

计算集群调度与资源管理系统
背景
假想你是一个多卡服务器集群的所有者,你打算把你的卡租出去收费赚💴。不过,不同的用户有不同的算力和软件需求,当他们的需求完成后,会释放相应的算力资源等。该如何合理分配调度?
把每个需求抽象为一个作业,每个作业有一个资源需求,包括算力、内存、存储等。作业的资源需求是动态变化的,可能会随着时间的推移而增加或减少。
集群中的一个作业的可以表示为
{
"name": "deep_learning_training",
"image": "nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04",
"command": ["python", "/app/train.py"],
"resources": {
"gpu": 2,
"cpu": 8,
"memory": "16Gi"
},
"env": {
"BATCH_SIZE": "64",
"LEARNING_RATE": "0.001"
},
"volumes": [
{
"name": "data-volume",
"hostPath": "/data",
"mountPath": "/app/data"
},
{
"name": "model-output",
"hostPath": "/outputs",
"mountPath": "/app/outputs"
}
],
"timeout": "24h",
"priority": "high"
}为每个作业分配资源,需要考虑如下的三个问题
- 如何提交作业与解决环境依赖问题?
- 如何高效调度作业并分配资源?
- 如何保证不同作业之间不会冲突? 例如不同的作业用了某一变量的相同名称或者同一个存储地址
作业、镜像与容器
可能存在的问题
1. 作业环境依赖问题
- 问题:
- 服务器上有没有预装好的需要的个性化环境?
- 不同作业需要的框架,依赖和版本不同,安装繁琐且重复,如何解决?
- 部署服务器上可能有大量重复安装的库,占用空间,如何解决?
- 目标:
- 复用已有的环境,避免重复安装。
- 层级化存储,避免重复存储。
2. 作业运行时资源隔离问题
- 问题:
- 集群资源被共享,如何保证不同作业之间不会冲突且不多占资源?
- 如何能够让不同作业可以运行不同的操作系统和命名空间?
- 如何保证隔离的同时,作业启动速度越快越好?
- 目标:
- 资源隔离,避免冲突。
- 资源共享,避免浪费。
- 启动速度快,避免等待。
- 资源使用率高,避免空闲。
虚拟化容器技术——Docker
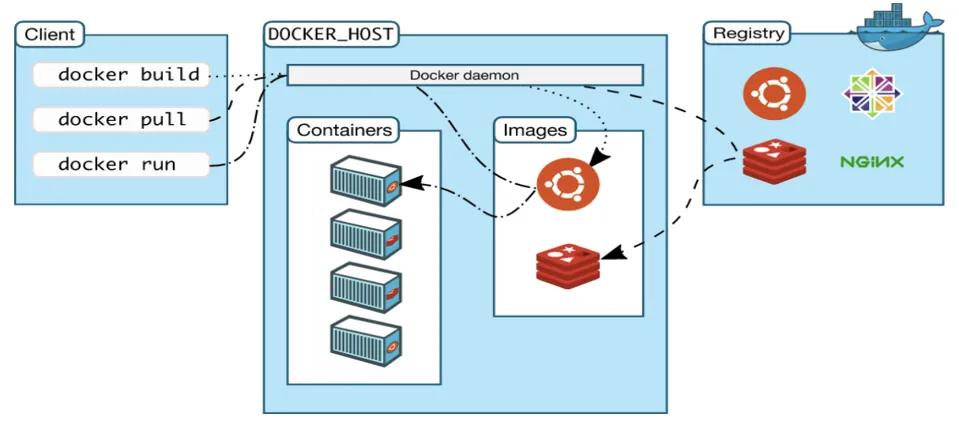
2013 年 Docker 公司的一个开源项目改写了云计算产业软件交付的历史进程。通过容器镜像,直接将一个应用运行所需的完整环境,即整个操作系统的文件系统也打包了进去,从而实现了“一次发布、随处运行”。
Docker 容器是一个轻量级、可执行的独立软件包,包含运行某个软件所需的所有代码、库、依赖项和配置文件。Docker 容器是基于镜像创建的,镜像是一个只读的模板,包含了运行某个应用所需的所有文件和环境。Docker 镜像可以在不同的操作系统上运行,而不需要担心环境依赖问题。
这样的设计,使得 Docker 可以用于成果交付,例如,乙方使用 torch 和 Ubuntu 编写了代码,将代码打包成 Docker 镜像,甲方只需要拉取镜像即可运行,即使甲方只有 tensorflow 和 centos。
- 轻量级: 一台机器上运行的多个容器可以共享操作系统内核,镜像通过文件系统分层进行构造,共享公共文件,降低磁盘用量
- 标准化: 容器基于开放式标准,能够在主流 Linux、Windows、和云在内的任何基础设施上运行
- 一致的运行环境: Docker 镜像提供了完整的运行时环境,不用担心平台迁移时运行环境的变化导致应用无法正常运行的情况
- 快速启动: 可做到秒级、甚至毫秒级的启动时间
- 隔离性: 解决了公用服务器中,资源易受到其他用户的影响问题
Docker 镜像的分层原理
Docker 镜像是由多个层组成的,每一层都是一个只读的文件系统。每一层都包含了对上一层的修改,例如添加、删除或修改文件。Docker 使用联合文件系统(Union File System)来将这些层组合在一起,形成一个完整的文件系统视图。
| 典型 Linux文件系统由 bootfs 和 rootfs 两部分组成 | Docker将其他layer加载其上,且每层都是只读 rootfs结构 | 相同的base镜像可以共享,只有顶层的容器层可以读写 |
|---|---|---|
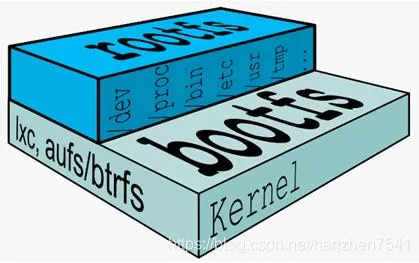 | 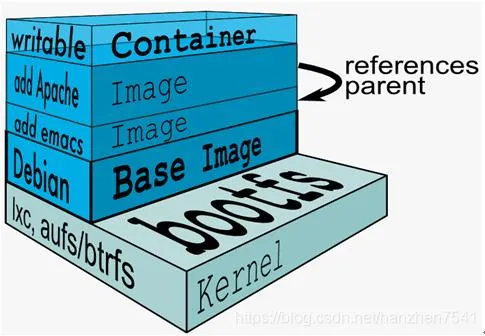 | 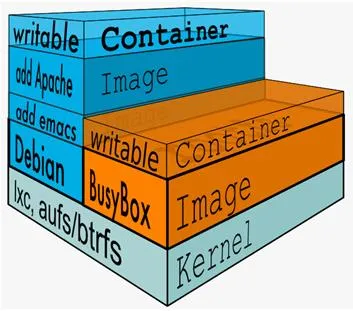 |
多个容器共享一份基础镜像,某个容器的修改会被限制在单个容器内,使用 Copy-on-Write 的技术实现,即,修改现有数据会先从镜像层将数据复制到容器层,修改后的数据直接保存在容器层中,而镜像层不会改变。
讲白了,镜像与容器的关系就像是一个类与对象的关系,镜像是一个类,容器是这个类的实例。镜像是只读的,而容器是可读可写的。

编写 Dockerfile, 创建镜像
以下是一个具体的 Dockerfile 示例,展示了不同指令如何创建镜像层
# 第1层:基础镜像层
FROM ubuntu:20.04
# 第2层:更新软件源并安装依赖
RUN apt-get update && apt-get install -y \
python3 \
python3-pip \
git
# 第3层:设置工作目录
WORKDIR /app
# /app 容器内部的路径,作用是创建容器的工作目录 /app
# 第4层:复制依赖文件
COPY requirements.txt .
# requirements.txt 文件来自 Host device
# 与此 Dockerfile 在同一目录中
# 作用是将主机的 requirements.txt 拷贝到容器的 /app/requirements.txt
# 第5层:安装Python依赖
RUN pip3 install --no-cache-dir -r requirements.txt
# 第6层:复制源代码
COPY src/ .
# src 文件夹来自 Host device
# 与此 Dockerfile 在同一目录中
# 作用是将主机的 src/ 拷贝到容器的 /app/
# 设置环境变量(不会创建新层,只是元数据)
ENV MODEL_PATH=/app/models
# 设置暴露端口(不会创建新层,只是元数据)
EXPOSE 8000
# 暴露容器内部的端口 8000
# 作用是声明容器会监听 8000 端口
# 设置启动命令(不会创建新层,只是元数据)
CMD ["python3", "app.py"]
# 在容器的 /app 目录下执行创建镜像层的指令:
FROM: 指定基础镜像,创建第一层RUN: 执行命令并创建新层COPY/ADD: 复制文件到容器并创建新层WORKDIR: 更改工作目录,创建新层
不创建新层的指令(仅添加元数据):
ENV: 设置环境变量EXPOSE: 声明容器监听的端口LABEL: 添加元数据CMD: 指定容器启动时执行的命令ENTRYPOINT: 设置容器入口点
当执行docker build命令时,Docker会按顺序执行Dockerfile中的每条指令,并为创建层的指令生成一个新的镜像层。这种分层存储的方式使得镜像可以被高效共享和重用。
需要注意的是创建此镜像时,Dockerfile 所在目录中必须有 requirements.txt 和 src/,否则会导致创建出错。如果没有相应文件,需要删除对应层级构建的指令。
项目目录/
├── Dockerfile
├── requirements.txt # COPY requirements.txt . 会复制这个文件
├── src/ # COPY src/ . 会复制这个文件夹
│ ├── app.py
│ ├── models/
│ └── utils/
└── 其他文件...构建完成后容器内部目录结构应为
/app/
├── requirements.txt # 从主机复制过来的依赖文件
├── app.py # 从主机的 src/app.py 复制过来的
├── models/ # 从主机的 src/models/ 复制过来的文件夹
│ └── (models 文件夹内的具体文件和子文件夹)
└── utils/ # 从主机的 src/utils/ 复制过来的文件夹
└── (utils 文件夹内的具体文件和子文件夹)
# 其他由基础镜像 ubuntu:20.04 自带的系统目录,例如:
# /bin/
# /etc/
# /home/
# /lib/
# /opt/
# /root/
# /sbin/
# /usr/
# /var/
# ... 等等Example: 模型训练容器
- 配置:Dockerfile
- 生成镜像
sudo docker build -t my_model_training_image .- 运行容器
sudo docker run -it --gpus all --name my_model_training_container -v /data:/app/data -v /outputs:/app/outputs my_model_training_image示例,训练MNIST分类
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04
# 基于CUDA 11.8和Ubuntu 22.04的基础镜像
# 安装Python和必要的库
RUN apt-get update && apt-get install -y \
python3 \
python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 设置工作目录
WORKDIR /app
# 安装PyTorch和相关依赖
RUN pip3 install --no-cache-dir \
torch==2.0.0+cu118 \
torchvision==0.15.0+cu118 \
torchaudio==2.0.0 \
--extra-index-url https://download.pytorch.org/whl/cu118 \
matplotlib \
tqdm \
tensorboard
# 复制训练脚本
COPY train.py /app/train.py
# 创建数据和输出目录
RUN mkdir -p /app/data /app/outputs
# 设置环境变量
ENV PYTHONUNBUFFERED=1
ENV BATCH_SIZE=64
ENV LEARNING_RATE=0.001
ENV NUM_EPOCHS=10
# 容器启动时执行的命令
CMD ["python3", "/app/train.py"]
Docker 常用命令
Docker 提供了丰富的命令行工具来管理容器和镜像。以下是一些最常用的 Docker 命令
镜像管理
# 从Docker Hub拉取镜像
docker pull [镜像名称]:[标签]
# 例如:docker pull ubuntu:20.04
# 列出本地镜像
docker images
# 删除镜像
docker rmi [镜像ID或名称]
# 构建镜像
docker build -t [镜像名称]:[标签] [Dockerfile所在目录]
# 例如:docker build -t my-app:1.0 .
# 或者自己指定 Dockerfile 文件: docker build -f Dockerfile -t train_dk_cpu .
# 为镜像添加标签
docker tag [源镜像]:[标签] [目标镜像]:[标签]容器管理
# 创建并启动容器
docker run [选项] [镜像名称] [命令]
# 常用选项:
# -d: 后台运行
# -p 主机端口:容器端口: 端口映射
# -v 主机目录:容器目录: 挂载卷
# --name: 指定容器名称
# --rm: 容器停止后自动删除
# --gpus all: 使用所有GPU
# -it: 进入容器
# 例如:docker run -d -p 8080:80 --name web nginx
# 列出运行中的容器
docker ps
# 列出所有容器(包括已停止的)
docker ps -a
# 启动/停止/重启容器
docker start/stop/restart [容器ID或名称]
# 删除容器
docker rm [容器ID或名称]
# 强制删除:docker rm -f [容器ID或名称]
# 进入容器交互式终端
docker exec -it [容器ID或名称] bash数据卷和网络
# 创建数据卷
docker volume create [卷名]
# 查看数据卷
docker volume ls
# 创建网络
docker network create [网络名]
# 查看网络
docker network ls日志和监控
# 查看容器日志
docker logs [容器ID或名称]
# 实时查看:docker logs -f [容器ID或名称]
# 查看容器资源使用情况
docker stats [容器ID或名称]
# 查看容器详细信息
docker inspect [容器ID或名称]清理资源
# 删除所有已停止的容器
docker container prune
# 删除未被使用的镜像
docker image prune
# 删除未被使用的数据卷
docker volume prune
# 删除所有未使用的资源(容器、镜像、网络、卷)
docker system prune高级应用
# 保存镜像为tar文件
docker save -o [文件名.tar] [镜像名称]
# 从tar文件加载镜像
docker load -i [文件名.tar]
# 查看镜像构建历史
docker history [镜像名称]
# 将容器保存为新镜像
docker commit [容器ID] [新镜像名称]:[标签]这些命令覆盖了 Docker 日常使用中的大部分场景。通过组合使用这些命令,可以方便地管理 Docker 环境下的容器和镜像。
调度性能指标
为例评价调度好坏,有如下性能指标。
- 吞吐量 (Throughput): 单位时间内完成的作业数量
- 完工时间 (Makespan) / 平均响应时间 (Average Response Time): 作业从提交到完成的时间
- 公平性 (Fairness): 不同作业之间的资源分配是否公平
- 资源利用率 (Resource Utilization): 集群资源的使用效率
- 服务等级协议 (SLA) 满足率: 满足用户需求的比例
公平性
为了满足公平性和资源利用率的要求,调度算法需要考虑多个因素,例如作业的优先级、资源需求、作业的运行时间等。
单资源调度——最大最小公平 (Max-Min Fairness) 算法
最大最小公平(Max-Min Fairness)算法是一种经典的资源分配策略,旨在实现”公平”的资源分配。其核心思想是:
- 优先分配给需求最小的用户:首先满足资源需求最小的用户
- 均等分配剩余资源:如果资源有剩余,则将剩余资源均等地分配给其他用户
- 迭代过程:持续这个过程直到所有资源分配完毕或所有用户需求都得到满足
算法步骤:
- 对所有用户按资源需求量排序
- 从需求最小的用户开始分配资源
- 如果满足了某用户的需求后还有剩余资源,则平均分配给剩余用户
- 重复直到资源耗尽或所有用户都满足
优点:
- 保证了资源分配的公平性
- 避免了”饥饿”现象
- 简单易实现
缺点:
- 可能不够高效,因为优先满足小需求可能导致整体吞吐量降低
- 不考虑作业优先级和截止时间等因素
主导资源公平 (Dominant Resource Fairness) 算法
主导资源公平(Dominant Resource Fairness, DRF)算法是为多资源环境设计的公平分配策略,解决了在异构计算环境中资源分配的问题。
基本原理:
- 主导资源识别:对每个用户,确定其主导资源(需求占总资源比例最高的资源)
- 资源分配:基于主导资源的份额公平分配资源
- 动态调整:随着资源使用情况变化不断调整分配
算法步骤:
- 计算每个用户对各类资源的需求占总资源的比例
- 确定每个用户的主导资源及其比例
- 选择主导资源份额最小的用户进行资源分配
- 更新资源状态,重复步骤1-3
优点:
- 适用于多资源环境(如GPU、CPU、内存混合需求)
- 满足策略无羡慕性、共享激励和Pareto效率
- 防止资源囤积,提高整体利用率
缺点:
- 计算复杂度较高
- 对资源需求变化频繁的场景响应可能不够灵敏
- 可能需要与其他策略结合使用
例子
- User A:
- 需求:
<1 GPU, 4 RAM> - GPU 份额: 1/9 (占总GPU)
- RAM 份额: 4/18 = 2/9 (占总RAM)
- 由于
1/9 (GPU) < 2/9 (RAM),User A 的主导资源是 RAM。
- 需求:
- User B:
- 需求:
<3 GPU, 1 RAM> - GPU 份额: 3/9 = 1/3 (占总GPU)
- RAM 份额: 1/18 (占总RAM)
- 由于
1/3 (GPU) > 1/18 (RAM),User B 的主导资源是 GPU。
- 需求:
基于最大最小公平 (max-min fairness) 的针对多资源类型 (e.g. GPU, CPU) 的调度算法
Objective: Subject to:
(其中,假设 x 是分配给User A的任务数,y 是分配给User B的任务数。总GPU为9,总RAM为18。User A每个任务需求<1GPU, 4RAM>,User B每个任务需求<3GPU, 1RAM>。User A的主导资源是RAM,其单位任务主导资源份额是4/18 = 2/9。User B的主导资源是GPU,其单位任务主导资源份额是3/9 = 1/3。因此,均衡主导份额的约束是
(2/9) * x = (1/3) * y,简化后即2x/9 = y/3。)
| Schedule | User A res.shares | User A dom.share | User B res.shares | User B dom.share | GPU total alloc. | RAM total alloc. |
|---|---|---|---|---|---|---|
| User B | <0, 0> | 0 | <3/9, 1/18> | 1/3 | 3/9 | 1/18 |
| User A | <1/9, 4/18> | 2/9 | <3/9, 1/18> | 1/3 | 4/9 | 5/18 |
| User A | <2/9, 8/18> | 4/9 | <3/9, 1/18> | 1/3 | 5/9 | 9/18 |
| User B | <2/9, 8/18> | 4/9 | <6/9, 2/18> | 2/3 | 8/9 | 10/18 |
| User A | <3/9, 12/18> | 2/3 | <6/9, 2/18> | 2/3 | 1 | 14/18 |
拓扑与亲和性 (Affinity)
在集群调度中,拓扑 (Topology) 指的是计算资源(如CPU、GPU、内存、网络接口)的物理或逻辑组织方式,例如它们如何连接在同一个PCIe交换机、CPU插槽、节点(服务器)或机架上。亲和性 (Affinity) 或 局部性 (Locality) 描述了分配给单个作业的多个资源单元在物理拓扑上的接近程度。
1. 调度的拓扑倾向性 (Sensitivity to Locality)
多GPU作业的性能高度依赖于所分配GPU之间的亲和性。换句话说,GPU之间的通信效率受到它们物理位置和连接方式的显著影响。
- 示例:一个需要8个GPU的作业,如果这8个GPU都位于同一个节点(服务器)内,并且通过高速互联(如NVLink或QPI)连接,其运行速度通常会远快于这8个GPU分布在8个不同节点上,通过普通网络连接的情况。
- 内部服务器局部性 (Intra-server locality):如下图1所示,即使在同一服务器内部,GPU位于同一个PCIe交换机下(SamePCIeSw)的性能通常优于位于同一CPU插槽但不同PCIe交换机(SameSocket),而这又优于位于不同CPU插槽(DiffSocket)的情况。
- 服务器间局部性 (Inter-server locality):如下图2所示,对于需要多个GPU的作业,将它们集中在少数节点(如一个节点内的4个GPU)通常比分散在多个节点(如4个节点各1个GPU)性能更好。
 *图注:左图为服务器内局部性对VGG16和ResNet-50性能的影响,右图为服务器间局部性对ResNet-50和InceptionV3性能的影响。*
*图注:左图为服务器内局部性对VGG16和ResNet-50性能的影响,右图为服务器间局部性对ResNet-50和InceptionV3性能的影响。*2. 共享异常 (Sharing Anomaly) 与拓扑忽视的代价
如果调度系统仅基于数量(例如Quota机制)分配GPU,而忽略了拓扑结构,即使为任务分配了足够数量的GPU,也可能因为GPU分布不佳(例如跨CPU Socket、跨PCIe Switch甚至跨机器)导致大量的通信开销和外部碎片,从而造成性能大幅下降。这种现象被称为“共享异常”。
- 例如:一个作业的多个GPU如果需要频繁跨PCIe交换机通信,可能导致50%的性能下降;如果需要跨机器通信,性能下降可能达到5倍甚至更多。
3. 考虑拓扑的调度策略 (如 HiveD)
为了解决上述问题,先进的调度算法会考虑集群的拓扑结构和作业的亲和性需求。
- 层级化资源定义 (Levels and Cells):
- 层级 (Levels):将资源按拓扑关系划分为不同层级,例如:
- Level 1: 单个GPU
- Level 2: 连接到同一PCIe交换机的GPU组
- Level 3: 连接到同一CPU Socket的GPU组
- Level 4: 整个节点(服务器)上的所有GPU
- 单元 (Cell):资源分配的基本粒度,它代表了一组具有特定互联拓扑和亲和性的GPU集合。
- 伙伴单元 (Buddy Cell):同一层级中的单元,可以合并或分裂以满足不同大小的资源请求。
- 层级 (Levels):将资源按拓扑关系划分为不同层级,例如:

- 分配策略:调度器(如HiveD)会尽可能从能够满足作业需求的最高层级(high-level,即亲和性最好的层级)分配资源。例如,如果一个作业需要4个GPU,调度器会优先尝试在同一个Level 3(同一CPU Socket)甚至Level 4(同一节点)找到一个包含4个GPU的Cell。
4. Buddy Cell Allocation Algorithm (伙伴单元分配算法)
这是一种管理层级化资源的具体算法,旨在高效分配和回收具有拓扑亲和性的资源单元。
- 维护信息:
- 绑定关系 (Binding):单元之间的拓扑连接关系。
- 每层级的空闲列表 (free list):记录每个层级可用的资源单元。
- 分配过程 (ALLOCATECELL):
- 如果当前层级没有足够大的空闲单元,则尝试从更高一级(cell_level+1)分配一个更大的单元。
- 将这个更大的单元分裂 (Split) 成多个较小的“伙伴单元 (buddies)”。
- 将分裂后的单元加入当前层级的空闲列表。
- 返回一个满足需求的单元。
- 释放过程 (RELEASECELL):
- 检查被释放单元的伙伴单元是否也在空闲列表中。
- 如果是,则将它们合并 (Merge) 成一个更高层级的单元,并递归地尝试释放这个合并后的单元。
- 如果伙伴单元不空闲,则直接将被释放单元加入当前层级的空闲列表。
- 优化目标与效果:
- 目标:尽可能保持更多的高层级单元可用,将可用单元维持在尽可能高的层级。
- 效果:减少GPU碎片,为需要高层级(即高亲和性)单元的作业创造更多调度机会。

通过综合考虑拓扑结构和作业的亲和性需求,调度系统可以显著提升集群的整体性能和资源利用率,特别是对于通信密集型的分布式训练任务。
灵活性 (flexibility)
调度的灵活性主要体现在两个方面:弹性 (elasticity) 和抢占 (preemption)。一个灵活的调度系统能够更好地适应动态变化的负载,提高资源利用率并保障服务等级协议 (SLA)。
弹性 (elasticity):
- 定义:当集群有空闲资源时,调度器允许作业或队列使用超出其配额 (quota) 的资源。当集群资源紧张时,这些超额使用的资源可以被回收。
- 目的:提高整体资源利用率。如上图“不使用抢占调度”所示,App1结束后,App2可以利用更多资源。
抢占 (preemption):
- 定义:当集群中没有未使用的资源,且一些优先级较高或未满足需求的队列(如上图中的App2)请求新资源时,集群会从那些已经消耗了超过其配置容量的队列(如上图中的App1)中回收资源。
- 目的:保障高优先级作业的SLA,确保关键任务及时获得资源。
- 效果:
- 如上图“使用抢占调度”所示,App1与App2均享有50%的资源配额。
- App2(可能为高优先级或有SLA需求)能够更快结束 (T3’ < T3),从而提高了SLA满足率。
- App1的完成时间虽然有所推迟 (T2’ > T2),但由于其在初期可能已经获得了较多资源,这种变慢通常是可以接受的。
- 这是一种兼顾了弹性和SLA的调度方式。
抢占的实现机制
不同的调度系统有不同的抢占实现方式。
1. HiveD中的抢占实现
HiveD 是一种考虑拓扑和虚拟集群 (VC) 的调度器,其抢占机制设计如下:
- 高优先级抢占低优先级:允许优先级高的任务抢占优先级低的任务所占用的资源单元 (cell)。
- 隔离低优先级单元:低优先级任务的单元通常被分配到远离高优先级任务绑定(或经常使用)的物理区域(例如,尽量避免分配给低优先级任务那些容易形成“伙伴单元”的资源),以降低它们被高优先级任务抢占的几率。
- 避免在高优设备上分配低优单元:高优先级作业也尽量避免在已经运行了低优先级作业的物理设备上分配新的单元,以减少潜在的干扰和抢占开销。
- 虚拟私有集群 (Virtual Private Clusters, VPCs):租户(Tenant A, Tenant B)在各自的VPC视图中操作,第三方调度器基于此视图进行调度。物理集群则动态地分配和回收物理资源单元。
2. Hadoop YARN中的抢占实现
Hadoop YARN (Yet Another Resource Negotiator) 是大数据生态中广泛使用的资源管理系统,其抢占实现步骤如下:
Step 1: 识别可抢占容器:从过度使用其队列配额的队列中,识别出可以被抢占的容器。例如,下图中Queue A配置了10个单位的资源但已使用了30个,而Queue C配置了20个单位但仍有20个单位的请求处于等待(Pending)状态。此时,App1(属于Queue A)的容器C6、C7可能被标记为可抢占。
Step 2: 通知Application Master:通知相关作业的Application Master,告知其部分容器即将被抢占,以便Application Master可以采取相应措施(如保存状态)。
Step 3: 强制终止容器:Resource Manager 强行杀死(kill)那些被标记为抢占的容器,释放资源给等待的更高优先级或未满足需求的作业。
抢占的代价 (Cost):
- 尤其在深度学习这类长周期、有状态的作业中,被抢占的作业当前可能只能失败。
- 如果作业没有很好地实现检查点 (checkpoint) 机制,那么从上一个检查点到被抢占时刻之间的所有训练成果都将被丢弃,造成计算资源的浪费。
因此,在设计抢占策略时,需要权衡SLA保障、资源利用率以及抢占带来的开销和对作业的影响。
参考资料: