在优化问题中,我们经常需要在满足若干约束条件的前提下,寻找目标函数的极值。典型形式是:
x∈Rnmins.t.f(x)gi(x)=0,i=1,…,m.直接在可行域内搜索往往困难——可行域可能非常复杂。拉格朗日乘子法提供了一种将约束”合并”到目标函数中的技巧,使问题转化为无约束优化,便于求解。
Lagrangian 乘子法#
引入乘子(Lagrange multipliers)λ=(λ1,…,λm),构造拉格朗日函数:
L(x,λ)=f(x)−i=1∑mλigi(x).然后,在 Rn+m 空间中同时对 (x,λ) 求偏导数,得到一阶条件(驻点条件):
{∇xL(x,λ)=∇f(x)−∑i=1mλi∇gi(x)=0,∇λL(x,λ)=−(g1(x),…,gm(x))⊤=0.简化为:
- ∇f(x)=∑i=1mλi∇gi(x)
- gi(x)=0,i=1,…,m
在满足这些条件的 (x∗,λ∗) 处,x∗ 是目标函数 f(x) 在约束集上的驻点(可能是极小点、极大点或鞍点)。为找到最小值点,可采用以下方法:
- 将求得的各个 x∗ 代入原函数 f(x),计算函数值并比较,确定全局最小值点。
- 理论上,满足约束优化问题的驻点 (x∗,λ∗) 必定是对偶问题 maxλminxL(x,λ) 的解。
理论解释#
- 直观理解:乘子 λi 表示第 i 个约束对目标函数在最优点处的”边际影响力”。
- 等价性:若 f 与每个 gi 在解附近足够光滑,且 ∇g1,…,∇gm 在解处线性无关,则解必为上述驻点之一。
- 必要性:在约束极值点处,目标函数梯度必须在约束集的切空间内——即与切空间正交的向量(约束梯度)能线性组合出目标梯度。
- 最优性判定:通过拉格朗日函数的海森矩阵在可行方向上的正定性/负定性可判断局部极值性质。
为什么最优解一定满足 ∇f(x∗)=∑i=1mλi∇gi(x∗)?#
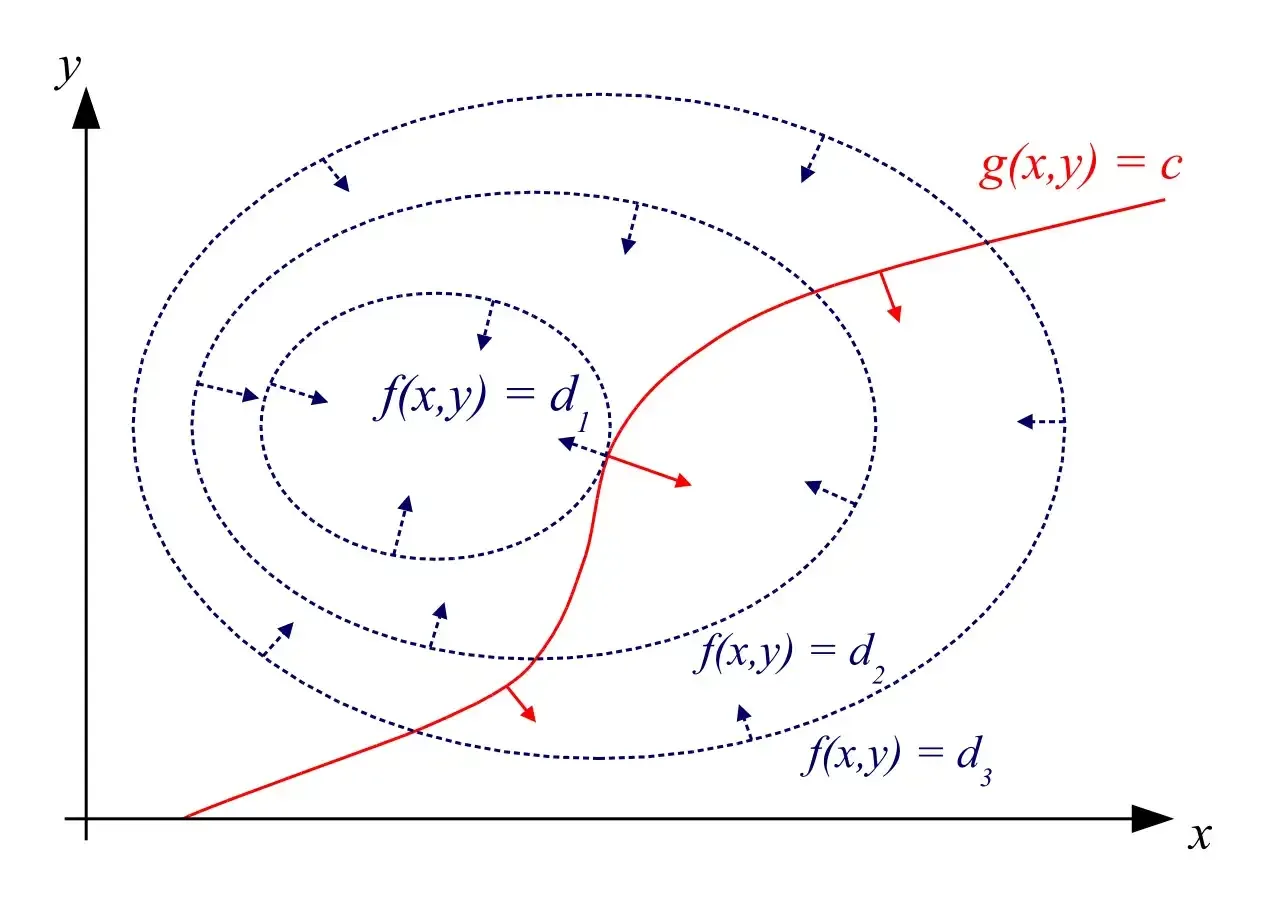
这个条件的另一层含义就是在 x∗ 处,目标函数 f(x) 与约束函数 gi(x) 的线性组合后的曲线相切。设想极值点不在相切的位置取到,而在图中某处等高线与约束线相交的点。好,沿着约束曲线向前走一点,目标函数值就会继续下降,这就说明了 x∗ 不是极值点。因此,必须等高线与约束线相切,才能保证 x∗ 是极值点。
KKT 条件(Karush–Kuhn–Tucker)#
当问题含有不等式约束时,拉格朗日乘子法推广为KKT条件:
xmins.t.f(x)gi(x)=0,i=1,…,m,hj(x)≤0,j=1,…,p.对应的KKT拉格朗日函数形式为:
L(x,λ,μ)=f(x)−i=1∑mλigi(x)+j=1∑pμjhj(x)存在乘子 λi(等式)与 μj≥0(不等式),使得:
- 可行性:gi(x∗)=0,hj(x∗)≤0
- 驻点条件:∇f(x∗)=∑iλi∇gi(x∗)+∑jμj∇hj(x∗)
- 互补松弛:μjhj(x∗)=0,j=1,…,p
- 乘子非负性:μj≥0
在凸优化问题中,这些条件不仅必要,而且充分。
实例:约束最小二乘#
问题:
x∈R2min21∥x∥2,s.t. x1+2x2−3=0.构造拉格朗日函数:
L(x,λ)=21(x12+x22)−λ(x1+2x2−3).求解一阶条件:
⎩⎨⎧∇x1L=x1−λ=0⇒x1=λ,∇x2L=x2−2λ=0⇒x2=2λ,∇λL=−(x1+2x2−3)=0⇒λ+2(2λ)−3=0.解得 5λ=3,故 λ=3/5,进而
x∗=(53,56).代入原函数可验证此为全局最优解。
对偶问题#
考虑一般约束优化问题:
x∈Rnmins.t.f(x)gi(x)=0,i=1,…,m,hj(x)≤0,j=1,…,p.构造拉格朗日函数,引入乘子 λi∈R 和 μj≥0:
L(x,λ,μ)=f(x)−i=1∑mλigi(x)+j=1∑pμjhj(x)注意:对不等式约束使用 + 号,确保违背约束时(hj(x)>0),惩罚项 μjhj(x) 可通过增大 μj 使惩罚达到 +∞。
定义对偶函数:
q(λ,μ)=xminL(x,λ,μ)对偶函数的特性:
- 对给定的乘子 λ,μ,q(λ,μ) 是拉格朗日函数关于 x 的最小值
- 若 μj<0,则约定 q(λ,μ)=−∞
- 对任何满足约束的 x∗,若 μ≥0,则 q(λ,μ)≤f(x∗)
由此定义对偶问题:
λ,μmaxq(λ,μ)subject to μj≥0,j=1,…,p对偶问题的最优值必定不大于原始问题的最优值,这称为弱对偶性。在特定条件下(如凸优化问题),还可能成立强对偶性。
利用对偶性求解原始问题#
对偶问题不仅提供了原始问题最优值的下界,在满足强对偶性条件时,还可以用于求解原始问题:
解对偶问题:求解 maxλ,μ≥0q(λ,μ),得到最优对偶变量 (λ∗,μ∗)。
从对偶恢复原始解:当原始问题为凸问题且满足Slater条件(存在严格可行点)时,我们可以:
- 若对偶函数 q(λ∗,μ∗) 在某点 x∗ 取得最小值,则 x∗ 即为原始问题的最优解
- 通过求解方程 ∇xL(x,λ∗,μ∗)=0 得到原始问题的最优解 x∗
互补松弛性质:在最优点处,μj∗hj(x∗)=0 提供了关于活跃约束的重要信息:
- 若 μj∗>0,则必有 hj(x∗)=0(约束紧绷)
- 若 hj(x∗)<0,则必有 μj∗=0(约束不起作用)
这种方法在某些情况下比直接求解原始问题更有效,特别是当对偶问题结构更简单或维度更低时。

