: dict | 图像前向传播:提取视觉特征,支持激活检查点 |
_forward_image_no_act_ckpt | samples: Tensor | output: dict | 无激活检查点的图像前向传播:实际调用视觉骨干网络,处理scalp参数,返回SAM2和SAM3特征 |
forward_text | captions: List[str], input_boxes=None, additional_text=None, device=“cuda” | output: dict | 文本前向传播:编码文本提示,支持激活检查点 |
_forward_text_no_ack_ckpt | captions: List[str], input_boxes=None, additional_text=None, device=“cuda” | output: dict | 无激活检查点的文本前向传播:实际调用语言编码器,支持附加文本编码 |
输出字典结构 (forward 方法返回):
vision_features: Tensor - 视觉特征(SAM3级别)vision_pos_enc: List[Tensor] - 视觉位置编码backbone_fpn: List[Tensor/NestedTensor] - 多尺度骨干特征(特征金字塔)sam2_backbone_out: dict 或None- SAM2骨干输出(包含vision_features,vision_pos_enc,backbone_fpn)language_features: Tensor - 语言特征language_mask: Tensor - 语言注意力掩码language_embeds: Tensor - 编码器前的文本嵌入additional_text_features: Tensor (可选) - 附加文本特征additional_text_mask: Tensor (可选) - 附加文本注意力掩码
3.2.2 SAM3VLBackboneTri 三重头视觉-语言骨干网络
继承关系: SAM3VLBackboneTri → SAM3VLBackbone
类作用: 三重头视觉骨干网络(SAM3、交互式、传播)与文本编码器的组合。视觉骨干网络为Sam3TriViTDetNeck,同时输出三种不同的视觉特征:SAM3检测特征、交互式细化特征和传播跟踪特征。
特有属性:
- 继承所有父类属性
vision_backbone类型强制为Sam3TriViTDetNeck
初始化参数表格:
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
visual | Sam3TriViTDetNeck | 无 | 三重头视觉骨干网络,必须为Sam3TriViTDetNeck类型 |
text | nn.Module | 无 | 文本编码器 |
compile_visual | bool | False | 是否编译视觉骨干网络 |
scalp | int | 0 | 丢弃最低分辨率特征的数量 |
特有方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
forward_image | samples: Tensor, need_sam3_out=True, need_interactive_out=True, need_propagation_out=True | output: dict | 三重头图像前向传播:可选择性输出三种特征类型 |
_forward_image_tri_no_act_ckpt | samples: Tensor, need_sam3_out=True, need_interactive_out=True, need_propagation_out=True | output: dict | 无激活检查点的三重头图像前向传播 |
输出字典结构 (forward_image 方法返回): 根据need_*参数选择性包含以下键:
- SAM3输出(当
need_sam3_out=True):vision_features: Tensor - SAM3视觉特征vision_mask: Tensor - SAM3视觉掩码vision_pos_enc: List[Tensor] - SAM3位置编码backbone_fpn: List[NestedTensor] - SAM3多尺度特征
- 交互式输出(当
need_interactive_out=True):interactive: dict - 包含vision_features,vision_mask,vision_pos_enc,backbone_fpn
- 传播输出(当
need_propagation_out=True):sam2_backbone_out: dict - 包含vision_features,vision_mask,vision_pos_enc,backbone_fpn
3.2.3 VisionOnly 仅视觉骨干网络
继承关系: VisionOnly → torch.nn.Module
类作用: 仅视觉骨干网络的包装器,用于无语言输入的推理场景。支持分块推理(chunk-wise inference)以处理大图像,并支持编译优化。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
vision_backbone | nn.Module | 无 | 视觉骨干网络 |
should_compile | bool | 自动判断 | 是否应编译模型(根据compile_mode或compile_extra_args) |
compile_mode | str 或 None | None | 编译模式(如"reduce-overhead", "max-autotune") |
compile_extra_args | dict | {} | 传递给torch.compile的额外参数 |
compiled | bool | False | 是否已编译 |
n_features | int | 无 | 特征维度(用于创建虚拟语言特征) |
forward_in_chunk_for_eval | bool | False | 评估时是否分块前向传播 |
eval_chunk_size | int | 4 | 评估分块大小 |
eval_cast_to_cpu | bool | False | 评估时是否将特征转换为CPU |
scalp | int | 0 | 丢弃最低分辨率特征的数量 |
初始化参数表格:
| 参数名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
visual | nn.Module | 无 | 视觉骨干网络 |
n_features | int | 无 | 特征维度(必须提供) |
forward_in_chunk_for_eval | bool | False | 评估时是否分块前向传播 |
eval_chunk_size | int | 4 | 评估分块大小 |
eval_cast_to_cpu | bool | False | 评估时是否将特征转换为CPU |
scalp | int | 0 | 丢弃最低分辨率特征的数量 |
compile_mode | str | None | 编译模式 |
compile_extra_args | dict | None | 编译额外参数 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 见上表初始化参数 | 无 | 初始化仅视觉骨干网络 |
_compile | 无 | 无 | 编译视觉骨干网络(如果配置了编译) |
forward_image | samples: Tensor | output: dict | 图像前向传播:编译模型(如果需要),提取视觉特征 |
forward_text | captions: List[str], input_boxes=None, additional_text=None, device=“cuda” | output: dict | 虚拟文本前向传播:返回零张量作为语言特征(保持接口一致性) |
3.2.4 TriHeadVisionOnly 三重头仅视觉骨干网络
继承关系: TriHeadVisionOnly → VisionOnly
类作用: 三重头仅视觉骨干网络,视觉骨干网络为Sam3TriViTDetNeck,同时输出SAM3、交互式和传播三种视觉特征。用于无语言输入但需要多类型视觉特征的场景。
特有属性:
- 继承所有父类属性
vision_backbone类型强制为Sam3TriViTDetNeck
特有方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
forward_image | samples: Tensor, need_sam3_out=True, need_interactive_out=True, need_propagation_out=True | output: dict | 三重头图像前向传播:可选择性输出三种特征类型,功能与SAM3VLBackboneTri.forward_image类似但不包含语言处理 |
注意:TriHeadVisionOnly的forward_text方法与VisionOnly相同,返回虚拟语言特征。
3.3 Prompt 集成包装 (geometry_encoders.py)
说明: Prompt 是一个几何提示工具类,用于操作几何提示(框、点、掩码),遵循 PyTorch 序列优先的约定。它封装了三种类型的几何提示:边界框(boxes)、点(points)和掩码(masks),并提供了统一的接口进行拼接、克隆等操作。MaskEncoder 是掩码编码器的基类,负责将输入掩码下采样并添加位置编码。FusedMaskEncoder 是 MaskEncoder 的子类,额外融合了图像特征。SequenceGeometryEncoder 是一个完整的几何提示编码器,支持将框、点、掩码编码为统一的序列表示。
类定义: class Prompt:(第83行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
box_embeddings | torch.Tensor 或 None | 边界框嵌入,形状为 (N_boxes, B, C_box),其中 C_box=4 |
point_embeddings | torch.Tensor 或 None | 点嵌入,形状为 (N_points, B, C_point),其中 C_point=2 |
mask_embeddings | torch.Tensor 或 None | 掩码嵌入,形状为 (N_masks, B, 1, H_mask, W_mask) |
box_mask | torch.Tensor 或 None | 边界框注意力掩码,形状为 (B, N_boxes),True 表示填充位置 |
point_mask | torch.Tensor 或 None | 点注意力掩码,形状为 (B, N_points),True 表示填充位置 |
mask_mask | torch.Tensor 或 None | 掩码注意力掩码,形状为 (B, N_masks),True 表示填充位置 |
box_labels | torch.Tensor 或 None | 边界框标签(正/负),形状为 (N_boxes, B),1 表示正样本 |
point_labels | torch.Tensor 或 None | 点标签(正/负),形状为 (N_points, B),1 表示正样本 |
mask_labels | torch.Tensor 或 None | 掩码标签(正/负),形状为 (N_masks, B),1 表示正样本 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
box_embeddings | torch.Tensor 或 None | None | 边界框嵌入,形状 (N_boxes, B, C_box) |
box_mask | torch.Tensor 或 None | None | 边界框注意力掩码,形状 (B, N_boxes) |
point_embeddings | torch.Tensor 或 None | None | 点嵌入,形状 (N_points, B, C_point) |
point_mask | torch.Tensor 或 None | None | 点注意力掩码,形状 (B, N_points) |
box_labels | torch.Tensor 或 None | None | 边界框标签,形状 (N_boxes, B) |
point_labels | torch.Tensor 或 None | None | 点标签,形状 (N_points, B) |
mask_embeddings | torch.Tensor 或 None | None | 掩码嵌入,形状 (N_masks, B, 1, H_mask, W_mask) |
mask_mask | torch.Tensor 或 None | None | 掩码注意力掩码,形状 (B, N_masks) |
mask_labels | torch.Tensor 或 None | None | 掩码标签,形状 (N_masks, B) |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
append_boxes | boxes: Tensor, labels: Tensor, mask: Tensor 或 None | 无 | 将新的边界框、标签和掩码追加到现有数据中 |
append_points | points: Tensor, labels: Tensor, mask: Tensor 或 None | 无 | 将新的点、标签和掩码追加到现有数据中 |
append_masks | masks: Tensor, labels: Tensor 或 None, attn_mask: Tensor 或 None | 无 | 将新的掩码、标签和注意力掩码追加到现有数据中(目前仅支持单掩码) |
clone | 无 | Prompt | 返回当前提示的深拷贝 |
_init_seq_len_and_device | box_embeddings, point_embeddings, mask_embeddings | (box_seq_len, point_seq_len, mask_seq_len, bs, device) | 内部方法:计算序列长度、批次大小和设备 |
_init_box | box_embeddings, box_labels, box_mask, box_seq_len, bs, device | (box_embeddings, box_labels, box_mask) | 内部方法:初始化边界框相关张量 |
_init_point | point_embeddings, point_labels, point_mask, point_seq_len, bs, device | (point_embeddings, point_labels, point_mask) | 内部方法:初始化点相关张量 |
_init_mask | mask_embeddings, mask_labels, mask_mask, mask_seq_len, bs, device | (mask_embeddings, mask_labels, mask_mask) | 内部方法:初始化掩码相关张量 |
类定义: class MaskEncoder(nn.Module):(第404行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
mask_downsampler | nn.Module | 掩码下采样模块 |
position_encoding | nn.Module | 位置编码模块 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
mask_downsampler | nn.Module | 无 | 掩码下采样模块 |
position_encoding | nn.Module | 无 | 位置编码模块 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | masks: Tensor, *args, **kwargs | (masks, masks_pos) | 前向传播:对输入掩码进行下采样并添加位置编码 |
类定义: class FusedMaskEncoder(MaskEncoder):(第425行)
属性表(继承自 MaskEncoder,新增):
| 属性名 | 类型 | 描述 |
|---|---|---|
fuser | nn.Module | 融合模块,用于融合图像特征和掩码特征 |
out_proj | nn.Module | 输出投影模块,nn.Identity 或 nn.Conv2d |
pix_feat_proj | nn.Conv2d | 图像特征投影层 |
初始化参数表(继承自 MaskEncoder,新增):
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
mask_downsampler | nn.Module | 无 | 掩码下采样模块 |
position_encoding | nn.Module | 无 | 位置编码模块 |
fuser | nn.Module | 无 | 融合模块 |
in_dim | int | 256 | 输入特征维度 |
out_dim | int | 256 | 输出特征维度 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | masks: Tensor, pix_feat: Tensor, **kwargs | (x, pos) | 前向传播:融合图像特征和掩码特征,输出融合后的特征和位置编码 |
类定义: class SequenceGeometryEncoder(nn.Module):(第470行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
d_model | int | 模型维度 |
pos_enc | nn.Module | 位置编码器 |
encode_boxes_as_points | bool | 是否将边界框编码为两个点(左上和右下) |
roi_size | int | ROI 对齐的尺寸(用于边界框特征池化) |
label_embed | nn.Embedding | 标签嵌入层,num_labels=6(若 encode_boxes_as_points=True)或 2 |
cls_embed | nn.Embedding 或 None | CLS 标记嵌入层,若 add_cls=True |
points_direct_project | nn.Linear 或 None | 点直接投影层(坐标 → 特征) |
points_pool_project | nn.Linear 或 None | 点特征池化投影层 |
points_pos_enc_project | nn.Linear 或 None | 点位置编码投影层 |
boxes_direct_project | nn.Linear 或 None | 边界框直接投影层(坐标 → 特征) |
boxes_pool_project | nn.Conv2d 或 None | 边界框特征池化投影层(ROI 对齐后) |
boxes_pos_enc_project | nn.Linear 或 None | 边界框位置编码投影层 |
final_proj | nn.Linear 或 None | 最终投影层,若 add_post_encode_proj=True |
norm | nn.LayerNorm 或 None | 层归一化,与 final_proj 配套 |
img_pre_norm | nn.Module | 图像特征预归一化层(nn.Identity 或 nn.LayerNorm) |
encode | nn.ModuleList 或 None | Transformer 编码层列表,若 num_layers>0 |
encode_norm | nn.LayerNorm 或 None | 编码器后的层归一化,若 encode 存在 |
mask_label_embed | nn.Embedding 或 None | 掩码标签嵌入层,若 add_mask_label=True |
add_mask_label | bool | 是否添加掩码标签嵌入 |
mask_encoder | MaskEncoder 或 None | 掩码编码器实例 |
use_act_ckpt | bool | 是否使用激活检查点 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
encode_boxes_as_points | bool | 无 | 是否将边界框编码为两个点 |
points_direct_project | bool | 无 | 是否使用直接投影编码点 |
points_pool | bool | 无 | 是否使用特征池化编码点 |
points_pos_enc | bool | 无 | 是否使用位置编码编码点 |
boxes_direct_project | bool | 无 | 是否使用直接投影编码边界框 |
boxes_pool | bool | 无 | 是否使用特征池化编码边界框 |
boxes_pos_enc | bool | 无 | 是否使用位置编码编码边界框 |
d_model | int | 无 | 模型维度 |
pos_enc | nn.Module | 无 | 位置编码器实例 |
num_layers | int | 无 | Transformer 编码层数 |
layer | nn.Module | 无 | 单层 Transformer 模块(将被复制 num_layers 次) |
roi_size | int | 7 | ROI 对齐的尺寸 |
add_cls | bool | True | 是否添加 CLS 标记 |
add_post_encode_proj | bool | True | 是否添加编码后投影层 |
mask_encoder | MaskEncoder 或 None | None | 掩码编码器实例 |
add_mask_label | bool | False | 是否添加掩码标签嵌入 |
use_act_ckpt | bool | False | 是否使用激活检查点 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | geo_prompt: Prompt, img_feats: Tensor, img_sizes: List[Tuple], img_pos_embeds: Tensor 或 None | (final_embeds, final_mask) | 前向传播:将几何提示编码为统一的序列表示 |
_encode_points | points: Tensor, points_mask: Tensor, points_labels: Tensor, img_feats: Tensor | (points_embed, points_mask) | 内部方法:编码点提示 |
_encode_boxes | boxes: Tensor, boxes_mask: Tensor, boxes_labels: Tensor, img_feats: Tensor | (boxes_embed, boxes_mask) | 内部方法:编码边界框提示 |
_encode_masks | masks: Tensor, attn_mask: Tensor, mask_labels: Tensor, img_feats: Tensor | (masks_embed, attn_mask) | 内部方法:编码掩码提示 |
注意: SequenceGeometryEncoder 支持三种编码方式的任意组合(直接投影、特征池化、位置编码),组合时采用简单相加。若 encode_boxes_as_points=True,边界框将被转换为两个点(左上和右下)并与现有点序列拼接。
4. 解码模块与记忆增强 (Decoders & Memory)
4.1 MultiplexMaskDecoder (multiplex_mask_decoder.py & maskformer_segmentation.py)
说明: MultiplexMaskDecoder 是一个支持多路复用(multiplex)的掩码解码器,能够同时预测多个目标的掩码。它借鉴了 MaskFormer 的思想,使用 Transformer 架构和动态多掩码选择机制。maskformer_segmentation.py 提供了 SegmentationHead、PixelDecoder、UniversalSegmentationHead 等组件,用于像素级特征解码和掩码预测。
类定义: class MultiplexMaskDecoder(nn.Module):(第16行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
transformer_dim | int | Transformer 特征维度 |
transformer | nn.Module | Transformer 模块 |
multiplex_count | int | 多路复用数量,即单个特征图中包含的目标数 |
num_multimask_outputs | int | 每个目标输出的多掩码数量(总掩码数为 (num_multimask_outputs+1) * multiplex_count) |
multimask_outputs_only | bool | 是否仅输出多掩码(不包含单掩码输出令牌) |
decode_mask_with_shared_tokens | bool | 是否使用共享令牌解码掩码 |
decode_mask_attribute_with_shared_tokens | bool | 是否使用掩码令牌(而非独立令牌)预测 IoU 和对象分数 |
num_mask_output_per_object | int | 每个目标的掩码输出数(num_multimask_outputs+1 或 num_multimask_outputs) |
num_mask_tokens | int | 掩码令牌总数(multiplex_count * num_mask_output_per_object 或 multiplex_count) |
pred_obj_scores | bool | 是否预测对象分数 |
use_multimask_token_for_obj_ptr | bool | 是否使用多掩码令牌作为对象指针 |
iou_token | nn.Embedding 或 None | IoU 令牌嵌入层(若 decode_mask_attribute_with_shared_tokens=False) |
obj_score_token | nn.Embedding 或 None | 对象分数令牌嵌入层(若 pred_obj_scores=True 且 decode_mask_attribute_with_shared_tokens=False) |
mask_tokens | nn.Embedding | 掩码令牌嵌入层 |
output_upscaling | nn.Sequential | 输出上采样模块(转置卷积 + 层归一化 + 激活) |
use_high_res_features | bool | 是否使用高分辨率特征 |
conv_s0, conv_s1 | nn.Conv2d 或 None | 高分辨率特征卷积层(若 use_high_res_features=True) |
output_hypernetworks_mlp | MLP 或 None | 输出超网络 MLP(若 num_multimask_outputs=0) |
output_hypernetworks_mlps | nn.ModuleList 或 None | 输出超网络 MLP 列表(每个掩码输出一个) |
iou_prediction_head | MLP | IoU 预测头 |
pred_obj_score_head | nn.Linear 或 MLP | 对象分数预测头 |
dynamic_multimask_via_stability | bool | 是否通过稳定性动态选择多掩码 |
dynamic_multimask_stability_delta | float | 稳定性计算中的 delta 阈值 |
dynamic_multimask_stability_thresh | float | 稳定性阈值 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
transformer_dim | int | 无 | Transformer 特征维度 |
transformer | nn.Module | 无 | Transformer 模块 |
multiplex_count | int | 无 | 多路复用数量 |
num_multimask_outputs | int | 3 | 每个目标输出的多掩码数量 |
activation | Type[nn.Module] | nn.GELU | 激活函数类 |
iou_head_depth | int | 3 | IoU 预测头的层数 |
iou_head_hidden_dim | int | 256 | IoU 预测头的隐藏维度 |
use_high_res_features | bool | False | 是否使用高分辨率特征 |
iou_prediction_use_sigmoid | bool | False | IoU 预测是否使用 sigmoid 输出 |
dynamic_multimask_via_stability | bool | False | 是否通过稳定性动态选择多掩码 |
dynamic_multimask_stability_delta | float | 0.05 | 稳定性计算中的 delta 阈值 |
dynamic_multimask_stability_thresh | float | 0.98 | 稳定性阈值 |
pred_obj_scores | bool | False | 是否预测对象分数 |
pred_obj_scores_mlp | bool | False | 对象分数预测是否使用 MLP |
use_multimask_token_for_obj_ptr | bool | False | 是否使用多掩码令牌作为对象指针 |
decode_mask_with_shared_tokens | bool | False | 是否使用共享令牌解码掩码 |
decode_mask_attribute_with_shared_tokens | bool | False | 是否使用掩码令牌预测 IoU 和对象分数 |
multimask_outputs_only | bool | False | 是否仅输出多掩码 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | image_embeddings: Tensor, image_pe: Tensor, multimask_output: bool, high_res_features: List[Tensor] 或 None, extra_per_object_embeddings: Tensor 或 None | dict[str, Tensor] | 前向传播:预测掩码、IoU 和对象分数 |
predict_masks | image_embeddings: Tensor, image_pe: Tensor, high_res_features: List[Tensor] 或 None, extra_per_object_embeddings: Tensor 或 None | dict[str, Tensor] | 核心预测方法:生成掩码、IoU 和对象分数 |
_get_stability_scores | mask_logits: Tensor | Tensor | 计算掩码 logits 的稳定性分数(基于上下阈值的 IoU) |
_dynamic_multimask_via_stability | all_mask_logits: Tensor, all_iou_scores: Tensor | (mask_logits_out, iou_scores_out) | 动态选择机制:当单掩码输出稳定性低时,选择多掩码输出中 IoU 最高的掩码 |
辅助类: class MLP(nn.Module):(第448行)—— 简单的多层感知机,用于 IoU 预测头等。
类定义: class SegmentationHead(nn.Module):(第56行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
use_encoder_inputs | bool | 是否使用编码器输入(而非骨干特征) |
aux_masks | bool | 是否输出辅助掩码(多层级) |
pixel_decoder | PixelDecoder | 像素解码器实例 |
no_dec | bool | 是否跳过解码器(直接卷积预测) |
mask_predictor | MaskPredictor 或 nn.Conv2d | 掩码预测器 |
act_ckpt | bool | 是否使用激活检查点 |
instance_keys | List[str] | 输出字典的键名列表 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
hidden_dim | int | 无 | 隐藏维度 |
upsampling_stages | int | 无 | 上采样阶段数 |
use_encoder_inputs | bool | False | 是否使用编码器输入 |
aux_masks | bool | False | 是否输出辅助掩码 |
no_dec | bool | False | 是否跳过解码器 |
pixel_decoder | PixelDecoder 或 None | None | 像素解码器实例 |
act_ckpt | bool | False | 是否使用激活检查点 |
shared_conv | bool | False | 是否共享卷积层(仅对 PixelDecoder) |
compile_mode_pixel_decoder | str 或 None | None | 像素解码器的编译模式 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | backbone_feats: List[Tensor], obj_queries: Tensor, image_ids: Tensor, encoder_hidden_states: Tensor 或 None | dict[str, Tensor] | 前向传播:生成预测掩码 |
_embed_pixels | backbone_feats: List[Tensor], image_ids: Tensor, encoder_hidden_states: Tensor 或 None | Tensor | 内部方法:嵌入像素特征 |
类定义: class PixelDecoder(nn.Module):(第184行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
hidden_dim | int | 隐藏维度 |
num_upsampling_stages | int | 上采样阶段数 |
interpolation_mode | str | 插值模式(“nearest” 等) |
conv_layers | nn.ModuleList | 卷积层列表 |
norms | nn.ModuleList | 归一化层列表 |
shared_conv | bool | 是否共享卷积层 |
out_dim | int | 输出维度 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
hidden_dim | int | 无 | 隐藏维度 |
num_upsampling_stages | int | 无 | 上采样阶段数 |
interpolation_mode | str | "nearest" | 插值模式 |
shared_conv | bool | False | 是否共享卷积层 |
compile_mode | str 或 None | None | 编译模式(torch.compile) |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | backbone_feats: List[Tensor] | Tensor | 前向传播:解码像素特征 |
类定义: class UniversalSegmentationHead(SegmentationHead):(第234行)
属性表(继承自 SegmentationHead,新增):
| 属性名 | 类型 | 描述 |
|---|---|---|
d_model | int | 模型维度 |
presence_head | LinearPresenceHead 或 None | 存在性预测头 |
cross_attend_prompt | nn.Module 或 None | 交叉注意力提示模块 |
cross_attn_norm | nn.LayerNorm 或 None | 交叉注意力归一化层 |
semantic_seg_head | nn.Conv2d | 语义分割头 |
instance_seg_head | nn.Conv2d | 实例分割头 |
初始化参数表(继承自 SegmentationHead,新增):
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
hidden_dim | int | 无 | 隐藏维度 |
upsampling_stages | int | 无 | 上采样阶段数 |
pixel_decoder | PixelDecoder | 无 | 像素解码器实例 |
aux_masks | bool | False | 是否输出辅助掩码 |
no_dec | bool | False | 是否跳过解码器 |
act_ckpt | bool | False | 是否使用激活检查点 |
presence_head | bool | False | 是否添加存在性预测头 |
dot_product_scorer | nn.Module 或 None | None | 点积评分器(若 presence_head=True) |
cross_attend_prompt | nn.Module 或 None | None | 交叉注意力提示模块 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | backbone_feats: List[Tensor], obj_queries: Tensor, image_ids: Tensor, encoder_hidden_states: Tensor 或 None, prompt: Tensor 或 None, prompt_mask: Tensor 或 None | dict[str, Tensor] | 前向传播:生成实例分割掩码、语义分割图和存在性 logits |
注意: maskformer_segmentation.py 还包含 LinearPresenceHead(第16行)和 MaskPredictor(第25行)等辅助类。
4.2 MaskDecoder (sam/mask_decoder.py)
说明: 标准的 Transformer 掩码解码器,用于根据图像嵌入和提示嵌入预测掩码。它支持多掩码输出(每个提示最多输出4个掩码:1个主掩码 + 3个辅助掩码)和动态多掩码选择机制(基于稳定性分数)。是 SAM 系列的核心解码组件。
类定义: class MaskDecoder(nn.Module):(第14行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
transformer_dim | int | Transformer 特征维度 |
transformer | nn.Module | Transformer 模块 |
num_multimask_outputs | int | 每个提示输出的多掩码数量(默认3个辅助掩码) |
iou_token | nn.Embedding | IoU 预测令牌嵌入层(1个令牌) |
num_mask_tokens | int | 掩码令牌总数(num_multimask_outputs + 1) |
mask_tokens | nn.Embedding | 掩码令牌嵌入层(num_mask_tokens 个令牌) |
pred_obj_scores | bool | 是否预测对象分数 |
obj_score_token | nn.Embedding 或 None | 对象分数令牌嵌入层(若 pred_obj_scores=True) |
use_multimask_token_for_obj_ptr | bool | 是否使用多掩码令牌作为对象指针 |
output_upscaling | nn.Sequential | 输出上采样模块(转置卷积 + 层归一化 + 激活) |
use_high_res_features | bool | 是否使用高分辨率特征 |
conv_s0, conv_s1 | nn.Conv2d 或 None | 高分辨率特征卷积层(若 use_high_res_features=True) |
output_hypernetworks_mlps | nn.ModuleList | 输出超网络 MLP 列表(每个掩码令牌一个) |
iou_prediction_head | MLP | IoU 预测头 |
pred_obj_score_head | nn.Linear 或 MLP | 对象分数预测头(若 pred_obj_scores=True) |
dynamic_multimask_via_stability | bool | 是否通过稳定性动态选择多掩码 |
dynamic_multimask_stability_delta | float | 稳定性计算中的 delta 阈值(用于上下阈值) |
dynamic_multimask_stability_thresh | float | 稳定性阈值(低于此值时切换到多掩码输出) |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
transformer_dim | int | 无 | Transformer 特征维度 |
transformer | nn.Module | 无 | Transformer 模块 |
num_multimask_outputs | int | 3 | 每个提示输出的多掩码数量 |
activation | Type[nn.Module] | nn.GELU | 激活函数类(用于上采样模块) |
iou_head_depth | int | 3 | IoU 预测头的层数 |
iou_head_hidden_dim | int | 256 | IoU 预测头的隐藏维度 |
use_high_res_features | bool | False | 是否使用高分辨率特征 |
iou_prediction_use_sigmoid | bool | False | IoU 预测是否使用 sigmoid 输出(限制到 [0,1]) |
dynamic_multimask_via_stability | bool | False | 是否通过稳定性动态选择多掩码 |
dynamic_multimask_stability_delta | float | 0.05 | 稳定性计算中的 delta 阈值 |
dynamic_multimask_stability_thresh | float | 0.98 | 稳定性阈值 |
pred_obj_scores | bool | False | 是否预测对象分数 |
pred_obj_scores_mlp | bool | False | 对象分数预测是否使用 MLP(否则使用线性层) |
use_multimask_token_for_obj_ptr | bool | False | 是否使用多掩码令牌作为对象指针 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | image_embeddings: Tensor, image_pe: Tensor, sparse_prompt_embeddings: Tensor, dense_prompt_embeddings: Tensor, multimask_output: bool, repeat_image: bool, high_res_features: List[Tensor] 或 None | (masks, iou_pred, sam_tokens_out, object_score_logits) | 前向传播:根据图像嵌入和提示嵌入预测掩码、IoU、SAM令牌和对象分数 |
predict_masks | image_embeddings: Tensor, image_pe: Tensor, sparse_prompt_embeddings: Tensor, dense_prompt_embeddings: Tensor, repeat_image: bool, high_res_features: List[Tensor] 或 None | (masks, iou_pred, mask_tokens_out, object_score_logits) | 核心预测方法:连接令牌、运行Transformer、上采样特征、生成掩码和预测分数 |
_get_stability_scores | mask_logits: Tensor | Tensor | 计算掩码 logits 的稳定性分数:基于上下阈值(±delta)的 IoU |
_dynamic_multimask_via_stability | all_mask_logits: Tensor, all_iou_scores: Tensor | (mask_logits_out, iou_scores_out) | 动态选择机制:当单掩码输出(令牌0)的稳定性分数低于阈值时,选择多掩码输出(令牌1~3)中 IoU 最高的掩码 |
辅助类: class MLP(nn.Module):(第299行)—— 简单的多层感知机,用于 IoU 预测头等。包含 num_layers 个线性层和 ReLU 激活(最后一层除外),可选 sigmoid 输出。
工作原理:
- 令牌连接: 将
iou_token、mask_tokens(以及可选的obj_score_token)与稀疏提示嵌入拼接。 - Transformer 处理: 将拼接后的令牌与图像嵌入(+密集提示嵌入)输入 Transformer。
- 特征上采样: 通过转置卷积上采样 Transformer 输出特征。
- 掩码生成: 通过超网络 MLP 将掩码令牌嵌入映射到权重,与上采样特征进行矩阵乘法生成掩码 logits。
- 分数预测: 通过 IoU 预测头(MLP)和对象分数预测头(线性层或 MLP)生成质量分数。
- 动态选择: 在推理时(非训练),若
dynamic_multimask_via_stability=True,则根据稳定性分数动态选择最佳掩码。
4.3 SimpleMaskEncoder (model/memory.py)
说明: 轻量级时序记忆编码器,用于将前一帧的像素特征与掩码(分割结果)融合并压缩为记忆表示,供后续帧的 Attention 模块读取。它是多目标跟踪中记忆增强机制的核心组件,专门设计为轻量级以支持实时视频处理。
类定义: class SimpleMaskEncoder(nn.Module):(第166行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
mask_downsampler | SimpleMaskDownSampler | 掩码下采样器,将掩码下采样到与像素特征相同的空间分辨率 |
pix_feat_proj | nn.Conv2d | 像素特征投影层(1x1卷积),用于调整像素特征的通道维度 |
fuser | SimpleFuser | 融合器,将像素特征和下采样掩码融合的模块 |
position_encoding | nn.Module | 位置编码生成器(通常与视觉骨干共享) |
out_proj | nn.Identity 或 nn.Conv2d | 输出投影层(1x1卷积),将融合特征投影到目标维度;如果输入输出维度相同则为恒等映射 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
out_dim | int | 无 | 输出特征维度 |
mask_downsampler | SimpleMaskDownSampler | 无 | 掩码下采样器实例 |
fuser | SimpleFuser | 无 | 融合器实例 |
position_encoding | nn.Module | 无 | 位置编码生成器 |
in_dim | int | 256 | 输入像素特征的通道维度 |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
forward | pix_feat: Tensor(形状 (B, C, H, W)),masks: Tensor(形状 (B, M, H', W')),skip_mask_sigmoid: bool(默认 False) | dict[str, Tensor] | 前向传播:将像素特征与掩码融合,生成记忆特征和位置编码。输出字典包含 "vision_features"(融合特征)和 "vision_pos_enc"(位置编码列表) |
工作原理:
- 掩码预处理: 如果
skip_mask_sigmoid=False(默认),对掩码应用 sigmoid 激活,使其值域在 [0,1] 之间,减少与二值 GT 掩码的域差异。 - 掩码下采样: 通过
SimpleMaskDownSampler将掩码下采样到与像素特征相同的空间分辨率(通常下采样16倍)。 - 像素特征投影: 通过
pix_feat_proj(1x1卷积)调整像素特征的通道维度。 - 特征融合: 将投影后的像素特征与下采样掩码相加(元素级加法)。
- 融合处理: 通过
fuser(多层CXBlock堆叠)进行深度特征融合。 - 输出投影: 通过
out_proj将特征投影到目标维度(如果out_dim != in_dim)。 - 位置编码生成: 使用
position_encoding从融合特征生成位置编码。
相关组件:
SimpleMaskDownSampler(第21行): 渐进式掩码下采样器,专门设计支持多路复用(multiplex)机制,允许同时处理多个目标的掩码。- 核心参数:
embed_dim(输出维度)、kernel_size(卷积核大小)、stride(每层步长)、total_stride(总下采样倍数)、multiplex_count(多路复用计数)、interpol_size(可选插值尺寸)。 - 工作原理: 通过
num_layers = log₂(total_stride) / log₂(stride)层卷积堆叠实现逐级下采样,每层下采样stride倍,通道数增加stride²倍。支持可选的预插值以适应特定分辨率。
- 核心参数:
CXBlock(第90行): ConvNeXt 风格残差块,使用深度可分离卷积和层缩放(Layer Scale)。- 核心参数:
dim(通道数)、kernel_size(深度卷积核大小)、drop_path(随机深度率)、layer_scale_init_value(层缩放初始值)。 - 结构:
DwConv→LayerNorm→1x1 Conv(扩展4倍)→GELU→1x1 Conv(收缩回原维度)→层缩放→残差连接。
- 核心参数:
SimpleFuser(第148行): 简单融合器,将多个CXBlock(或其他模块)堆叠起来。- 核心参数:
layer(基础层类)、num_layers(堆叠层数)、dim(输入维度)、input_projection(是否添加输入投影)。 - 功能: 可选地添加输入投影层(1x1卷积),然后堆叠指定数量的层。
- 核心参数:
设计特点:
- 轻量化: 使用深度可分离卷积(ConvNeXt块)和渐进式下采样,保持较低的计算开销。
- 多路复用支持:
SimpleMaskDownSampler的multiplex_count参数允许同时处理多个目标的掩码,这是多目标跟踪的关键。 - 域适应: 通过 sigmoid 激活将二值掩码转换为连续值,减少训练与推理时的域差异。
- 位置编码重用: 使用与视觉骨干相同的位置编码生成器,确保编码一致性。
4.4 PromptEncoder (sam/prompt_encoder.py) & PositionEmbeddingRandom
说明: 提示编码器,用于将各种类型的提示(点、框、掩码)编码为嵌入向量,供掩码解码器使用。PositionEmbeddingRandom 使用随机空间频率生成位置编码,是提示编码器的核心组件。
类定义: class PromptEncoder(nn.Module):(第14行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
embed_dim | int | 嵌入维度 |
input_image_size | Tuple[int, int] | 输入图像尺寸(高,宽) |
image_embedding_size | Tuple[int, int] | 图像嵌入的空间尺寸(高,宽) |
pe_layer | PositionEmbeddingRandom | 位置编码层 |
num_point_embeddings | int | 点嵌入数量(4个:正点、负点 + 2个框角点) |
point_embeddings | nn.ModuleList | 点嵌入层列表(4个 nn.Embedding) |
not_a_point_embed | nn.Embedding | ”非点”嵌入(用于填充点) |
mask_input_size | Tuple[int, int] | 掩码输入尺寸(4倍于图像嵌入尺寸) |
mask_downscaling | nn.Sequential | 掩码下采样模块(卷积 + 层归一化 + 激活) |
no_mask_embed | nn.Embedding | ”无掩码”嵌入(当没有掩码输入时使用) |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
embed_dim | int | 无 | 嵌入维度 |
image_embedding_size | Tuple[int, int] | 无 | 图像嵌入的空间尺寸(高,宽) |
input_image_size | Tuple[int, int] | 无 | 输入图像尺寸(高,宽) |
mask_in_chans | int | 无 | 掩码编码的隐藏通道数 |
activation | Type[nn.Module] | nn.GELU | 激活函数类(用于掩码下采样) |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
get_dense_pe | 无 | Tensor(形状 1xembed_dim x H x W) | 获取密集位置编码,用于点提示 |
_embed_points | points: Tensor(坐标), labels: Tensor(标签), pad: bool | Tensor(形状 B x N x embed_dim) | 嵌入点提示:应用位置编码并加上对应的点嵌入 |
_embed_boxes | boxes: Tensor | Tensor(形状 B x 2 x embed_dim) | 嵌入框提示:将框视为两个角点,分别加上框角点嵌入 |
_embed_masks | masks: Tensor | Tensor(形状 B x embed_dim x H x W) | 嵌入掩码提示:通过下采样卷积网络 |
_get_batch_size | points: 可选, boxes: 可选, masks: 可选 | int | 根据输入提示获取批次大小 |
_get_device | 无 | torch.device | 获取模型参数所在的设备 |
forward | points: 可选, boxes: 可选, masks: 可选 | (sparse_embeddings, dense_embeddings) | 前向传播:编码所有类型的提示,返回稀疏嵌入(点/框)和密集嵌入(掩码) |
工作流程:
- 点编码: 坐标 + 0.5(移到像素中心)→ 位置编码 → 根据标签(-1,0,1,2,3)加上对应的点嵌入。
- 框编码: 框坐标 + 0.5 → 视为两个角点 → 位置编码 → 分别加上角点嵌入(索引2和3)。
- 掩码编码: 通过三层卷积下采样(2x2 stride)到图像嵌入尺寸的1/4,然后投影到
embed_dim。 - 无提示处理: 若无点/框,添加填充点;若无掩码,使用
no_mask_embed扩展为密集嵌入。
类定义: class PositionEmbeddingRandom(nn.Module):(第202行)
属性表:
| 属性名 | 类型 | 描述 |
|---|---|---|
positional_encoding_gaussian_matrix | Tensor(注册的缓冲区) | 随机高斯矩阵(2 x num_pos_feats),用于生成位置编码 |
初始化参数表:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
num_pos_feats | int | 64 | 位置特征数(输出维度为 2 * num_pos_feats) |
scale | float 或 None | None | 高斯矩阵的缩放因子(若为 None 或 ≤0,则使用1.0) |
核心方法表:
| 方法名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
_pe_encoding | coords: Tensor(归一化到 [0,1]) | Tensor(形状 ... x C,C=2*num_pos_feats) | 核心编码函数:将坐标映射到正弦/余弦位置编码 |
forward | size: Tuple[int, int] | Tensor(形状 C x H x W) | 为指定尺寸的网格生成位置编码 |
forward_with_coords | coords_input: Tensor, image_size: Tuple[int, int] | Tensor(形状 B x N x C) | 为非归一化坐标生成位置编码:先归一化到 [0,1],再调用 _pe_encoding |
编码原理:
- 随机频率矩阵: 使用随机高斯矩阵
M(2 xnum_pos_feats)作为频率基础。 - 坐标归一化: 坐标归一化到 [0,1](网格生成)或通过图像尺寸归一化(
forward_with_coords)。 - 线性变换:
coords = 2 * coords - 1(映射到 [-1,1]),然后coords = coords @ M。 - 正弦/余弦编码:
coords = 2 * π * coords,然后拼接sin(coords)和cos(coords),得到维度2 * num_pos_feats的编码。
注意: PositionEmbeddingRandom 是 SAM 系列中广泛使用的位置编码方式,不同于传统的固定正弦编码,它使用随机频率矩阵,具有一定的泛化能力。
5. 高性能推理与支持模块 (Perf. & Utils)
5.1 NMS 非极大值抑制引擎 (sam3_multiplex_detector_utils.py)
核心方法:
nms_masks(...)/_nms_masks_core_batched(...): 核心级 Tensor 并行打压冗余模块,采用交并比 (IoU) 或交小比 (IoM)(针对局部遮挡)与得分对数百个粗粒度 Multi-object 输出进行大批量修剪提纯,这是 SAM 3 复用追踪(Multiplex)能并行锁定大量目标不干涉重叠的基础支撑点。
5.2 精度调度与编译引擎 (sam3/perflib/*, act_ckpt_utils.py)
说明: SAM 3 引入了更强大的激活检查点(Activation Checkpointing)来极大节省显存,并用 torch.compile 对各个核心函数(如 Transformer 的前向传播、NMS 的并联张量分配)进行 CUDA 图融合封装,以支持其在低资源上流畅推进高并发。