

模型的稀疏化与轻量化
背景信息
为什么需要模型稀疏化与轻量化?
随着深度学习模型规模的不断增长,模型稀疏化与轻量化变得越来越重要,一个重要的原因就是当前的模型是越做越大,因为增加模型的参数量仍然是提高精度的主要手段。然而,无限制地增长模型参数量自然不现实。计算资源限制、实时性要求、能耗消耗、存储空间和经济效益等都要求着稀疏化与轻量化。
为什么模型可以稀疏化?
稀疏化的来源是数据具有高度结构化的特性,结构化的本质导致了稀疏本身的产生。神经网络内部存在大量冗余信息,并不是所有的参数和结构都对深度神经网络的高判别性起作用。
稀疏化的常用手段
- 权重系数
- 激活稀疏
- 梯度稀疏
- 量化
- 模型轻量化设计
权重稀疏
原理
神经网络的绝大部分权重参数都是0值参数,且这个规律符合正态分布,对这部分参数进行稀疏化处理不会影响模型的性能。权重系数的本质是因为深度学习模型是自动提取特征的,在自动提取的特征中,存在大量冗余的不重要特征。
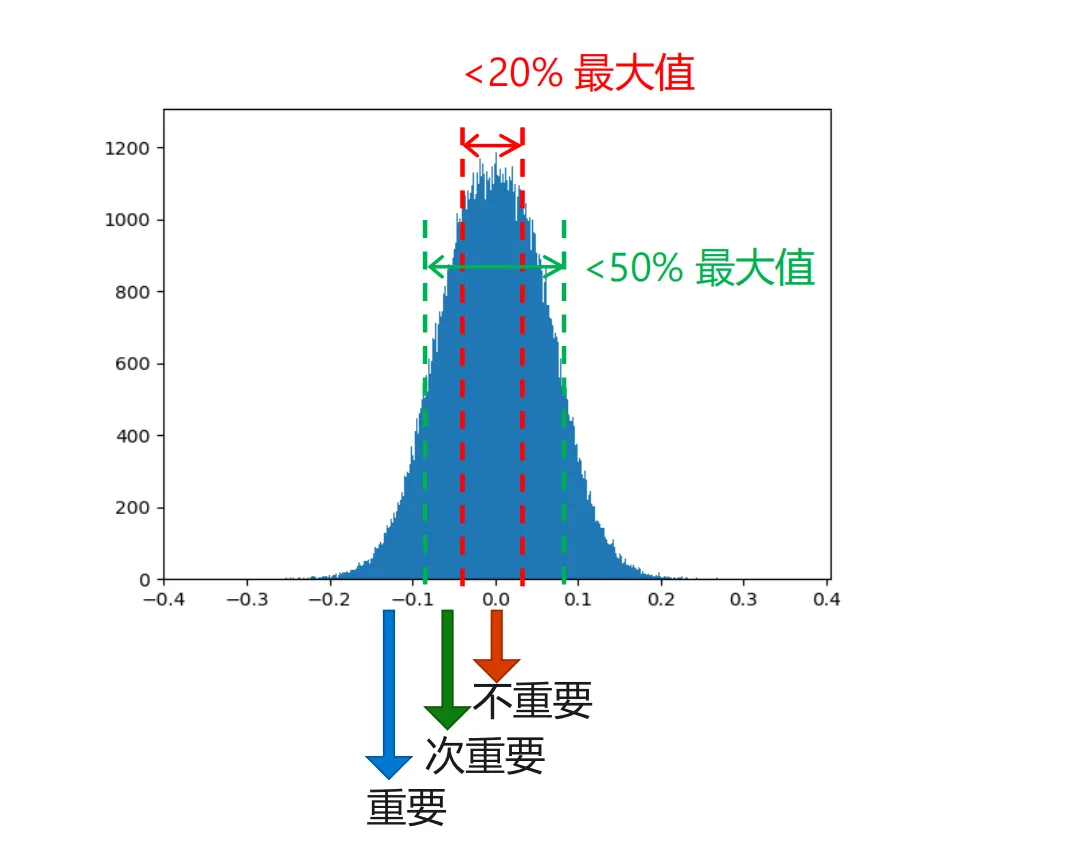
因此可行的一种权重系数化手段是对进行阈值剪枝后的模型再进行训练,从而得到稀疏化的网络。
权重稀疏化的优点
- 在内存开销相同的情况下,大稀疏模型通常比小密集模型的性能要更好
- 经过剪枝之后的系数模型是要优于同参数量的非稀疏模型
- 稀疏化后的参数可以用稀疏矩阵进行存储
权重系数化的三个步骤
- 训练完整模型
- 剪枝
- 再训练微调
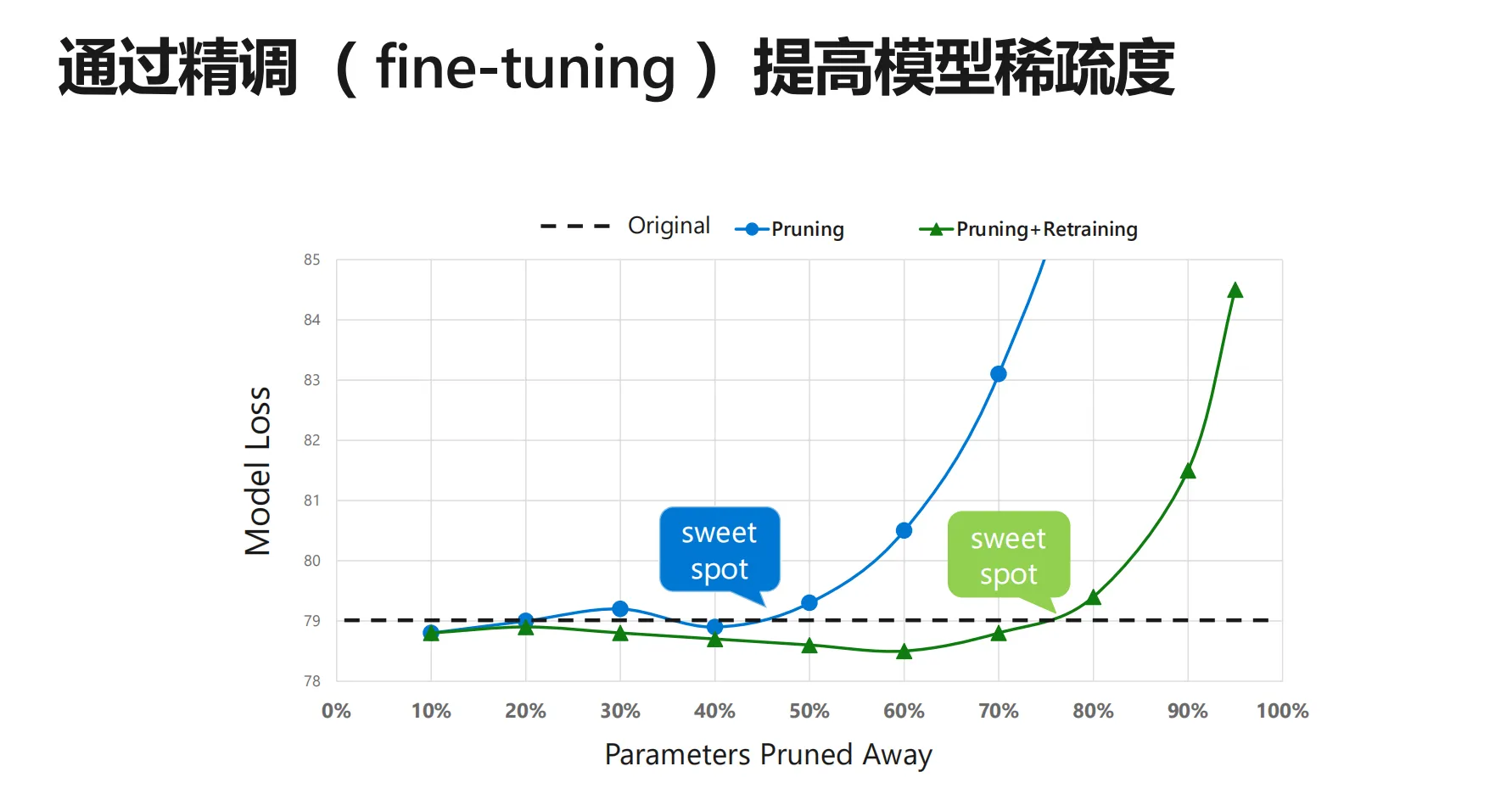
通常微调 (Fine-tuning) 后的稀疏模型性能与被剪枝参数量占比的曲线如下所示。
具体方法
非结构化剪枝 (unstructured pruning)
非结构化剪枝是直接减除低于阈值的权值,这种方法是一种细粒度的剪枝方法
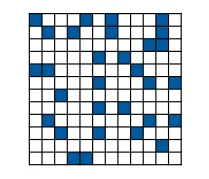
在 PyTorch 中,具体的实现方式是
- 随机非结构化剪枝,即随机把参数的某些值置为 0。可以使用
torch.nn.utils.prune模块来实现。
import torch.nn.utils.prune as prune
model = LeNet().to(device=device)
# 对 conv1 层进行剪枝
module = model.conv1
print("conv1 的参数:\n", list(module.named_parameters())) # 查看 conv1 层有哪些参数,以及对应的参数值是什么
# 进行非结构化剪枝
# 对 weight 参数进行随机非结构化剪枝
# 即随机把参数的某些值置为 0
# amount 表示剪枝比例,即将 30% 值随机置 0
prune.random_unstructured(module, name='weight', amount=0.3)
# named_buffers() 是 torch 中的一个用于获取模型或模块中所有注册的 buffers 及其名称的方法
# buffers 是模型中需要保存但不需要梯度更新的张量
# 这里保存的是剪枝的 mask,剪枝并不是直接把参数的值设为 0,而是通过 mask 机制把被剪枝的掩码置 0
# 这样,被剪枝的权重还可以被恢复,方法为 prune.remove()
print("weight 的 mask:\n", list(module.named_buffers()))
print("查看剪枝后的结果:\n", module.weight) # 查看剪枝后的结果
# 查看原始权重
print(module.weight_orig)
# 恢复权重
prune.remove(module, name='weight')
print("查看恢复的结果:\n", module.weight) # 查看恢复的结果点击下载: 随机非结构化剪枝代码
L1 非结构化剪枝,即根据参数的 L1 范数进行剪枝。L1 范数是指向量中每个元素的绝对值之和。L1 范数越小,表示该参数对模型的贡献越小,因此可以被剪枝。
# 对 conv1 层进行剪枝
module = model.conv1
print("conv1 的参数:\n", list(module.named_parameters())) # 查看 conv1 层有哪些参数,以及对应的参数值是什么
# 进行非结构化剪枝
# 对 bias 参数进行 L1非结构化剪枝
# 即随机把参数的某些值置为 0
# amount 表示剪枝比例,即将 30% 值随机置 0
# importance_scores 是用来指定重要性指标的接口
# 例如可以设置参数的绝对值信息作为指标
# 要求是该指标的形状必须与被剪枝的参数相同
importance_scores = module.bias.abs()
prune.l1_unstructured(module, name='bias', amount=0.3, importance_scores=importance_scores)
# named_buffers() 是 torch 中的一个用于获取模型或模块中所有注册的 buffers 及其名称的方法
# buffers 是模型中需要保存但不需要梯度更新的张量
# 这里保存的是剪枝的 mask,剪枝并不是直接把参数的值设为 0,而是通过 mask 机制把被剪枝的掩码置 0
# 这样,被剪枝的权重还可以被恢复,方法为 prune.remove()
print("bias 的 mask:\n", list(module.named_buffers()))
print("查看剪枝后的结果:\n", module.bias) # 查看剪枝后的结果- 点击下载: L1 非结构化剪枝代码
非结构化剪枝的特点是剪枝并不会改变参数矩阵的形状,只是变成了含有大量零值的稀疏矩阵。对应的优点是存储上可以用稀疏矩阵存储(只存储非零元素的数值和位置即可实现存储体积的减少)和计算上的开销减少(稀疏矩阵乘法)。
英伟达 A100 GPU 的 sparse tensor core 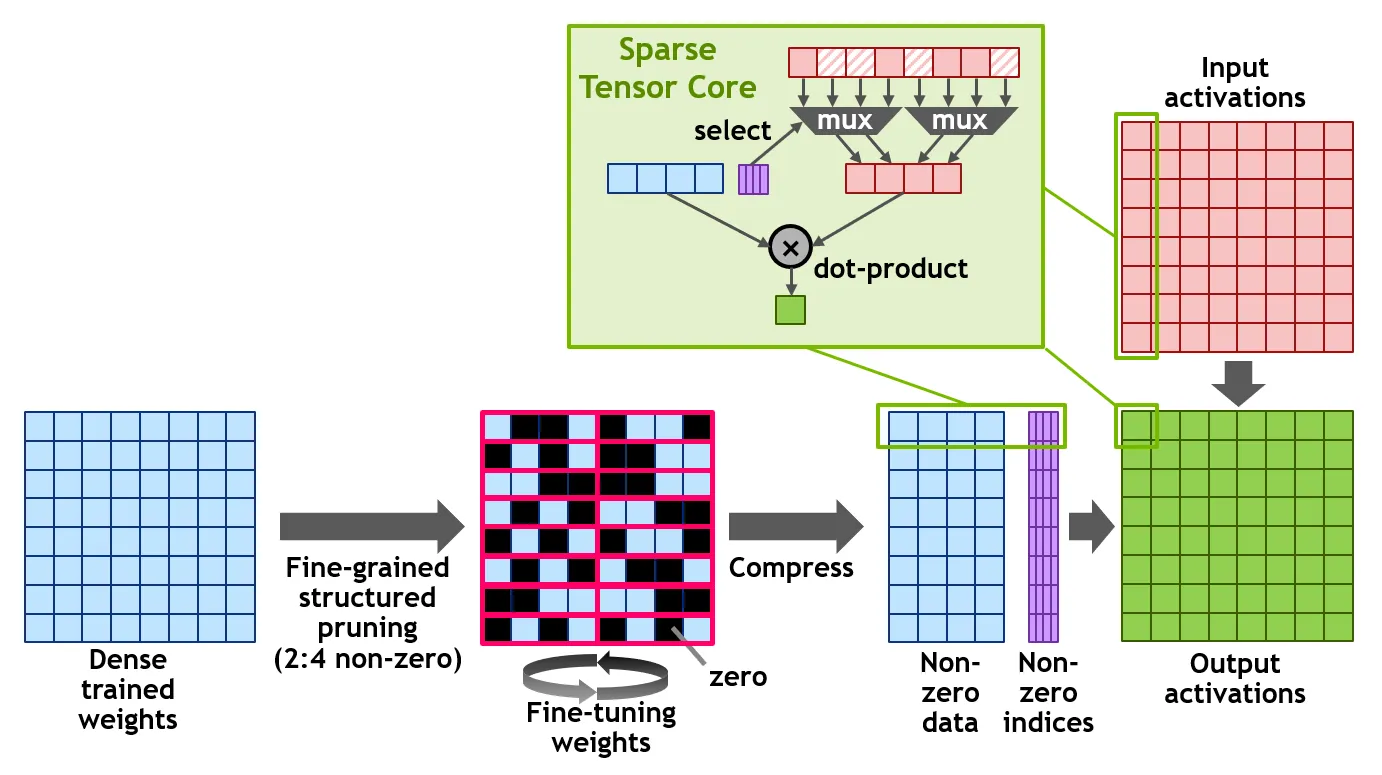
结构化剪枝 (structured pruning)
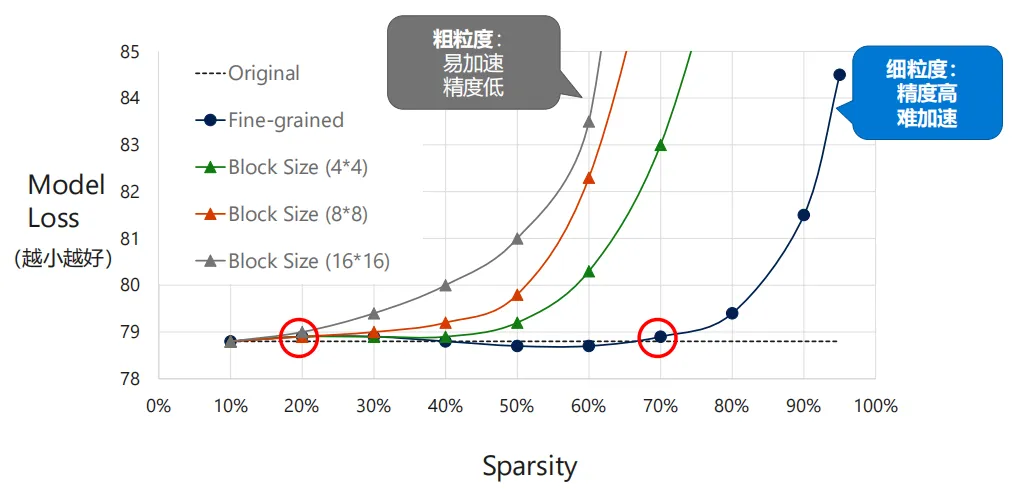
结构化剪枝是在将大矩阵划分为若干符合内存大小的子块的前提下,直接减除低于阈值的权值块的剪枝方法。这种方法是一种粗粒度的剪枝方法,粗粒度的剪枝方法的好处是可以加快推理速度,对硬件友好,缺点是会带来精度损失。这是因为规则化限制了对不重要参数的精准剪枝。
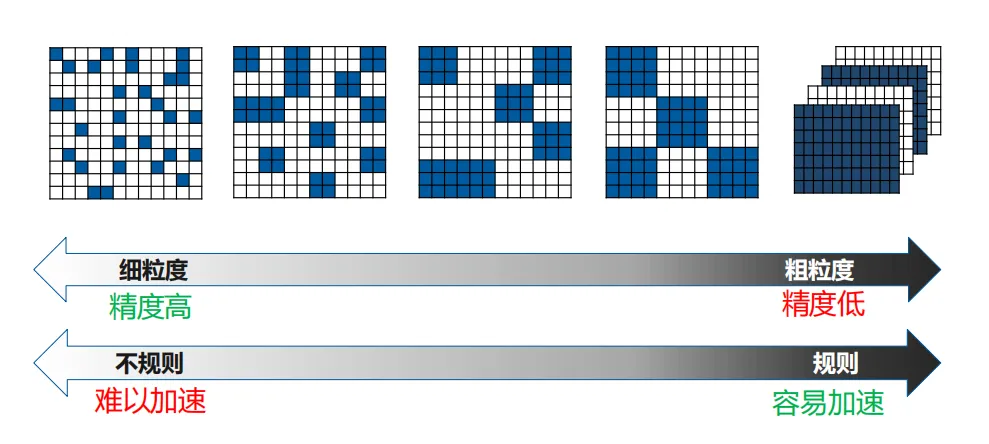
块大小对精度的影响
PyTorch 中的实现方式是
import torch.nn.utils.prune as prune
prune.ln_structured(module, name="weight", amount=0.5, n=2, dim=0)
print(module.weight)结构化剪枝的一种实现方式是通道剪枝,即将整个通道剪掉。它的自定义实现方式是
import torch
def index_remove(tensor, dim, index):
size_ = list(tensor.size())
a = tensor.size(dim)
b = len(index)
new_size = a - b
size_[dim] = new_size
select_index = list(set(range(tensor.size(dim))) - set(index))
new_tensor = torch.index_select(tensor, dim, torch.tensor(select_index))
return new_tensor
kernel = torch.rand(4, 2, 3)
kernel_pruned = index_remove(kernel, 0, [0, 2])
print(kernnel_pruned)正则化手段
如果一般训练后模型的权重分布不符合正态分布,可以使用正则化的方式强迫权重分布符合正态分布。常用的正则化手段有 L1 正则化和 L2 正则化。
- L1 正则化:L1 正则化是通过对模型的权重参数施加 L1 范数的惩罚项来实现的。
- L2 正则化:L2 正则化是通过对模型的权重参数施加 L2 范数的惩罚项来实现的。
- 下载结构化稀疏后微调模型的代码 prune_struct3.py
激活稀疏
神经网络的激活稀疏是指在模型推理过程中,大部分神经元的输出为零,只有少数神经元被激活。激活稀疏的来源主要是因为有激活函数的存在。这种现象在使用ReLU等非线性激活函数的网络中尤为明显,因为ReLU会将所有负值映射为零。
激活稀疏产生的主要原因:
- 非线性激活函数:如ReLU、Leaky ReLU等函数天然会产生稀疏激活
- 权重初始化和更新机制:导致某些神经元接收的输入总是处于激活函数的非激活区域
- 正则化技术:例如Dropout随机失活或L1正则化会促进激活稀疏
- 结构化数据特性:高维数据通常集中在低维子空间,不需要所有神经元都被激活
激活稀疏的优势:
- 计算效率提升:零激活可以跳过后续的乘法运算
- 减少过拟合:类似正则化效果,降低模型的有效复杂度
- 提高生物学可解释性:与人脑神经元的稀疏激活特性相似
常见的激活稀疏化方法:
- k-稀疏正则化:强制每层中最多只有k个神经元激活
- 显式稀疏约束:在损失函数中添加鼓励激活稀疏的惩罚项
- 结构化剪枝:移除训练过程中很少被激活的神经元
- 门控机制:动态决定哪些神经元应该被激活
梯度稀疏
梯度稀疏是指在深度神经网络的训练过程中,参数更新的梯度向量中大多数元素接近于零,只有少量元素具有显著非零值。这种特性对于大规模分布式训练和优化算法的设计至关重要。例如在分布式训练任务中,多台节点需要实时交换各自梯度计算数值,当模型参数高度稀疏时,99.9% 的梯度交换是冗余的。
梯度稀疏的形成原因:
- 参数重要性不均:不同参数对模型性能的贡献差异很大
- 激活稀疏的传导:由于激活稀疏,许多神经元不参与反向传播,导致相应权重的梯度为零
- 优化过程特性:随着训练进行,模型趋于收敛,大部分参数梯度逐渐变小
- 梯度消失问题:特别是在深层网络中,梯度可能在反向传播过程中衰减到接近零
梯度稀疏的应用价值:
- 分布式训练优化:只需传输和更新非零梯度,显著降低通信开销
- 计算资源优化:集中计算资源在重要梯度上,提高训练效率
- 自适应学习率策略:根据梯度稀疏度动态调整不同参数的学习率
常见的梯度稀疏化技术:
- 阈值稀疏化:只保留绝对值大于指定阈值的梯度
- Top-k稀疏化:只保留绝对值最大的k个梯度元素
- 随机稀疏化:以概率方式保留梯度元素,概率与梯度大小成正比
- 结构化稀疏化:保持特定模式的梯度非零,如块状或分组稀疏
梯度稀疏、权重稀疏和激活稀疏三者相互关联,共同构成了深度学习模型稀疏性的完整画像,是模型优化和压缩的重要理论基础。
一个简单的梯度稀疏化的想法是设置一个阈值,把大于阈值的梯度在节点间进行传播,而小于阈值的梯度则在本地进行积累,当超过阈值时再进行传播。这样可以减少通信开销和计算开销。
| 结构/非结构剪枝 | 动态/静态 | 数据驱动方式 | 训练时/推理时 | |
|---|---|---|---|---|
| 权重稀疏 | 非结构/结构化剪枝 | 静态 | 数据无关 | 推理 |
| 激活稀疏 | 结构化剪枝 | 动态 | 数据驱动 | 推理 |
| 梯度稀疏 | N/A | 动态 | 数据驱动 | 训练 |
量化
量化是一种通过降低用于表示模型参数的数值精度来压缩深度学习模型的技术。它将模型参数从高精度浮点数(如FP32)转换为低精度表示(如INT8、INT4或甚至二值),从而显著减少模型大小和计算资源需求。
量化原理
量化的基本思想是在可接受的精度损失范围内,使用更少的比特表示神经网络中的权重和激活值。这一过程可以用如下公式表示
其中, 是原始浮点值, 是量化后的整数值, 是量化比例因子, 是零点偏移。反量化过程则是
量化类型
按精度分类
- FP32 → INT8:将32位浮点数量化为8位整数,典型应用于推理加速
- FP32 → INT4:更进一步减少到4位表示,但精度损失增加
- 二值化(Binary):极端情况下参数只用1位表示(+1或-1)
- 三值化(Ternary):参数使用3个值表示(-1、0、+1)
按量化范围分类
- 权重量化:只对模型权重进行量化
- 激活量化:对神经元的激活输出进行量化
- 全量化:对权重和激活值都进行量化
按量化时机分类
- 训练后量化(Post-Training Quantization,PTQ):在模型训练完成后应用量化
- 量化感知训练(Quantization-Aware Training,QAT):在训练过程中考虑量化效应
训练后量化(PTQ)
PTQ是一种简单有效的量化方法,直接应用于已训练模型,无需重新训练:
- 收集校准数据(通常是训练集的小子集)
- 确定量化参数(如比例因子和零点)
- 转换模型权重和激活值为低精度表示
# PyTorch中的简单PTQ示例
import torch
# 假设model是已训练好的模型
model_fp32 = model
# 设置为评估模式
model_fp32.eval()
# 准备用于量化的模型
model_int8 = torch.quantization.quantize_dynamic(
model_fp32, # 原模型
{torch.nn.Linear, torch.nn.Conv2d}, # 要量化的层类型
dtype=torch.qint8 # 量化数据类型
)
# 保存量化后的模型
torch.save(model_int8.state_dict(), "quantized_model.pth")量化感知训练(QAT)
QAT在训练过程中模拟量化效果,使模型能够适应量化引起的精度损失:
- 在前向传播中模拟量化操作(计算使用量化值)
- 在反向传播中使用原始精度梯度更新(训练正常进行)
- 训练完成后应用真正的量化
# PyTorch中的QAT示例
import torch.quantization
# 准备量化配置
qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model_fp32.qconfig = qconfig
# 准备QAT
model_qat = torch.quantization.prepare_qat(model_fp32)
# 进行训练
for epoch in range(epochs):
train_one_epoch(model_qat, criterion, optimizer, data_loader, device)
# 转换为量化模型
model_int8 = torch.quantization.convert(model_qat.eval(), inplace=False)量化的优势和挑战
优势
- 存储效率:模型大小显著减少,INT8模型比FP32模型小约75%
- 推理加速:低精度运算速度更快,尤其在支持INT8计算的硬件上
- 能耗降低:降低算力和存储需求,减少能源消耗
- 边缘设备部署:使大模型能在资源有限的设备上运行
挑战
- 精度损失:量化不可避免地导致信息损失,尤其是在极低位宽时
- 特殊层处理:某些层(如Softmax)对量化特别敏感
- 硬件依赖:不同硬件对量化算法的支持程度不同
- 动态范围问题:处理激活值范围变化大的情况较困难
实际应用
量化已在各种应用中被广泛采用,特别是在移动设备和嵌入式系统中部署大型模型时:
- Google的TensorFlow Lite使用INT8量化使模型体积减少75%
- PyTorch、ONNX Runtime和TensorRT等框架都提供了完善的量化工具
- 边缘AI芯片(如Google TPU、英特尔Movidius等)专为低精度计算优化设计
量化技术与模型剪枝、知识蒸馏等方法结合使用,代表了高效AI部署的重要方向。
轻量化神经网络架构设计
轻量化神经网络旨在减少模型的计算量和参数量,使其能够在资源受限的设备上高效运行。
轻量化设计的原则
轻量化的一些概念:
- FLOPs: 浮点计算次数(Floating-point Operations),理解为计算量,可以用来衡量算法/模型是啊金的复杂度
- FLOPS:每秒所执行的浮点运算次数(Floating-point Operations Per Second),理解为计算速度,是一个衡量硬件性能/模型速度的指标,即一个芯片的算力。
- MACCs:乘加操作次数(Multiply-accumulate Operations),MACCs大约为FLOPs的一半,将 是为一个乘法累加或一个MACC
- Params:模型参数量,单位通常为M
- MAC:内存访问代价(Memory Access Cost),指的是输入单个样本,模型完成一次前向传播所发生的内存交换总量,即模型的空间复杂度,单位是Byte
设计原则
- 降低计算复杂度: 减少FLOPs和MACs
- 减少参数量: 降低模型大小和内存占用
- 硬件友好: 考虑实际硬件架构特性
- 平衡精度和效率: 在模型性能和资源消耗间取得平衡
- 优化网络结构: 使用更高效的基本模块替代传统卷积
MobileNet 系列
MobileNet v1
MobileNet v1 的核心创新是将标准卷积分解为深度可分离卷积
- 深度卷积(Depthwise Convolution): 对每个输入通道单独进行空间卷积
- 逐点卷积(Pointwise Convolution): 使用1×1卷积进行通道融合
这种分解大幅降低了计算复杂度:
- 标准卷积:
- 深度可分离卷积:
其中, 是卷积核尺寸, 是输入通道数, 是输出通道数, 是特征图尺寸。
计算复杂度降低了约 8-9 倍,而精度损失相对较小。
MobileNet v2
MobileNet v2 引入了两个重要改进:
- 倒置残差结构(Inverted Residual): 先扩展通道数,再进行卷积,最后压缩回原始维度
- 线性瓶颈(Linear Bottleneck): 在瓶颈层去掉了ReLU激活函数,防止特征信息丢失
这些改进使MobileNet v2在保持低计算量的同时,提高了特征表达能力。
ShuffleNet 系列
ShuffleNet v1
ShuffleNet v1主要创新点:
- 组卷积(Group Convolution): 将输入通道分组进行卷积,减少计算量
- 通道混洗(Channel Shuffle): 在组间进行特征混合,解决组卷积造成的信息流通受限问题
通道混洗操作示例:假设有9个通道分为3组,先将通道重塑为(3,3)形状,然后转置为(3,3),最后重塑回9个通道,实现了跨组特征交流。
ShuffleNet v2
ShuffleNet v2不仅关注FLOPs,还考虑了实际运行速度的影响因素:
- 内存访问成本(MAC): 提出通道数输入输出应相等的原则
- 并行度: 避免过多的组卷积分支
- 硬件友好: 减少了分支结构和碎片化操作
核心模块是通道分离(Channel Split)和通道混洗的组合,实现了更高效的特征提取。
其他轻量化网络架构
SqueezeNet
通过”Fire模块”实现压缩,该模块首先使用1×1卷积减少通道数(“squeeze”),然后并行应用1×1和3×3卷积(“expand”)。虽然参数量极小,但实际速度不尽如人意。
MnasNet/EfficientNet
使用神经架构搜索(NAS)自动设计轻量级网络,优化精度、延迟和计算量的平衡。EfficientNet还引入了复合缩放方法,同时缩放网络的宽度、深度和分辨率。
GhostNet
基于”幽灵”(Ghost)模块设计,该模块首先使用少量卷积生成内在特征,然后通过线性变换生成更多廉价特征。大幅降低计算成本的同时保持表达能力。
参考资料
- Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both Weights and Connections for Efficient Neural Networks. NIPS 2015.
- Frankle, J., & Carbin, M. (2019). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. ICLR 2019.
- Howard, A. G., Zhu, M., Chen, B., et al. (2017). MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L.C. (2018). MobileNetV2: Inverted Residuals and Linear Bottlenecks. CVPR 2018.
- Zhang, X., Zhou, X., Lin, M., & Sun, J. (2018). ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. CVPR 2018.
- Ma, N., Zhang, X., Zheng, H.T., & Sun, J. (2018). ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. ECCV 2018.
- Jacob, B., Kligys, S., Chen, B., et al. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. CVPR 2018.
- Han, S., Mao, H., & Dally, W. J. (2016). Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. ICLR 2016.
- Iandola, F.N., Han, S., Moskewicz, M.W., et al. (2016). SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
- Tan, M., & Le, Q.V. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ICML 2019.
- Han, K., Wang, Y., Tian, Q., et al. (2020). GhostNet: More Features from Cheap Operations. CVPR 2020.
- Alizadeh, M., Behboodi, A., van Baalen, M., et al. (2019). Gradient ℓ1 Regularization for Quantization Robustness. ICLR 2019.