

图像分类任务的范式
图像分类是计算机视觉中的基本任务之一,目标是将输入的图像分配到预定义的类别中。给定一个图像 ,其中 、 和 分别表示图像的高度、宽度和通道数,图像分类的目标是学习出一个图像到类别的映射
其中 是类别的数量,数字 表示第 个类别。这个映射可以是人工设计的特征提取器 (feature extractor) 加上数据驱动的 (data-driven) 机器学习分类器,也可以是端到端 (end-to-end) 训练的深度神经网络。
在图像分类的任务中,类别标签的名称对分类结果并无实质影响,影响分类结果的核心实际上是各类别所表征的概念及其在数据空间中的分布形态。
例如,在一个包含猫、狗和鸟的图像分类任务中,为了方便计算机的计算,通常会给每个类别名称字符串分配一个数字标签,例如类别 1 可能代表猫,类别 2 代表狗,类别 3 代表鸟,用名称字符串还是用数字标签,分类器模型本质上都是一样的。毕竟,建立一个从数字到名称的字典,或者从名称到数字的字典,两种模式下学习到的分类器模型就一模一样了。
为了衡量图像分类模型的性能,我们通常使用准确率 (accuracy) 作为评估指标。准确率定义为模型输出的正确分类的样本数占输入的总样本数的比例
例如,在一个只有 A, B 两个类别的分类任务中,如果一个模型在 100 张测试图像中,模型预测的结果如下表所示
| 真实标签\模型预测 | 预测为 A 类别 | 预测为 B 类别 |
|---|---|---|
| 真实为 A 类别 | 45 | 5 |
| 真实为 B 类别 | 10 | 40 |
那么模型的准确率可以计算为
使用 conda 配置虚拟环境
Anaconda 是一个流行的 Python 发行版,提供了包管理和环境管理功能。使用 Anaconda 可以方便地创建和管理虚拟环境,避免不同项目之间的依赖冲突。
安装 Miniconda
Miniconda 是 Anaconda 的一个轻量级版本,只包含最基本的包管理功能,适合需要自定义环境的用户。对于中国大陆的用户,可以从上海交大镜像站选择适合自己操作系统的 Miniconda 安装包进行下载和安装。
下面以 Windows 操作系统,x86_64 架构为例,介绍如何安装 Miniconda。
- 首先访问镜像网站,使用 cltr + f 搜索 “miniconda3-latest”。
Miniconda3-latest-*表示的是最新的 Miniconda 发布版本。这里需要区分 Miniconda 和 Miniconda3,Miniconda3 表示的是基于 Python3 开发的包管理器,Miniconda 则是基于 Python2 开发的。
点击
Miniconda3-latest-Windows-x86_64.exe进行下载,下载完成后运行安装程序,按照提示完成安装。完成安装后,为了方便在终端中使用 conda 命令,需要将 conda 文件所在路径添加到系统环境变量
"PATH"中,这个可以在 Windows 系统的环境变量设置中完成。打开命令提示符 (cmd),输入
conda --version来验证 conda 是否安装成功。如果显示 conda 的版本号,说明安装成功。
创建虚拟环境
使用 conda 创建一个新的虚拟环境,可以使用以下命令:
conda create -n myenv python=3.12根据照提示输入 y 来确认创建环境。创建完成后,可以使用以下命令来激活环境:
conda activate myenv激活环境后,命令提示符会显示当前环境的名称,例如 (myenv) C:\Users\Username>,这表示当前已经进入了 myenv 环境。
更多关于 conda 的使用,可以参考官方文档 Conda Documentation 或我的博客 常用计算机指令/conda & pip 系列。
查看 NVIDIA GPU 信息与 CUDA 版本
在 Windows 系统中,可以使用以下命令来查看 NVIDIA GPU 的信息和 CUDA 版本:
nvidia-smi这个命令会显示当前系统中安装的 NVIDIA GPU 的型号、驱动版本、CUDA 版本以及 GPU 的使用情况等信息。如果命令提示显示 nvidia-smi 不是内部或外部命令,说明系统中没有安装 NVIDIA GPU 驱动或者环境变量没有正确配置。
使用 NVIDIA GPU 训练深度学习模型比使用 CPU 更快,因为 GPU 具有更高的并行计算能力,能够同时处理大量的计算任务。对于图像分类等计算密集型任务,使用 GPU 可以显著缩短训练时间,提高模型的迭代效率。
安装常见的 Python 包
在激活的虚拟环境中,可以使用 conda 或 pip 来安装所需的 Python 包。例如,可以用 conda 安装 PyTorch:
conda install pytorch torchvision torchaudio cudatoolkit=12.1 -c pytorch这个命令会安装 torch、torchvision、torchaudio 以及与 CUDA 12.1 兼容的 CUDA 工具包。根据自己的系统和 CUDA 版本,可以调整命令中的 CUDA 版本号。
当然也可以使用 pip 来安装 PyTorch,例如:
# 安装适配 CUDA 12.1 版本的最新 PyTorch 版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 如果你的电脑没有 NVIDIA GPU,可以安装最新的 CPU 版本的 PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu不过通常官方的 pip 和 conda 源在中国大陆访问速度较慢,可以更换为国内的镜像源,例如阿里云的 PyPI 镜像源,下载速度会快很多:
pip install numpy matplotlib scikit-learn -i https://pypi.aliyun.com/simple这里建议是使用 pytorch 官方的源来安装 cuda 版本的 PyTorch,因为非官方源可能不提供适合当前 Python 版本的、适合当前 CUDA 版本的、适合当前操作系统的 PyTorch 版本。
为了检测 PyTorch 是否安装成功以及是否能够使用 GPU,可以创建 Python 脚本:
# 保存为 test_pytorch.py
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA version: {torch.version.cuda}")
print(f"GPU device: {torch.cuda.get_device_name(0)}")并在终端中,在 test_pytorch.py 所在目录下输入以下命令来运行它
python test_pytorch.py如果显示和下面类似的内容,说明 PyTorch 安装成功并且能够使用 GPU 进行计算了:
PyTorch version: 2.5.1+cu121
CUDA available: True
CUDA version: 12.1
GPU device: NVIDIA GeForce RTX 4060 Laptop GPU如果安装的是 CPU 版本的 PyTorch,或者系统中没有 NVIDIA GPU,那么输出会显示 PyTorch 安装好了但是 CUDA 不可用,例如:
PyTorch version: 2.8.0+cpu
CUDA available: False完成以上步骤后,就成功配置好了 PyTorch 的开发环境,可以开始进行图像分类的实验了。
使用 PyTorch 构建神经网络并训练手写数字分类模型
安装了这么久,现在该来介绍这些包的作用都是什么了。在深度学习与数据科学生态中,NumPy 是构建高效数值计算的基石,提供了多维数组操作的核心能力;PyTorch (torch) 则是基于 NumPy 理念演进的现代深度学习框架,通过动态计算图和自动微分机制,让神经网络的设计与 GPU 加速训练变得灵活而高效;Matplotlib 作为强大的可视化库,能将枯燥的数据转化为直观的图表,帮助开发者洞察模型训练过程与结果分布;而 Scikit-learn 则填补了传统机器学习算法的空白,提供了一套简洁统一的接口来处理分类、回归及聚类任务,四者相辅相成,共同构成了从数据处理、模型构建到结果分析的一站式开发闭环。这四个包是后续章节中构建神经网络、训练模型、评估性能以及可视化结果的基础工具,掌握它们的使用是进行深度学习实验的第一步。
全连接网络
全连接神经网络,也叫多层感知机模型 (Multi-Layer Perceptron, MLP),是最基础的神经网络结构,每一层的神经元都与下一层的所有神经元相连。
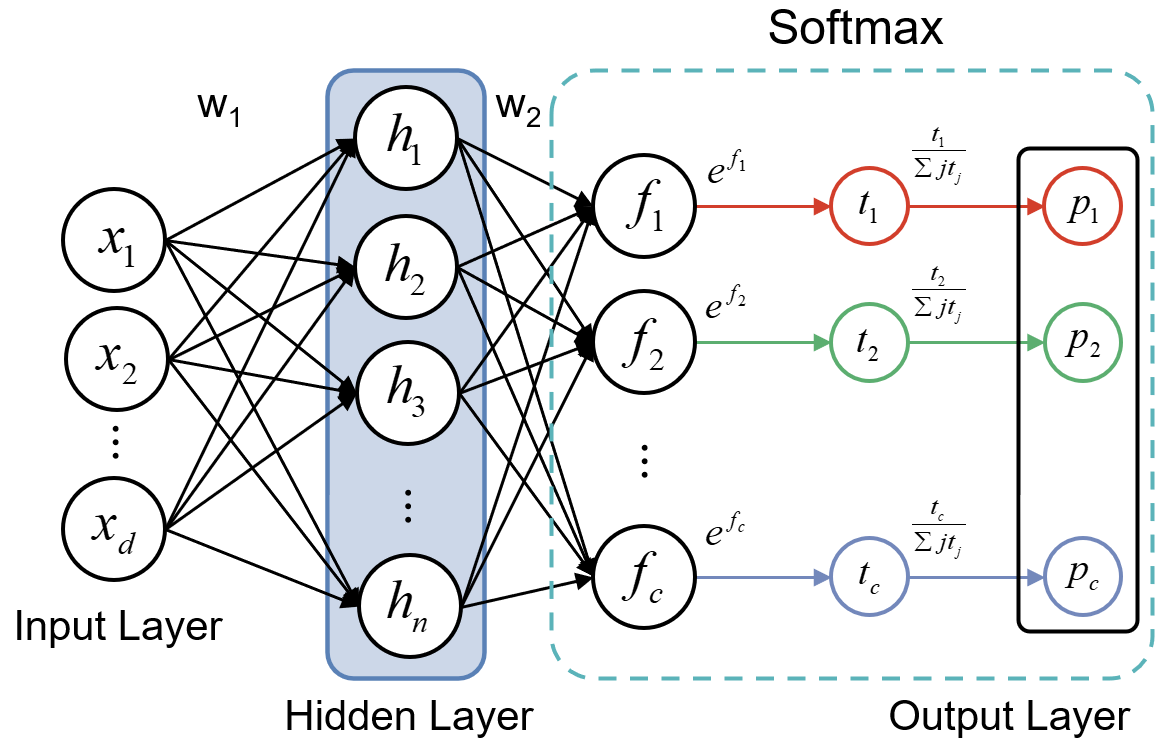
在 PyTorch 中,可以使用 nn.Linear 和激活函数来构建网络层:
nn.Linear(in_features, out_features):线性变换层nn.ReLU():修正线性单元激活函数,引入非线性nn.Softmax(dim):Softmax 激活函数,用于把模型输出的实数域 内的置信度分数转换为概率分布,dim参数指定了进行 Softmax 计算的维度
全连接神经网络的可学习参数存在于每一层的权重矩阵和偏置向量,这些参数通过训练数据进行优化,以使模型能够更好地拟合数据分布并进行准确的分类。可以用nn.Linear.weight 和 nn.Linear.bias 参数来访问每一层的权重和偏置参数。
一个简单的 MLP 实现
import torch
from torch import nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
# 定义网络层
self.fc1 = nn.Linear(28 * 28, 128) # 输入层 (784) -> 第一隐藏层 (128)
self.fc2 = nn.Linear(128, 64) # 第一隐藏层 (128) -> 第二隐藏层 (64)
self.fc3 = nn.Linear(64, 10) # 第二隐藏层 (64) -> 输出层 (10)
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 定义数据前向传播的路径
x = x.view(-1, 28 * 28) # 将输入图片展平为向量
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x) # 输出层这里不需要加 Softmax,因为后续的损失函数内部(如 CrossEntropyLoss)会自动应用 Softmax
return x这个网络包含了一个输入层、两个隐藏层和一个输出层,适用于处理长度和宽度均为 28 的灰度图像(如 MNIST 数据集)。输入层将 28×28 的图像展平为一个 784 维的向量,经过两层全连接和 ReLU 激活函数后,输出一个长度为 10 的向量,表示对 10 个类别的预测分数。
MNIST 数据集简介
MNIST 是一个手写数字数据集,包含 60,000 个训练样本和 10,000 个测试样本,每张图片大小为 28×28 像素。
训练代码实现
import torch
import torch.optim as optim
from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并将像素值归一化到 [0, 1] 范围
transforms.Normalize((0.1307,), (0.3081,)) # 对 MNIST 数据集进行标准化处理,均值为 0.1307,标准差为 0.3081
])
# 加载数据
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform) # 使用 MNIST 数据集的训练部分,下载数据并应用预处理
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) # 创建数据加载器,其中 batch_size 是每个批次的样本数量,shuffle=True 表示在每个 epoch 结束后打乱数据顺序
# 模型、损失函数、优化器
model = SimpleNet() # 实例化模型
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数适用于多分类问题
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 随机梯度下降优化器
# 训练循环 - 10 个 epoch
for epoch in range(10):
total_num, correct_num = 0, 0
for batch_idx, (data, target) in enumerate(train_loader): # 遍历训练数据
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播计算输出
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 优化器更新模型参数
with torch.no_grad(): # 在评估模型性能时不需要计算梯度
total_num += target.size(0) # 累加总样本数
correct_num += (output.argmax(dim=1) == target).sum().item() # 累加正确分类的样本数
acc = correct_num / total_num # 计算当前批次的准确率
print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}, Accuracy: {acc:.4f}') # 打印每个 epoch 的损失和准确率训练完成后,SimpleNet 模型在 MNIST 数据集上的准确率大致在 0.97 左右,这表明模型已经能够较好地学习到手写数字的特征并进行分类了。
张量形状(Shape)的重要性
在神经网络前向传播中,每一步的张量形状必须匹配,否则会出现 RuntimeError: size mismatch 错误。
常见错误排查方式
- 查看张量形状:
print(x.shape) - 检查层输入输出维度:确保
nn.Linear的in_features与上一层的输出匹配 - 展平操作:全连接层需要一维输入,使用
x.view(-1, 28*28)将图像展平
调试示例
# 在 forward 方法中添加调试打印
def forward(self, x):
print(f"Input shape: {x.shape}") # 应为 [batch_size, 1, 28, 28]
x = x.view(-1, 28*28)
print(f"After view shape: {x.shape}") # 应为 [batch_size, 784]
x = self.relu(self.fc1(x))
print(f"After fc1 shape: {x.shape}") # 应为 [batch_size, 128]
x = self.relu(self.fc2(x))
print(f"After fc2 shape: {x.shape}") # 应为 [batch_size, 64]
x = self.fc3(x)
print(f"After fc3 shape: {x.shape}") # 应为 [batch_size, 10]
return x教学部分的代码可以在 example.py 中找到
损失函数、反向传播和优化器
在上一节的训练循环中,我们使用了三行核心代码:
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数这三行代码对应了深度学习训练的三个核心步骤:评估误差、计算梯度、更新参数。下面分别展开讲解。
损失函数 (Loss Function)
损失函数衡量的是模型预测值与真实标签之间的不一致程度,是一个标量值 (可以比较大小)。在构建损失函数时,我们期望当损失最小时,模型的性能应当是最大化的,因此损失函数的构建是有讲究的,不是随意构造的。训练模型的目标就是让损失值尽可能小。
交叉熵损失函数
对于分类问题(如 MNIST 中的 10 个数字),最常用的损失函数是 交叉熵损失 (Cross-Entropy Loss)。交叉熵损失可以衡量模型输出的概率分布与真实标签之间的差异,换句话说,交叉熵取最小值 0 当且仅当模型的预测概率分布完全匹配真实标签的 one‑hot 分布。
模型最后一层输出的是对每个类别的“得分”(logits),经过 Softmax 函数后变成概率分布 ,其中 , 表示模型对第 个类别的预测概率。真实标签是一个 one‑hot 向量,例如对于数字 3,。交叉熵的计算公式为
因为只有一个 ,其余为 0,所以上式等价于
即模型对正确类别的预测概率越高,损失越小。例如,若模型对正确类别的预测概率为 0.99,则 ;若只有 0.1,则损失约为 2.30,惩罚显著增大。
在 PyTorch 中的使用
nn.CrossEntropyLoss 内部自动完成了 Softmax + 负对数似然计算,因此模型的最后一层不需要额外加 Softmax 激活函数,直接输出原始分数(logits)即可。它的输入形状通常为 (batch_size, num_classes),目标形状为 (batch_size,)(包含每个样本的真实类别索引)。
反向传播 (Backpropagation)
有了损失值,我们需要知道每个模型参数对损失的贡献程度,即损失关于参数的偏导数(梯度)。对于包含数百万参数的深度网络,直接解析求导不可行,数值方法求导数的结果既不精准,也不好求。为了精确求出损失函数对参数的梯度,反向传播算法被提出,利用链式法则高效地计算所有梯度。
链式法则的简单例子
假设网络为 ,则梯度
在神经网络中,损失 关于第 层参数 的梯度可以表示为
其中 是第 层的输出。反向传播从输出层开始,逐层向前计算梯度,并将梯度值存储在每一层参数的 .grad 属性中。
PyTorch 的自动微分
PyTorch 通过构建计算图来记录张量上的所有操作。当在张量上调用 .backward() 时,它会沿着计算图反向传播,自动计算出所有 requires_grad=True 的张量的梯度。例如:
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = (x ** 2).sum()
y.backward()
print(x.grad) # 输出 tensor([2., 4.]),即 dy/dx = 2x在我们的训练代码中,loss.backward() 会计算模型中所有可学习参数(fc1.weight, fc1.bias 等)的梯度,并累加到各自的 .grad 属性中。
优化器 (Optimizer)
优化器根据计算出的梯度来更新模型参数,使得损失值逐渐下降。最基本的更新规则是随机梯度下降 (Stochastic Gradient Descent, SGD)
其中 是参数, 是学习率, 是当前损失关于参数的梯度。
SGD 的改进变体
在实际训练中,原始 SGD 可能存在收敛慢、震荡等问题,因此出现了多种改进算法
| 优化器 | 特点 | 适用场景 |
|---|---|---|
| SGD + Momentum | 引入动量项,加速收敛并减少震荡 | 大多数任务的基础选择 |
| Adam | 自适应学习率,对超参数较鲁棒,收敛快 | 大规模数据/复杂网络,但泛化性有时不如 SGD |
| AdamW | 修正了 Adam 的权重衰减实现,更稳定 | 当前大参数量的主流模型的首选 |
在之前的 MNIST 示例中,我们使用了 optim.SGD(model.parameters(), lr=0.01, momentum=0.9)。这里的 momentum=0.9 表示使用了动量 SGD,可以理解为给参数更新加入了一个“惯性”,帮助模型跨越局部极小点。
优化器使用流程
- 清零梯度:
optimizer.zero_grad()
因为梯度是累加的,每个 batch 前必须清零,否则会累积上个 batch 的梯度。 - 反向传播:
loss.backward()
计算当前 batch 下的梯度。 - 参数更新:
optimizer.step()
根据优化算法更新参数。
练习——搭建 LeNet-5 模型并训练 CIFAR-10 数据集
背景知识
卷积神经网络
卷积神经网络 (Convolutional Neural Network, CNN) 是专为处理图像数据而设计的深度学习架构,其核心灵感源自生物视觉系统对局部信息的感知机制。不同于传统的全连接网络,CNN 利用卷积核 (Filter) 在输入图像上滑动并执行局部加权求和的卷积操作,生成特征图 (Feature Map),从而高效地提取从边缘、纹理到复杂语义的层次化特征;同时,通过引入池化层 (Pooling Layer) 进行下采样,不仅大幅降低了计算复杂度与参数量,还赋予了模型关键的平移不变性,使其能够忽略物体位置的变化而稳定识别目标。这种“局部连接”、“权值共享”与“层次化特征提取”的结合,让 CNN 成功解决了高维图像数据的特征表示难题,成为计算机视觉领域最经典且强大的基石模型。
卷积层 (Convolutional Layer) 是卷积神经网络提取特征的核心组件,也就是实现利用卷积核在输入图像上滑动并执行局部加权求和的操作的部分。给定一张图像 ,和一个卷积核 ,以及偏置向量 ,经过卷积操作之后得到的特征图像的数学化表示为
其中 表示卷积操作, 操作用到了广播机制 (Broadcast),、 和 分别表示输出特征图的高度、宽度和通道数。
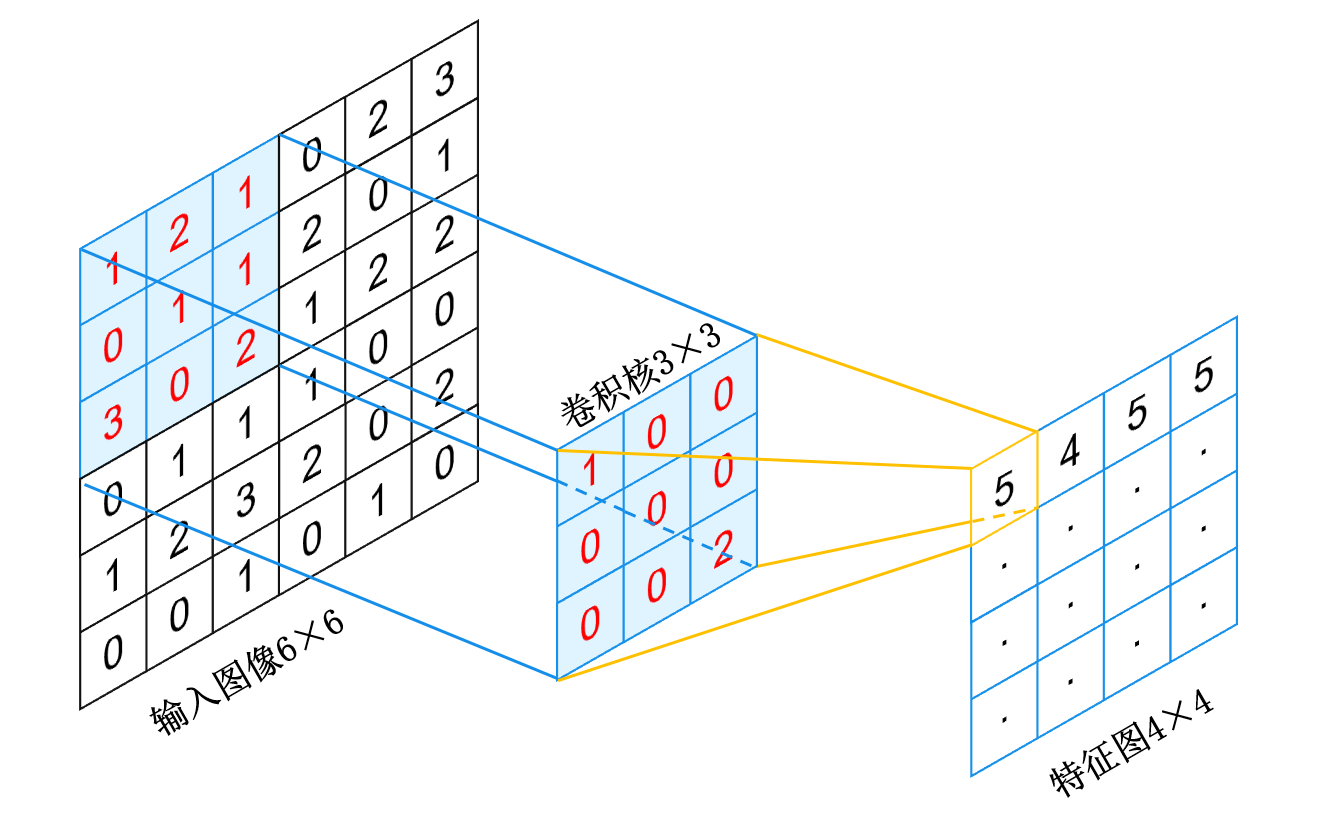
此外,为了提升提取特征的能力,卷积层通常会使用多个卷积核来提取不同类型的特征,这些卷积核的输出会被堆叠在一起形成多通道的特征图。卷积层还可以通过调整卷积核的大小、步长 (stride) 和填充 (padding) 来控制输出特征图的尺寸和感受野大小,从而更好地适应不同规模和复杂度的图像数据。
在 PyTorch 中,上述卷积可以用二维卷积模块 nn.Conv2d 来实现:
conv_layer = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5, stride=1, padding=0)这表明该卷积层接受 3 通道的输入图像,使用 6 个卷积核 (也就是输出的通道数),每个卷积核的大小为 5×5,步长为 1,且不使用填充。
当指定卷积层的输入通道数、输出通道数和卷积核大小后,给定输入图像的尺寸,卷积层的输出特征图的尺寸可以通过以下公式计算:
其中 、 和 分别表示输入图像的高度、宽度和通道数, 表示填充大小, 和 表示卷积核的高度和宽度, 表示步长。
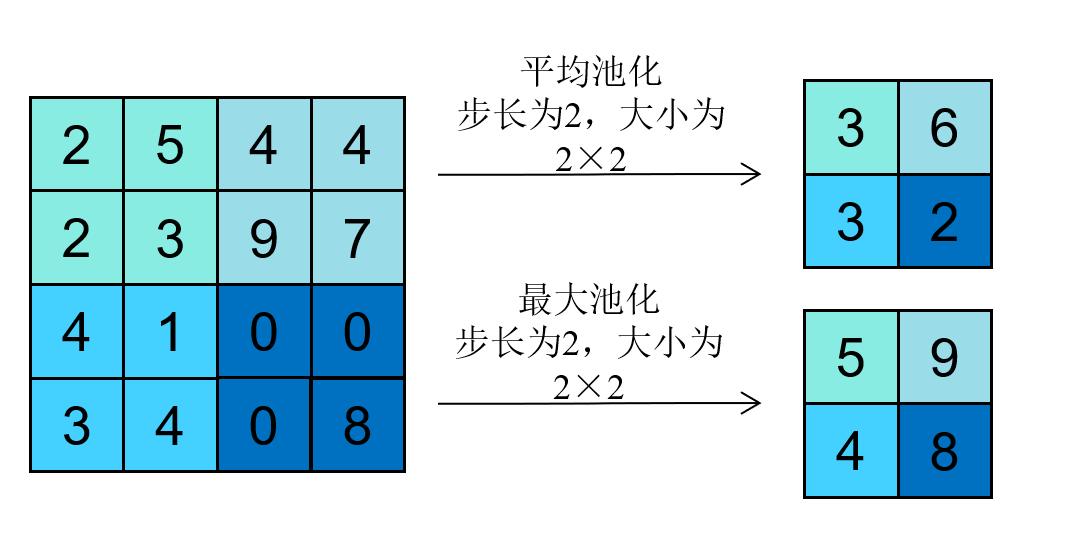
池化层
池化层是卷积神经网络中的另一个重要组件,主要用于对特征图进行下采样,从而减少特征图的尺寸和参数量,同时增强模型的平移不变性。池化层通过在输入特征图上滑动一个固定大小的窗口,并在窗口内执行某种聚合操作(如最大值或平均值)来生成输出特征图。例如,最大池化层 (Max Pooling) 会在每个窗口内取最大值作为输出,而平均池化层 (Average Pooling) 则会计算窗口内所有值的平均值作为输出。池化层的输出尺寸可以通过以下公式计算:
其中 、 和 分别表示输入特征图的高度、宽度和通道数, 和 表示池化窗口的高度和宽度, 表示步长, 表示填充大小。其实计算公式和卷积层的输出尺寸计算公式是一样的,因为池化层本质上也是一种特殊的卷积操作,只不过它的卷积核是固定的,并且没有可学习的参数。一般池化的步长会设置为和池化窗口的大小相同,这样就不会有重叠的窗口,从而实现对特征图的有效下采样。
LeNet-5 模型结构
LeNet-5 是一个经典的卷积神经网络,由 Yann LeCun 提出,主要用于手写数字识别。这里将这个经典模型稍加修改,使之适配 CIFAR-10 数据集的输入尺寸和通道数。改进后的 LeNet-5 模型结构如图所示。
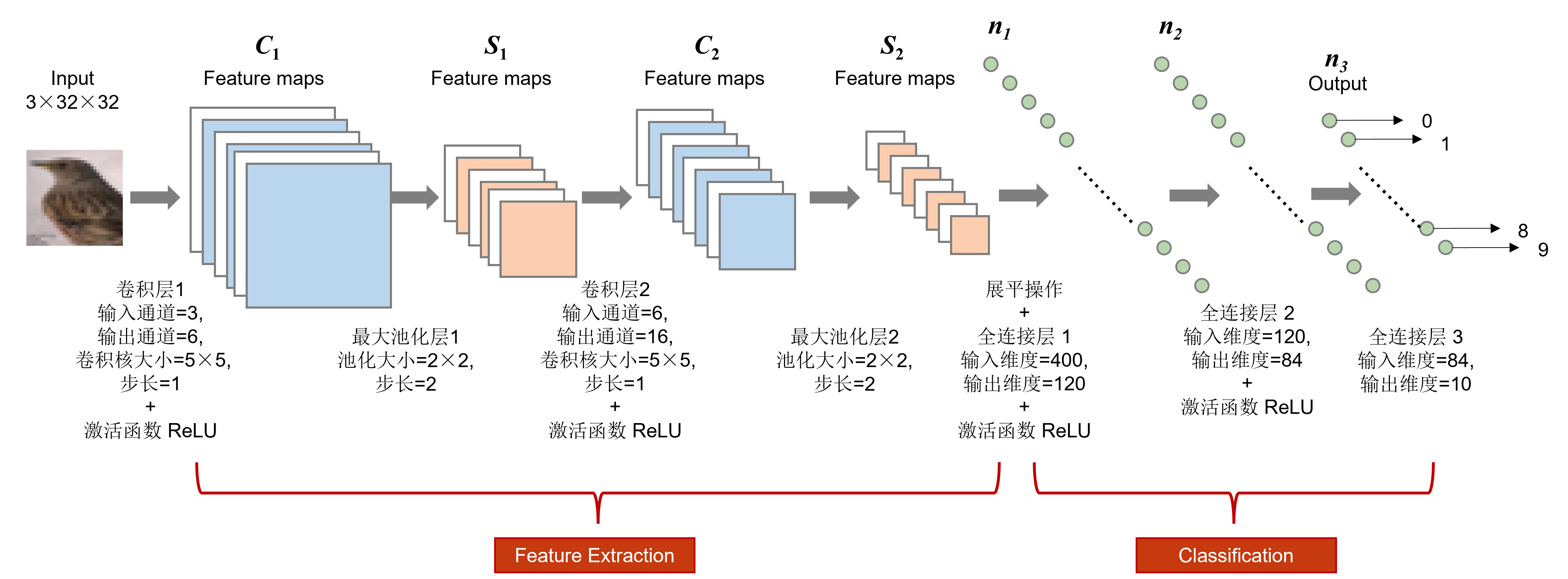
该模型的具体结构可以用如下 PyTorch 代码来描述:
- 卷积层:
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) - 池化层:
nn.MaxPool2d(kernel_size, stride)或者nn.AvgPool2d(kernel_size, stride) - 展平操作:
x.view(-1, num_features)或者nn.Flatten()
CIFAR-10 数据集
CIFAR-10 数据集包含 10 个类别的彩色图像:
- 飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车
- 每张图片大小为 32×32 像素,3 个颜色通道
- 训练集:50,000 张图像
- 测试集:10,000 张图像
练习任务
- 任务一:根据网络结构图搭建 LeNet-5 模型
- 任务二:加载 CIFAR-10 数据集。这里使用 PyTorch 的
torchvision.datasets.CIFAR10加载数据集,并进行适当的数据增强和归一化。 - 任务三:训练与评估
- 使用训练集训练 LeNet-5 模型
- 在测试集上评估模型性能
- 记录训练过程中的损失和准确率
练习部分的代码可以在 exercise.py 中找到
更多参考资料
深度学习基础
图像分类任务
卷积部分
优化器部分
损失函数部分
更多神经网络架构
仓库地址