

人工免疫计算(Artificial Immune Systems, AIS)是一类受生物免疫系统启发的智能优化与学习方法族。常见应用包括:连续/离散优化、组合优化、分类与聚类、异常检测、在线自适应控制等。
概述
生物免疫理论为人工免疫算法的建立奠定了基础。生物免疫主要有两种类型,分别是特异性免疫和非特异性免疫。生物免疫系统是通过自我识别、相互刺激与制约而构成了一个动态平衡的网络结构。
生物学概念
免疫:指机体对自身和异体识别与响应过程中产生的生物学效应的总和,正常情况下是一种维持机体循环稳定的生理性功能。生物机体识别异体抗原,对其产生免疫相应并清除,机体对自身抗原不产生免疫反应。
抗原:指能够刺激和诱导机体的免疫系统使其产生免疫应答,并能与相应的免疫应答产物在体内或体外发生特异性反应的物质
抗体:指免疫系统受抗原刺激后,免疫细胞转化为浆细胞并产生能与抗原发生特异性结合的免疫球蛋白,该免疫球蛋白即为抗体
T 细胞和 B 细胞:是淋巴细胞的主要组成成分。 B 细胞受到抗原刺激后,可增殖分化为大量浆细胞。但是,B 细胞不能识别大多数抗原,必须借助能识别抗原的辅助性 T 细胞来辅助 B 细胞活化,产生抗体。
免疫系统的主要功能有
- 免疫防御:机体防御病原微生物的感染
- 免疫稳定:机体通过免疫功能经常消除那些损伤和衰老细胞以维持机体的生理平衡
- 免疫监视:机体通过免疫功能防止或消除体内细胞在新陈代谢过程中发生突变的和异常的细胞
免疫系统分为固有免疫系统和自适应免疫系统。固有免疫系统是抵抗抗原感染的第一道防线;自适应免疫系统能够记住入侵的抗原特征,预防下一次攻击。自适应免疫系统有两个分支,体液免疫(由 B 细胞及其产物介导)和 细胞免疫(由 T 细胞介导)。
生物学免疫机理
免疫识别:通过淋巴细胞上的抗原受体与抗原特异性结合来实现敌我的区分。
免疫学习:学习的结果是免疫细胞的个体亲和度提高、群体规模扩大,并且最优个体以免疫记忆的形式得到保存。
免疫记忆:当免疫系统初次遇到一种抗原时,淋巴细胞需要一定的时间进行调整以更好地识别抗原,并在识别结束以后以最优抗体的形式保留对该抗体的记忆信息。而在免疫系统再次遇到相同或者结构相似的抗原时,在联想记忆的作用下,其应答速度大大提高。
克隆选择模型:免疫应答和免疫细胞的增殖在一个特定的匹配阈值之上发生。当淋巴细胞实现对抗原的识别, B 细胞被激活并增殖复制产生克隆 B 细胞,随后克隆细胞经历变异过程,产生对抗抗原具有特异性的抗体。
个体多样性
分布式和自适应性
免疫应答
免疫系统具有两种应答方式,初次应答和二次应答。初次应答发生在免疫系统遭遇第一次遇到过的抗原并对其反应的时候。免疫系统能够学习抗原,该机制产生免疫记忆,这样为身体再次遇到同样的抗原时产生二次应答。当抗体结合一个抗原时,B 细胞受刺激产生自体克隆,成长的克隆体现一种变异机制使免疫系统具有适应性。
免疫计算
| 生物免疫系统 | 免疫算法 |
|---|---|
| 抗原 | 优化问题 |
| 抗体 | 优化问题的可行解 |
| 亲和度 | 可行解的质量 |
| 细胞活化 | 免疫选择 |
| 亲和度成熟 | 变异 |
| 克隆抑制 | 克隆抑制 |
| 动态维持平衡 | 种群刷新 |
流程图 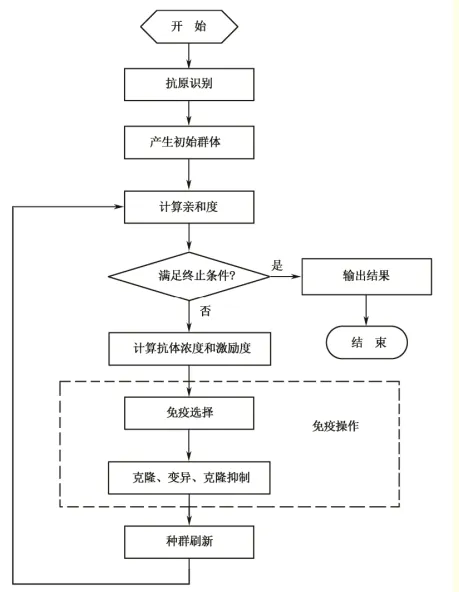
- 首先进行抗原识别,即理解待优化问题,对问题进行可行性分析,提取先验知识,构造出合适的亲和度函数,并指定各种约束条件
- 产生初始抗体群,通过编码把问题的可行解表示成解空间中的抗体,在解的空间中随机产生一个初始种群
- 对种群中的每一个可行解进行亲和度评价
- 判断是否满足算法终止条件。若满足终止条件则终止算法寻优过程,输出计算结果;否则继续寻优计算
- 计算抗体浓度和激励度
- 进行免疫处理,包括免疫选择、克隆、变异和克隆抑制
- 种群刷新,以随机生成的新抗体替代种群中的激励度较低的抗体,形成新一代抗体,转至步骤3
其中
- 免疫选择:根据种群中抗体的亲和度和浓度计算结果选择优质抗体,使其活化
- 克隆:对活化的抗体进行克隆操作,使其发生亲和度突变
- 变异:对克隆得到的副本进行变异操作,使其发生亲和度突变
- 克隆抑制:对变异结果进行再选择,抑制亲和度低的抗体,保留亲和度高的变异结果
核心算子
亲和度 (Affinity) 评价算子
表征免疫细胞与抗原的结合强度,类似遗传算法中的适应度。函数的输入为一个抗体(可行解),输出为亲和度评价结果。通常,亲和度可以直接设置为目标函数(对于最大化问题,因为亲和度越大说明越匹配)
除了用类似相似度的方式作为亲和度之外,也可以用距离来描述亲和度,距离越小,亲和度越大。例如,对于连续编码,可以设置为欧氏距离;对于离散编码,可以设置为海明距离。
抗体浓度评价算子
抗体的浓度表征抗体种群的多样性好坏,抗体浓度过高意味着种群中非常相似的个体大量存在,则寻优搜索会集中于可行解区间的一个区域,不利于全局优化。因此优化算法中应对浓度过高的个体进行抑制,保证个体的多样性。抗体浓度可以定义为
其中, 为种群规模, 表示第 个抗体, 表示抗体 和 之间的”相似度”,可以定义为
激励度 / 活化度(Stimulation)算子
很多免疫优化会同时考虑“解的质量(亲和度)”与“种群多样性(浓度/相似性)”,用一个综合指标来决定谁被活化、谁被抑制。一个常用的线性形式是
其中 为权重, 表示归一化后的亲和度。
亲和度与目标函数的关系(最小化/最大化)
若原问题为最小化 ,但算法希望“亲和度越大越好”,常见转换方式:
若 可能为负,可先平移:。
免疫记忆(Memory)机制
免疫系统会保存少量“记忆抗体”(当前最优/代表性解),并以较低频率被替换。工程上常用做法:
- 保留前 个最优个体作为记忆库
- 每代将种群与记忆库合并排序,更新
- 抑制时优先保留记忆库以避免丢失全局最优
种群刷新(Repertoire / Random Insertion)
为避免早熟收敛,引入“新抗体注入”:每代用随机解替换掉激励度最低的 个体。
建模与实现要点
抗体表示(编码)
- 二进制/离散编码:适合组合优化、规则匹配、字符串检测(负选择)。距离可用海明距离 。
- 实数向量编码:适合连续优化。距离可用欧氏距离 、曼哈顿距离 。
- 排列编码:如 TSP。相似度可用边重合率、交换距离等。
约束处理(可行性与惩罚函数)
对约束优化
常用惩罚法把约束并入目标:
然后用 构造亲和度 。
典型人工免疫算法
1) 克隆选择算法(CLONALG / Clonal Selection)
核心思想:高亲和度个体克隆更多、变异更少;低亲和度个体克隆更少、变异更强。
常见克隆数分配
将种群按亲和度从高到低排序,选取前 个进行克隆。第 名的克隆数可设为
其中 为克隆因子。
超变异(Hypermutation)强度
变异强度与亲和度负相关。对归一化亲和度 ,一种常用设定:
然后对实数编码做高斯扰动:
对二进制编码可用按位翻转概率 。
伪代码
Input: population size N, selected n, clone factor β, refresh rate r
Initialize P with N random antibodies
Initialize memory M = ∅
repeat
Evaluate Aff(a) for a in P
Update memory M with best antibodies from P ∪ M
Select top-n antibodies S from P
C = ∅
for i-th antibody in S (ranked):
clone n_i copies -> add to C
Hypermutate all clones in C (mutation inversely to affinity)
Evaluate Aff for clones; keep best clones to form P'
Suppress highly similar antibodies in P' (keep diversity)
Refresh: replace worst ⌊rN⌋ in P' with random antibodies
P = P'
until stop criterion
Output: best antibody in MPython 示例:用 CLONALG 优化 Rastrigin(连续最小化)
下面代码演示一个“可跑通”的最小实现:亲和度用 ,并做简单的相似度抑制与刷新。
import numpy as np
def rastrigin(x: np.ndarray) -> float:
# global minimum at x=0, f=0
A = 10.0
return A * x.size + np.sum(x * x - A * np.cos(2 * np.pi * x))
def clonalg_optimize(
f,
dim: int,
bounds: tuple[float, float] = (-5.12, 5.12),
N: int = 60,
n_select: int = 12,
beta: float = 6.0,
sigma_max: float = 0.8,
rho: float = 4.0,
gamma: float = 0.08,
refresh_rate: float = 0.15,
suppress_delta: float = 0.25,
iters: int = 200,
seed: int = 0,
):
rng = np.random.default_rng(seed)
lo, hi = bounds
def clip(x):
return np.clip(x, lo, hi)
# population: (N, dim)
P = rng.uniform(lo, hi, size=(N, dim))
best_x = None
best_f = np.inf
for _ in range(iters):
fvals = np.array([f(x) for x in P])
idx = np.argsort(fvals) # minimization
P = P[idx]
fvals = fvals[idx]
if fvals[0] < best_f:
best_f = float(fvals[0])
best_x = P[0].copy()
# affinity in [0,1], larger is better
aff = np.exp(-gamma * fvals)
aff_norm = (aff - aff.min()) / (aff.max() - aff.min() + 1e-12)
S = P[:n_select]
S_aff = aff_norm[:n_select]
# cloning
clones = []
for i, (x, a) in enumerate(zip(S, S_aff), start=1):
n_i = int(np.floor(beta * n_select / i))
if n_i <= 0:
continue
# hypermutation strength: high affinity -> small sigma
sigma = sigma_max * np.exp(-rho * a)
noise = rng.normal(0.0, sigma, size=(n_i, dim))
clones.append(clip(x + noise))
C = np.vstack(clones) if clones else clip(rng.uniform(lo, hi, size=(N, dim)))
C_f = np.array([f(x) for x in C])
# pick best N candidates from union
U = np.vstack([P, C])
U_f = np.concatenate([fvals, C_f])
U_idx = np.argsort(U_f)
P_new = U[U_idx][:N]
# simple suppression: remove too-close individuals (euclidean)
kept = []
for x in P_new:
if not kept:
kept.append(x)
continue
dmin = min(np.linalg.norm(x - y) for y in kept)
if dmin >= suppress_delta:
kept.append(x)
if len(kept) >= N:
break
# refill if suppressed too much
while len(kept) < N:
kept.append(rng.uniform(lo, hi, size=(dim,)))
P = np.array(kept)
# refresh worst
k = int(np.floor(refresh_rate * N))
if k > 0:
P[-k:] = rng.uniform(lo, hi, size=(k, dim))
return best_x, best_f
if __name__ == "__main__":
x_star, f_star = clonalg_optimize(rastrigin, dim=10, iters=300, seed=42)
print("best f:", f_star)
print("best x (first 5 dims):", x_star[:5])2) 负选择算法(Negative Selection, NSA)——异常检测
核心思想:生成一组“探测器(detectors)”去覆盖**非自体(non-self)**区域。训练阶段确保探测器不匹配任何“自体样本”;检测阶段若探测器匹配到输入,则判为异常。
基本定义(以二进制串为例)
自体集合 (正常样本),探测器集合 。匹配规则通常基于海明距离:
其中 为匹配半径。
伪代码
Input: self set S, detector count M, radius r
Initialize D = ∅
while |D| < M:
sample random candidate d
if ∀s∈S: d_H(d,s) > r:
add d to D
Detect(x): if ∃d∈D with d_H(d,x) ≤ r then anomaly else normalNSA 的难点是“覆盖率 vs 误报率”的权衡: 大则覆盖强但误报高; 小则漏报风险大。
3) 免疫网络模型(Immune Network)——多样性维持
Jerne 的免疫网络思想强调“抗体-抗体”之间的相互促进/抑制,从而形成动态平衡。
一种经典的浓度动力学形式(示意)
其中 为第 个抗体浓度, 表示促进(相似性带来的刺激), 表示抑制(过度相似导致竞争), 为自然衰减。通过网络抑制可显著提升“多峰问题”的多样性与稳态覆盖。
4) 免疫算法在优化中的常见“抑制”实现
免疫抑制用于去除“过于相似”的冗余解。常用做法:
- 计算个体间距离矩阵 ()
- 若 ,只保留亲和度更高者
工程优化:
- 用近邻结构(如 kNN)近似抑制,降低复杂度
- 分簇后在簇内做抑制
参数选择与实践建议
常用参数
- :种群规模(一般 20–200,随维度增大而增大)
- :选择并克隆的个体数(通常 到 )
- :克隆因子(越大开发越强,但计算更贵)
- / :最大变异强度(探索能力来源)
- :亲和度-变异强度的耦合(越大越“精英保守”)
- :抑制阈值(决定多样性维持强弱)
- :刷新率(避免停滞;但过大会变成随机搜索)
终止条件
- 最大迭代/最大评估次数
- 最优值若干代无改进(early stop)
- 亲和度达到阈值或满足约束精度
何时 AIS 特别好用
- 目标函数多峰且易早熟(免疫抑制/网络更有优势)
- 需要“记忆”与“在线自适应”(概念漂移、动态环境)
- 异常检测/安全(负选择天然契合)
常见坑
- 浓度/相似度计算 :大规模时需近似或分簇
- 亲和度缩放不当:导致“变异强度”失效(建议用归一化或指数映射)
- 刷新率过高:收敛困难;过低:停滞
与遗传算法(GA)的快速对比
- 相同点:种群搜索、选择与变异都是核心
- 不同点:AIS 强调“克隆选择 + 亲和度成熟(超变异)+ 抑制/网络维持多样性 + 记忆机制”
- 实务上:把 AIS 视为“更强调局部成熟与多样性抑制的种群优化框架”通常更准确
参考与延伸阅读
- de Castro, L. N., Von Zuben, F. J. Learning and Optimization Using the Clonal Selection Principle.
- Forrest, S. et al. Negative Selection 系列工作(异常检测/入侵检测的经典起点)。
- Farmer, J. D., Packard, N. H., Perelson, A. S. Immune network 模型的早期经典工作。