

前序工作
基本介绍
SAM2 (Segment Anything Model 2) 是 Meta AI 研究院开发的一款强大的图像分割模型,能够在各种图像上进行高效的分割任务。
Okay, clone 完项目的代码后,在 README.md 中可以看到 SAM2 的基本结构图。
模型结构
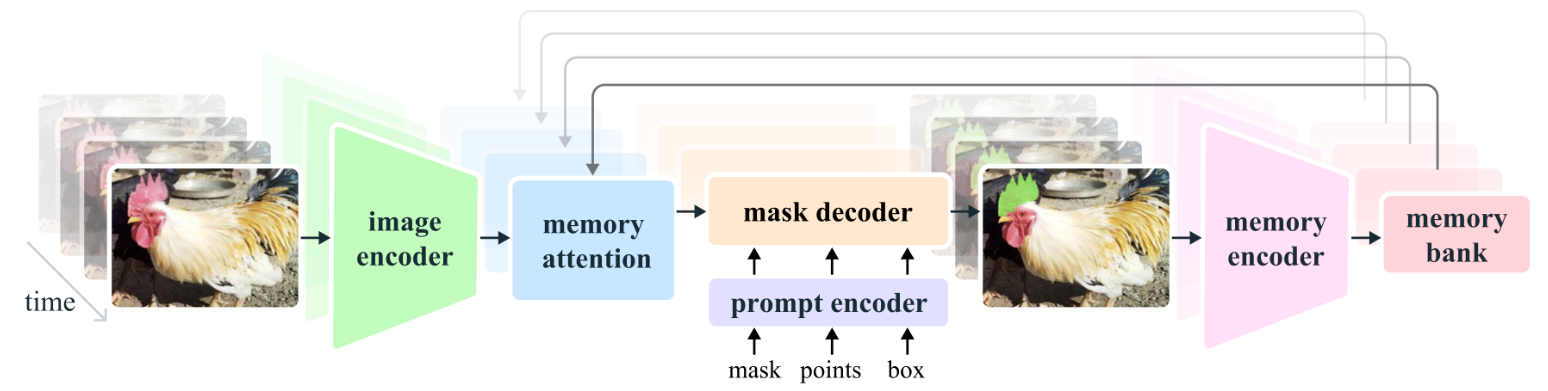
README.md 中是这样介绍 SAM2 的:
Segment Anything Model 2 (SAM 2) is a foundation model towards solving promptable visual segmentation in images and videos. We extend SAM to video by considering images as a video with a single frame. The model design is a simple transformer architecture with streaming memory for real-time video processing. We build a model-in-the-loop data engine, which improves model and data via user interaction, to collect our SA-V dataset, the largest video segmentation dataset to date. SAM 2 trained on our data provides strong performance across a wide range of tasks and visual domains.
可以看出 SAM2 相较于 SAM 的主要改进在于其引入了一个流式内存(记忆)机制,使其能够更高效地处理视频数据。
配置环境
参考 README.md 中的说明,作如下配置
conda create -n sam2 python=3.12 -y
conda activate sam2
cd sam2
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu124
pip install -e .
pip install -e ".[notebooks]"预训练模型下载
官方的预训练模型有 SAM2 和 SAM2.1 两个版本,其中 SAM 2.1 是 SAM 2 的全面升级版,在训练的时候引入了额外的数据增强技术,因此 SAM 2.1 更加适合处理复杂场景(遮挡、小物体、低光照)。下面两个是官方提供的预训练模型的性能对比表格:
| Model | Size (M) | Speed (FPS) | SA-V test (J&F) | MOSE val (J&F) | LVOS v2 (J&F) |
|---|---|---|---|---|---|
| sam2.1_hiera_tiny (config, checkpoint) | 38.9 | 91.2 | 76.5 | 71.8 | 77.3 |
| sam2.1_hiera_small (config, checkpoint) | 46 | 84.8 | 76.6 | 73.5 | 78.3 |
| sam2.1_hiera_base_plus (config, checkpoint) | 80.8 | 64.1 | 78.2 | 73.7 | 78.2 |
| sam2.1_hiera_large (config, checkpoint) | 224.4 | 39.5 | 79.5 | 74.6 | 80.6 |
| Model | Size (M) | Speed (FPS) | SA-V test (J&F) | MOSE val (J&F) | LVOS v2 (J&F) |
|---|---|---|---|---|---|
| sam2_hiera_tiny (config, checkpoint) | 38.9 | 91.5 | 75.0 | 70.9 | 75.3 |
| sam2_hiera_small (config, checkpoint) | 46 | 85.6 | 74.9 | 71.5 | 76.4 |
| sam2_hiera_base_plus (config, checkpoint) | 80.8 | 64.8 | 74.7 | 72.8 | 75.8 |
| sam2_hiera_large (config, checkpoint) | 224.4 | 39.7 | 76.0 | 74.6 | 79.8 |
官方使用接口
模型加载
官方提供了 build_sam2 函数来加载预训练模型。和 SAM 不同,这次不是用字典做映射,而是需要提供模型的配置文件路径和权重文件路径来加载模型:
from sam2.build_sam import build_sam2
ckpt_path = "your/path/to/sam2.1_hiera_tiny.pt"
model_cfg_path = "your/path/to/sam2.1_hiera_t.yaml"
sam2_model = build_sam2(model_cfg_path, ckpt_path)SAM2ImagePredictor 类
从模型权重加载
SAM2ImagePredictor 类是 SAM2 中用于进行图像分割预测的核心类。它提供了一个简单的接口来处理输入图像和生成分割掩码。类似 SAM 中的 SamPredictor,SAM2 的 SAM2ImagePredictor 也接受多种类型的输入提示(点、框、掩码等),并返回分割结果:
import torch
from sam2.sam2_image_predictor import SAM2ImagePredictor
predictor = SAM2ImagePredictor(sam2_model)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(img) # img 是一个 np.ndarray 对象
masks, iou_predictions, low_res_masks = predictor.predict(mask_input=None, point_coords=np.array([[1280, 720]]), point_labels=np.array([1]), multimask_output=False)同样地:
masks: 生成的分割掩码,形状为(num_masks, height, width),每个掩码是一个二值图像,表示对应区域的分割结果。iou_predictions: 每个掩码的 IoU 预测值,形状为(num_masks,),表示每个掩码与真实分割的重叠程度。low_res_masks: 低分辨率的掩码,形状为(num_masks, low_res_height, low_res_width),每个掩码是一个较小尺寸的掩码 logits,可以作为下一次预测的mask_input用于迭代细化。mask_input: 这是一个可选的输入参数,可以是一个低分辨率的掩码,形状为(low_res_height, low_res_width),用于提供先前预测的掩码信息,以帮助模型进行迭代细化。point_coords: 这是一个可选的输入参数,形状为(num_points, 2),表示用户提供的点坐标,每个点由 (x, y) 坐标组成。point_labels: 这是一个可选的输入参数,形状为(num_points,),表示每个点的标签,通常为 1(正样本)或 0(负样本),用于指导模型进行分割。box: 这是一个可选的输入参数,形状为(4,),表示用户提供的边界框坐标,格式为 (x_min, y_min, x_max, y_max),用于指导模型进行分割。multimask_output: 这是一个布尔参数,表示是否返回多个掩码结果。如果设置为True,模型将返回多个分割掩码,以提供更多的分割选项;如果设置为False,模型将返回一个最佳的分割掩码。
上述代码中用到了 torch.inference_mode() 和 torch.autocast("cuda", dtype=torch.bfloat16) 来优化推理性能,特别是在使用 GPU 时,可以显著提高推理速度和减少内存占用。
torch.inference_mode(): 这是 PyTorch 中的一种上下文管理器,用于在推理阶段禁用梯度计算和其他与训练相关的功能,从而提高推理效率。相较于torch.no_grad(),torch.inference_mode()完全禁用视图追踪,且完全关闭整个 autograd 系统,因此它的内存开销更低,是对推理性能的极致优化。bfloat16(BF16) 和float16(FP16) 都是半精度浮点数格式,但它们在表示范围和精度方面有所不同。BF16 具有与 FP32 相同的指数位数(8 位),但只有 7 位的尾数,这使得它能够表示更大的数值范围,同时在某些情况下提供更好的数值稳定性。FP16 则具有 5 位的指数和 10 位的尾数,适用于需要更高精度的场景,但可能会遇到数值溢出或下溢的问题。BF16 相较于 FP16 在深度学习中的应用更广泛,因为数值范围比数值精度对模型推理结果的影响更大。
从 huggingface 上加载
SAM2ImagePredictor 类还提供了一个 from_pretrained 的类方法,可以直接从 Hugging Face 上加载预训练的 SAM2 模型权重,简化了模型加载的过程:
import torch
from sam2.sam2_image_predictor import SAM2ImagePredictor
predictor = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(img)
masks, iou_predictions, low_res_masks = predictor.predict(mask_input=None, point_coords=np.array([[1280, 720]]), point_labels=np.array([1]), multimask_output=False)build_sam2_video_predictor 函数
build_sam2_video_predictor 函数是 SAM2 中用于构建视频分割预测器的函数。它接受一个预训练的 SAM2 模型作为输入,并返回一个 SAM2VideoPredictor 对象,该对象可以用于处理视频数据并生成分割结果:
import torch
import numpy as np
import cv2
from sam2.build_sam import build_sam2_video_predictor
# 1. 模型权重和配置路径
ckpt_path = "your/path/to/sam2.1_hiera_tiny.pt"
model_cfg_path = "your/path/to/sam2.1_hiera_t.yaml"
# 2. 构建视频预测器
predictor = build_sam2_video_predictor(model_cfg_path, ckpt_path)
# 3. 初始化推理状态(直接传入 MP4 视频路径)
video_path = r"your/video/path.mp4"
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
inference_state = predictor.init_state(
video_path=video_path,
offload_video_to_cpu=False, # False: 帧加载到 GPU, True: 帧加载到 CPU 节省显存
)
# 4. 添加 prompt(例如:在第 0 帧添加一个正样本点)
ann_frame_idx = 0 # 交互的帧索引
ann_obj_id = 1 # 物体 ID(任意唯一整数)
# 添加一个正样本点击 (x, y) = (210, 350),label=1 表示正样本
points = np.array([[210, 350]], dtype=np.float32)
labels = np.array([1], np.int32)
_, out_obj_ids, out_mask_logits = predictor.add_new_points_or_box(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=ann_obj_id,
points=points,
labels=labels,
)
# 5. 传播到整个视频
video_segments = {}
for out_frame_idx, out_obj_ids, out_mask_logits in predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}
print(f"处理完成!共处理 {len(video_segments)} 帧")
# 6. 可视化并保存视频
output_video_path = "your/output/video/path.mp4"
cap = cv2.VideoCapture(video_path)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_video_path, fourcc, fps, (width, height))
frame_idx = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if frame_idx in video_segments:
# 获取当前帧的所有掩码
for obj_id, mask in video_segments[frame_idx].items():
# mask 的形状通常是 (1, H, W) 或 (H, W)
mask = mask.squeeze()
# 创建一个彩色叠加层 (例如 蓝色)
color_mask = np.zeros_like(frame, dtype=np.uint8)
color_mask[mask] = [255, 0, 0] # BGR: Blue
# 叠加到原图
frame = cv2.addWeighted(frame, 1.0, color_mask, 0.5, 0)
# 可选:绘制掩码轮廓
contours, _ = cv2.findContours(mask.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(frame, contours, -1, (255, 255, 255), 2)
out.write(frame)
frame_idx += 1
cap.release()
out.release()
print(f"可视化视频已保存至: {output_video_path}")从视频的结果可以看出,SAM2 的分割是追踪 prompts 所提示的物体的,因此在视频中同一物体的分割结果是连续的,且能够适应物体的形变和运动。例如,如果下一帧中这个物体消失了,可能会导致后续所有帧中都没有分割内容了。
SAM2VideoPredictor 类
SAM2VideoPredictor 类就是前面 build_sam2_video_predictor 函数返回的对象,它提供了一个接口来处理视频数据并生成分割结果。它的使用方式与前面介绍的 SAM2ImagePredictor 类类似,但它专门针对视频数据进行了优化,能够处理视频中的连续帧,并且支持在视频中添加交互式提示(如点、框等)来指导分割过程。
很遗憾地是,官方给出的接口并不能像 SAM2ImagePredictor 那样直接自行从模型权重加载,而是需要通过 build_sam2_video_predictor 函数来构建视频预测器对象。
但是,官方提供了使用 hugginface 权重加载的方式:
import torch
from sam2.sam2_video_predictor import SAM2VideoPredictor
predictor = SAM2VideoPredictor.from_pretrained("facebook/sam2-hiera-large")
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and instantly get the output on the same frame
frame_idx, object_ids, masks = predictor.add_new_points_or_box(
state,
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=ann_obj_id,
points=points,
labels=labels
)
# propagate the prompts to get masklets throughout the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}SAM2AutomaticMaskGenerator 类
类似 SAM 的 SAMAutomaticMaskGenerator,SAM2AutomaticMaskGenerator 是 SAM2 提供的全自动实例分割工具,无需任何人工提示,即可在单张图像上自动检测并分割出所有可能的物体对象。
from sam2.build_sam import build_sam2
from sam2.automatic_mask_generator import SAM2AutomaticMaskGenerator
# 加载模型
sam2_model = build_sam2("configs/sam2.1/sam2.1_hiera_l.yaml", "checkpoints/sam2.1_hiera_large.pt")
# 初始化自动掩码生成器
mask_generator = SAM2AutomaticMaskGenerator(sam2_model)
# 生成所有掩码
masks = mask_generator.generate(image)
# masks 是一个列表,每个元素包含 segmentation, bbox, area, predicted_iou 等字段SAM2 接口文档
本文档基于 SAM2 模型部分源码,逐项记录 11 个核心类:SAM2Base、SAM2VideoPredictor、SAM2ImagePredictor、PositionEmbeddingSine、MemoryEncoder、MemoryAttentionLayer、MemoryAttention、ImageEncoder、MaskDecoder、PromptEncoder、Hiera。 包含:关键属性、全部方法(含 _ 私有方法)、每个方法的职责与核心输入输出,以及详细的形状说明。
SAM2Base
文件路径: sam2/modeling/sam2_base.py
类作用: SAM2 模型的基础类,负责图像编码、记忆融合、SAM 头预测和记忆编码的核心流程。它集成了图像主干网络、记忆注意力机制、记忆编码器以及 SAM 的提示编码器和掩码解码器,是视频目标跟踪的核心模型。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
image_encoder | nn.Module | 无 | 图像主干网络,提取多尺度视觉特征 |
memory_attention | nn.Module | 无 | 记忆注意力模块,融合当前帧特征与历史记忆 |
memory_encoder | nn.Module | 无 | 记忆编码器,将当前预测掩码编码为记忆特征 |
num_maskmem | int | 7 | 可访问的记忆数量(1个输入帧 + 6个历史帧) |
image_size | int | 512 | 输入图像尺寸 |
backbone_stride | int | 16 | 图像主干输出步长 |
use_high_res_features_in_sam | bool | False | 是否在 SAM 解码器中使用高分辨率特征 |
num_feature_levels | int | 1 或 3 | 特征金字塔层数(高分辨率时为3) |
use_obj_ptrs_in_encoder | bool | False | 是否在编码器中交叉注意力对象指针 |
max_obj_ptrs_in_encoder | int | 16 | 编码器中最大对象指针数 |
maskmem_tpos_enc | nn.Parameter | (num_maskmem,1,1,mem_dim) | 记忆的时间位置编码 |
no_mem_embed | nn.Parameter | (1,1,hidden_dim) | 无记忆嵌入(用于第一帧) |
no_mem_pos_enc | nn.Parameter | (1,1,hidden_dim) | 无记忆位置编码 |
directly_add_no_mem_embed | bool | False | 是否直接将无记忆嵌入加到特征上 |
sam_prompt_encoder | PromptEncoder | 无 | SAM 提示编码器 |
sam_mask_decoder | MaskDecoder | 无 | SAM 掩码解码器 |
obj_ptr_proj | nn.Module | nn.Identity 或线性层 | 对象指针投影层 |
obj_ptr_tpos_proj | nn.Module | nn.Identity 或线性层 | 对象指针时间位置编码投影 |
hidden_dim | int | 图像编码器 neck.d_model | 隐藏层维度 |
mem_dim | int | hidden_dim | 记忆特征维度 |
sigmoid_scale_for_mem_enc | float | 1.0 | 记忆编码前掩码 sigmoid 的缩放因子 |
sigmoid_bias_for_mem_enc | float | 0.0 | 记忆编码前掩码 sigmoid 的偏置因子 |
binarize_mask_from_pts_for_mem_enc | bool | False | 是否对点提示产生的掩码进行二值化 |
use_mask_input_as_output_without_sam | bool | False | 是否直接使用输入掩码作为输出(跳过 SAM) |
max_cond_frames_in_attn | int | -1 | 注意力中最大条件帧数(-1 表示无限制) |
multimask_output_in_sam | bool | False | 是否在 SAM 中输出多掩码 |
multimask_min_pt_num | int | 1 | 使用多掩码的最小点数 |
multimask_max_pt_num | int | 1 | 使用多掩码的最大点数 |
multimask_output_for_tracking | bool | False | 跟踪时是否使用多掩码输出 |
use_multimask_token_for_obj_ptr | bool | False | 是否使用多掩码 token 生成对象指针 |
iou_prediction_use_sigmoid | bool | False | 是否使用 sigmoid 限制 IoU 预测到 [0,1] |
memory_temporal_stride_for_eval | int | 1 | 评估时记忆库的时间步长 |
non_overlap_masks_for_mem_enc | bool | False | 记忆编码时是否应用非重叠约束 |
add_tpos_enc_to_obj_ptrs | bool | True | 是否给对象指针添加时间位置编码 |
proj_tpos_enc_in_obj_ptrs | bool | False | 是否投影对象指针的时间位置编码 |
use_signed_tpos_enc_to_obj_ptrs | bool | False | 是否使用有符号时间位置编码 |
only_obj_ptrs_in_the_past_for_eval | bool | False | 评估时是否只关注过去的对象指针 |
pred_obj_scores | bool | False | 是否预测对象出现分数 |
pred_obj_scores_mlp | bool | False | 是否使用 MLP 预测对象分数 |
fixed_no_obj_ptr | bool | False | 是否使用固定的无对象指针 |
soft_no_obj_ptr | bool | False | 是否使用软无对象指针(混合) |
use_mlp_for_obj_ptr_proj | bool | False | 是否使用 MLP 投影对象指针 |
no_obj_embed_spatial | nn.Parameter 或 None | None | 空间无对象嵌入 |
sam_mask_decoder_extra_args | dict 或 None | None | SAM 掩码解码器额外参数 |
compile_image_encoder | bool | False | 是否编译图像编码器 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | 参见上方属性列表(共 46 个参数) | 无 | 初始化整个模型,构建图像主干、记忆注意力、记忆编码器、SAM 头部等组件 |
device (property) | 无 | torch.device | 返回模型参数所在的设备 |
forward | *args, **kwargs | NotImplementedError | 占位方法,提示使用 SAM2VideoPredictor 进行推理 |
_build_sam_heads | 无 | 无 | 构建 SAM 提示编码器和掩码解码器,初始化对象指针投影层 |
_forward_sam_heads | backbone_features: [B, C, H, W]point_inputs: dict (point_coords: [B, P, 2], point_labels: [B, P])mask_inputs: [B, 1, H*16, W*16]high_res_features: list([B, C, 4*H, 4*W], [B, C, 2*H, 2*W]) 或 Nonemultimask_output: bool | low_res_multimasks: [B, M, H*4, W*4]high_res_multimasks: [B, M, H*16, W*16]ious: [B, M]low_res_masks: [B, 1, H*4, W*4]high_res_masks: [B, 1, H*16, W*16]obj_ptr: [B, C]object_score_logits: [B, 1] | 前向传播 SAM 提示编码器和掩码解码器,生成掩码预测、IoU 估计和对象指针 |
_use_mask_as_output | backbone_features: [B, C, H, W]high_res_features: 同上或 Nonemask_inputs: [B, 1, H*16, W*16] | 同 _forward_sam_heads 的返回值 | 直接将二值掩码输入转换为输出掩码 logits(跳过 SAM 解码器) |
forward_image | img_batch: [B, 3, image_size, image_size] | backbone_out: dict (vision_features, vision_pos_enc, backbone_fpn) | 运行图像编码器,提取多尺度视觉特征和位置编码 |
_prepare_backbone_features | backbone_out: dict | backbone_out (copy), vision_feats: list([HW, B, C]), vision_pos_embeds: list([HW, B, C]), feat_sizes: list((H, W)) | 整理多尺度特征和位置编码,展平为 Transformer 使用的格式(HW x B x C) |
_prepare_memory_conditioned_features | frame_idx: intis_init_cond_frame: boolcurrent_vision_feats: list([HW, B, C])current_vision_pos_embeds: list([HW, B, C])feat_sizes: list((H, W))output_dict: dictnum_frames: inttrack_in_reverse: bool | pix_feat: [B, C, H, W] | 核心记忆融合:拼接条件/非条件记忆 + 可选对象指针,通过 memory_attention 得到当前帧融合特征 |
_encode_new_memory | current_vision_feats: list([HW, B, C])feat_sizes: list((H, W))pred_masks_high_res: [B, 1, H*16, W*16]object_score_logits: [B, 1]is_mask_from_pts: bool | maskmem_features: [B, C, H, W]maskmem_pos_enc: list([1, B, C, H, W]) | 将当前帧预测掩码与视觉特征编码为记忆特征和位置编码 |
_track_step | frame_idx: intis_init_cond_frame: boolcurrent_vision_feats: list([HW, B, C])current_vision_pos_embeds: list([HW, B, C])feat_sizes: list((H, W))point_inputs: dict 或 Nonemask_inputs: [B, 1, H*16, W*16] 或 Noneoutput_dict: dictnum_frames: inttrack_in_reverse: boolprev_sam_mask_logits: [B, 1, H*4, W*4] 或 None | current_out: dict (point_inputs, mask_inputs)sam_outputs: 同 _forward_sam_heads 返回值high_res_features: list 或 Nonepix_feat: [B, C, H, W] | 单帧内部跟踪流程:准备高分辨率特征 → 记忆融合 → SAM 头预测 |
_encode_memory_in_output | current_vision_feats: list([HW, B, C])feat_sizes: list((H, W))point_inputs: dict 或 Nonerun_mem_encoder: boolhigh_res_masks: [B, 1, H*16, W*16]object_score_logits: [B, 1]current_out: dict | 无(修改 current_out,添加 maskmem_features 和 maskmem_pos_enc) | 将记忆编码器的输出写入 current_out 字典 |
track_step | frame_idx: intis_init_cond_frame: boolcurrent_vision_feats: list([HW, B, C])current_vision_pos_embeds: list([HW, B, C])feat_sizes: list((H, W))point_inputs: dict 或 Nonemask_inputs: [B, 1, H*16, W*16] 或 Noneoutput_dict: dictnum_frames: inttrack_in_reverse: boolrun_mem_encoder: boolprev_sam_mask_logits: [B, 1, H*4, W*4] 或 None | current_out: dict (pred_masks, pred_masks_high_res, obj_ptr, object_score_logits, maskmem_features, maskmem_pos_enc) | 单帧公开跟踪入口,组合 _track_step + _encode_memory_in_output,写入预测掩码、对象指针等 |
_use_multimask | is_init_cond_frame: boolpoint_inputs: dict 或 None | multimask_output: bool | 根据交互点数和配置判断是否启用多掩码输出 |
_apply_non_overlapping_constraints | pred_masks: [B, 1, H, W] | pred_masks: [B, 1, H, W] | 对预测掩码应用非重叠约束:同像素只保留最高分对象,抑制对象间重叠 |
SAM2VideoPredictor
文件路径: sam2/sam2_video_predictor.py
类作用: 继承自 SAM2Base,负责视频推理的状态管理、用户交互处理和视频传播。它管理推理状态(图像缓存、对象映射、每对象输出字典),提供添加点/框/掩码提示、传播跟踪、清除提示等功能。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
fill_hole_area | int | 0 | 填充掩码中孔洞的面积阈值 |
non_overlap_masks | bool | False | 是否对输出对象掩码应用非重叠约束 |
clear_non_cond_mem_around_input | bool | False | 是否清除输入帧周围的非条件记忆(避免旧信息干扰) |
add_all_frames_to_correct_as_cond | bool | False | 是否将所有接收校正点击的帧添加到条件帧列表 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | fill_hole_area=0, non_overlap_masks=False, clear_non_cond_mem_around_input=False, add_all_frames_to_correct_as_cond=False, **kwargs | 无 | 初始化视频预测器,设置填充孔洞、非重叠掩码、清除记忆等选项 |
init_state | video_path: stroffload_video_to_cpu=Falseoffload_state_to_cpu=Falseasync_loading_frames=False | inference_state: dict | 初始化推理状态:加载视频帧、创建对象映射、缓存特征等 |
from_pretrained (classmethod) | model_id: str, **kwargs | SAM2VideoPredictor 实例 | 从预训练模型加载配置和权重创建预测器实例 |
_obj_id_to_idx | inference_state: dict, obj_id: int | obj_idx: int | 将外部对象 ID 转换为内部索引,必要时创建新对象槽位 |
_obj_idx_to_id | inference_state: dict, obj_idx: int | obj_id: int | 将内部索引转换为外部对象 ID |
_get_obj_num | inference_state: dict | int | 返回当前对象数量 |
add_new_points_or_box | inference_state: dict, frame_idx: int, obj_id: int, point_coords: [P, 2] 或 [[x1,y1,x2,y2]], point_labels: [P], is_box=False | video_res_masks: [1, H_vid, W_vid] | 在指定帧添加点或框提示,运行单帧推理,写入临时输出 |
add_new_points | *args, **kwargs | 同 add_new_points_or_box | 兼容旧接口,调用 add_new_points_or_box |
add_new_mask | inference_state: dict, frame_idx: int, obj_id: int, mask: [H_vid, W_vid] | video_res_masks: [1, H_vid, W_vid] | 在指定帧添加二值掩码作为提示,更新临时输出 |
_get_orig_video_res_output | inference_state: dict, any_res_masks: [B, 1, H, W] | video_res_masks: [B, 1, H_vid, W_vid] | 将掩码上采样回原始视频尺寸,并可施加非重叠约束 |
_consolidate_temp_output_across_obj | inference_state: dict, frame_idx: int, is_cond: bool, consolidate_at_video_res=False | consolidated_masks: [1, H, W] 或 [1, H_vid, W_vid] | 合并多对象临时输出到统一张量 |
propagate_in_video_preflight | inference_state: dict | 无(修改 inference_state) | 传播前整理:合并临时输出、必要时补跑记忆编码器、一致性校验 |
propagate_in_video | inference_state: dict, start_frame_idx=None, max_frame_num_to_track=None, reverse=False | 生成器返回 (frame_idx, obj_ids, video_res_masks) | 视频时序传播主循环,逐帧产生跟踪结果 |
clear_all_prompts_in_frame | inference_state: dict, frame_idx: int, obj_id: int, need_output=True | video_res_masks: [1, H_vid, W_vid] 或 None | 清理某对象某帧的所有提示,并返回更新后的掩码 |
reset_state | inference_state: dict | 无 | 全量重置推理状态和对象映射 |
_reset_tracking_results | inference_state: dict | 无 | 仅清空跟踪内容,不清理对象映射 |
_get_image_feature | inference_state: dict, frame_idx: int, batch_size: int | backbone_out: dict | 取缓存或计算当前帧特征,并扩展到对象 batch 维 |
_run_single_frame_inference | inference_state: dict, frame_idx: int, obj_id: int, point_inputs=None, mask_inputs=None, prev_sam_mask_logits=None, run_mem_encoder=True | current_out: dict | 单帧打包推理,返回紧凑输出结构 + GPU 掩码 |
_run_memory_encoder | inference_state: dict, frame_idx: int, obj_id: int, high_res_masks: [1, H*16, W*16] | 无(更新 inference_state 中的记忆特征) | 在给定高分辨率掩码下重新计算记忆特征 |
_get_maskmem_pos_enc | inference_state: dict, current_out: dict | maskmem_pos_enc: list([1, B, C, H, W]) | 缓存并按 batch 扩展记忆位置编码 |
remove_object | inference_state: dict, obj_id: int, strict=False, need_output=True | video_res_masks: [1, H_vid, W_vid] 或 None | 删除对象并重映射所有 per-object 容器 |
_clear_non_cond_mem_around_input | inference_state: dict, frame_idx: int | 无 | 清除输入帧附近的非条件记忆,避免旧信息干扰 |
SAM2ImagePredictor
文件路径: sam2/sam2_image_predictor.py
类作用: 用于单张图像的交互式分割预测器。它缓存图像嵌入,支持点、框、掩码提示,并返回分割掩码和 IoU 分数。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
model | SAM2Base | 无 | 底层 SAM2 模型 |
_transforms | ResizeLongestSide | 无 | 图像预处理变换 |
_is_image_set | bool | False | 是否已设置图像 |
_features | dict | None | 缓存的图像嵌入和高分辨率特征 |
_orig_hw | tuple | None | 原始图像高度和宽度 |
_is_batch | bool | False | 是否处于批处理模式 |
mask_threshold | float | 0.0 | 掩码二值化阈值 |
_bb_feat_sizes | list | None | 主干特征尺寸列表 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | model: SAM2Base, mask_threshold=0.0 | 无 | 初始化预测器,设置模型和掩码阈值 |
from_pretrained (classmethod) | model_id: str, **kwargs | SAM2ImagePredictor 实例 | 从预训练模型加载配置和权重创建预测器实例 |
set_image | image: [H, W, 3] numpy array | 无 | 单图编码并缓存嵌入 |
set_image_batch | image_list: list of [H, W, 3] numpy arrays | 无 | 多图编码并进入批处理模式 |
predict_batch | point_coords=None, point_labels=None, box=None, mask_logits=None, normalize_coords=True, img_idx=-1 | all_masks: list of [B, 1, H, W], all_ious: list of [B, 1], all_low_res_masks: list of [B, 1, H//4, W//4] | 对已缓存的批处理图像进行提示推理,返回所有图像的掩码和 IoU |
predict | point_coords=None, point_labels=None, box=None, mask_logits=None, multimask_output=False, return_logits=False | masks: [1, H, W], ious: [1], low_res_logits: [1, 256, 256] | 单图提示推理(numpy 输入/输出封装) |
_prep_prompts | point_coords, point_labels, box, mask_logits, normalize_coords, img_idx=-1 | point_coords: [B, P, 2], point_labels: [B, P], box: [B, 4] 或 None, mask_logits: [B, 1, 256, 256] 或 None | 提示标准化与张量化 |
_predict | point_coords, point_labels, box, mask_logits, multimask_output, return_logits | masks: [B, 1, H, W], ious: [B, 1], low_res_logits: [B, 1, 256, 256] | 核心 torch 推理路径:提示编码 + 掩码解码 + 后处理上采样 |
get_image_embedding | 无 | image_embed: [1, C, H, W] | 返回缓存的图像嵌入 |
device (property) | 无 | torch.device | 返回模型设备 |
reset_predictor | 无 | 无 | 重置预测器状态,清空缓存 |
PositionEmbeddingSine
文件路径: sam2/modeling/position_encoding.py
类作用: 生成正弦位置编码,用于图像特征的位置嵌入。支持对点、框的编码,以及缓存的 2D 位置编码图。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
num_pos_feats | int | 64 | 位置特征维度(每个方向 x/y 各一半) |
temperature | float | 10000.0 | 正弦函数的温度参数 |
normalize | bool | False | 是否归一化坐标到 [0,1] |
scale | float | 2 * pi | 缩放因子 |
cache | dict | {} | 缓存的位置编码图 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | num_pos_feats=64, temperature=10000.0, normalize=False, scale=2*pi | 无 | 初始化正弦位置编码器 |
_encode_xy | x: [B, N], y: [B, N] | pe: [B, N, num_pos_feats*2] | 对归一化坐标进行 sin/cos 编码 |
encode_boxes | x: [B, N], y: [B, N], w: [B, N], h: [B, N] | pe: [B, N, num_pos_feats*2] | 框中心/尺寸编码(中心坐标 + 宽高) |
encode | 同 encode_boxes | 同 encode_boxes | encode_boxes 的别名 |
encode_points | x: [B, N], y: [B, N], labels: [B, N] | pe: [B, N, num_pos_feats*2] | 点坐标编码,根据标签(正/负)调整相位 |
_pe | B: int, device: torch.device, *cache_key | pe: [B, num_pos_feats*2, H, W] | 生成或命中缓存的 2D 位置编码图 |
forward | x: [B, C, H, W] | pe: [B, num_pos_feats*2, H, W] | 为输入特征图生成位置编码 |
MemoryEncoder
文件路径: sam2/modeling/memory_encoder.py
类作用: 将视觉特征和预测掩码融合编码为记忆特征。包含掩码下采样器、特征投影、融合模块和位置编码。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
mask_downsampler | MaskDownSampler | 无 | 掩码下采样器(卷积层) |
pix_feat_proj | nn.Conv2d | 无 | 视觉特征投影层 |
fuser | Fuser | 无 | 融合模块(多个 CXBlock) |
position_encoding | PositionEmbeddingSine | 无 | 位置编码器 |
out_proj | nn.Conv2d 或 nn.Identity | 无 | 输出投影层(可选压缩通道) |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | mask_downsampler, pix_feat_proj, fuser, position_encoding, out_proj=None | 无 | 初始化记忆编码器组件 |
forward | pix_feat: [B, C, H, W], masks: [B, 1, H*16, W*16], skip_mask_sigmoid=False | dict: {"vision_features": x, "vision_pos_enc": [pos]}x: [B, C', H, W], pos: [1, B, C', H, W] | 掩码下采样 + 与视觉特征融合 + fuser + 位置编码,输出记忆特征和位置编码 |
MemoryAttentionLayer
文件路径: sam2/modeling/memory_attention.py
类作用: 记忆注意力层,包含自注意力和交叉注意力(图像到记忆),以及前馈网络。用于在 MemoryAttention 中堆叠。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
self_attn | nn.Module | 无 | 自注意力层 |
cross_attn_image | nn.Module | 无 | 交叉注意力层(图像到记忆) |
linear1, linear2 | nn.Linear | 无 | 前馈网络线性层 |
norm1, norm2, norm3 | nn.LayerNorm | 无 | 层归一化 |
dropout, dropout1, dropout2, dropout3 | nn.Dropout | 无 | Dropout 层 |
activation | nn.Module | ReLU | 激活函数 |
pos_enc_at_input | bool | False | 是否在输入时添加位置编码 |
batch_first | bool | False | 是否 batch 维度在前 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=nn.ReLU, layer_norm_eps=1e-5, batch_first=False, pos_enc_at_input=False, num_k_exclude_rope=0 | 无 | 初始化注意力层组件 |
_forward_sa | tgt: [seq_len, B, C], query_pos: [seq_len, B, C] 或 None | tgt2: [seq_len, B, C] | 自注意力前向传播 |
_forward_ca | tgt: [seq_len, B, C], memory: [mem_len, B, C], query_pos: [seq_len, B, C] 或 None, pos: [mem_len, B, C] 或 None, num_k_exclude_rope=0 | tgt2: [seq_len, B, C] | 交叉注意力前向传播(图像到记忆) |
forward | curr: [seq_len, B, C], curr_pos: [seq_len, B, C], memory: [mem_len, B, C], memory_pos: [mem_len, B, C] | curr: [seq_len, B, C] | 完整的层前向:自注意力 → 交叉注意力 → FFN |
MemoryAttention
文件路径: sam2/modeling/memory_attention.py
类作用: 记忆注意力模块,堆叠多个 MemoryAttentionLayer,实现自注意力与交叉注意力的多层融合。支持位置编码在输入时添加、batch_first/seq_first 格式转换,以及 RoPE 注意力中的对象指针 token 排除。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
d_model | int | 无 | 模型维度(特征通道数) |
layers | nn.ModuleList | 无 | 堆叠的 MemoryAttentionLayer 实例 |
num_layers | int | 无 | 层数 |
norm | nn.LayerNorm | 无 | 层归一化,应用于最后一层输出 |
pos_enc_at_input | bool | False | 是否在输入时添加位置编码(乘以 0.1) |
batch_first | bool | True | 输入/输出是否为 batch 维度在前(否则为 seq 维度在前) |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | d_model: int, pos_enc_at_input: bool, layer: nn.Module, num_layers: int, batch_first: bool = True | 无 | 初始化记忆注意力模块,克隆指定层并设置归一化 |
forward | curr: [seq_len, B, C] 或 [B, seq_len, C](根据 batch_first)memory: 同 curr 形状curr_pos: 同 curr 形状或 Nonememory_pos: 同 memory 形状或 Nonenum_obj_ptr_tokens: int = 0 | normed_output: 同 curr 形状 | 前向传播:可选输入位置编码 → 格式统一为 seq_first → 逐层自注意力+交叉注意力 → 层归一化 → 格式还原 |
ImageEncoder
文件路径: sam2/modeling/backbones/image_encoder.py
类作用: 图像编码器,包含主干网络(如 Hiera)、FPN 颈部(多尺度特征融合)和可选的 scalp(最高分辨率特征)。输出多尺度视觉特征和位置编码。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
trunk | nn.Module | 无 | 主干网络(如 Hiera) |
neck | FpnNeck | 无 | FPN 颈部,生成多尺度特征 |
scalp | int | 0 | 是否保留最高分辨率特征(0 表示不保留) |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | trunk, neck, scalp=0 | 无 | 初始化图像编码器组件 |
forward | sample: [B, 3, H, W] | dict: {"vision_features": list, "vision_pos_enc": list, "backbone_fpn": list}特征形状: [B, C, H//s, W//s] (s 为各层步长) | 前向传播:主干提取特征 → FPN 颈部多尺度融合 → 添加位置编码 |
MaskDecoder
文件路径: sam2/modeling/sam/mask_decoder.py
类作用: SAM 掩码解码器,基于 Transformer 和超网络生成掩码预测。支持多掩码输出、IoU 预测和对象分数预测。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
transformer_dim | int | 256 | Transformer 维度 |
transformer | TwoWayTransformer | 无 | 双向 Transformer |
num_multimask_outputs | int | 3 | 多掩码输出数量 |
iou_token | nn.Embedding | (1, transformer_dim) | IoU token 嵌入 |
mask_tokens | nn.Embedding | (num_mask_tokens, transformer_dim) | 掩码 token 嵌入 |
num_mask_tokens | int | 4(1 单掩码 + 3 多掩码) | 掩码 token 数量 |
output_upscaling | nn.Sequential | 无 | 输出上采样模块 |
output_hypernetworks_mlps | nn.ModuleList | 无 | 超网络 MLP(每个掩码 token 一个) |
iou_prediction_head | MLP | 无 | IoU 预测头 |
obj_score_token | nn.Embedding 或 None | None | 对象分数 token(如果 pred_obj_scores=True) |
pred_obj_score_head | MLP 或 None | None | 对象分数预测头 |
conv_s0, conv_s1 | nn.Conv2d 或 None | None | 高分辨率特征卷积层(如果 use_high_res_features=True) |
dynamic_multimask_* | 多个参数 | 无 | 动态多掩码稳定性策略相关参数 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | num_multimask_outputs=3, transformer=None, transformer_dim=256, iou_head_depth=3, iou_head_hidden_dim=256, use_high_res_features=False, iou_prediction_use_sigmoid=False, pred_obj_scores=False, pred_obj_scores_mlp=False, use_multimask_token_for_obj_ptr=False, dynamic_multimask_stability_score_thresh=0.95, dynamic_multimask_iou_thresh=0.9, dynamic_multimask_min_stability_score=0.9, dynamic_multimask_max_output_masks=3 | 无 | 初始化掩码解码器,设置 Transformer、token、预测头等 |
forward | image_embeddings: [B, C, H, W], image_pe: [B, C, H, W], sparse_prompt_embeddings: [B, num_prompts, C], dense_prompt_embeddings: [B, C, H, W], multimask_output=False, repeat_image=False, high_res_features=None | masks: [B, num_masks, H*4, W*4], ious: [B, num_masks], output_tokens: [B, num_masks, C], object_score_logits: [B, 1] 或 None | 包装 predict_masks,根据配置选择单/多掩码输出 |
predict_masks | 同 forward 参数 | 同 forward 返回值 | 核心预测流程:token 拼接 → transformer → 超网络生成掩码 → IoU/对象分数预测 |
_get_stability_scores | mask_logits: [B, num_masks, H, W] | scores: [B, num_masks] | 计算掩码稳定性分数 |
_dynamic_multimask_via_stability | all_mask_logits: [B, num_masks, H, W], all_iou_scores: [B, num_masks] | selected_mask_logits: [B, M', H, W], selected_iou_scores: [B, M'] (M’ ≤ max_output_masks) | 通过稳定性分数动态选择多掩码输出 |
PromptEncoder
文件路径: sam2/modeling/sam/prompt_encoder.py
类作用: SAM 提示编码器,将点、框、掩码提示编码为稀疏嵌入和稠密嵌入。包含点嵌入、框嵌入、掩码下采样和位置编码。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
embed_dim | int | 256 | 嵌入维度 |
input_image_size | tuple | (1024, 1024) | 输入图像尺寸 |
image_embedding_size | tuple | (64, 64) | 图像嵌入尺寸(主干输出) |
pe_layer | PositionEmbeddingSine | 无 | 位置编码层 |
num_point_embeddings | int | 4 | 点嵌入数量(正点、负点、框左上、框右下) |
point_embeddings | nn.ModuleList | 无 | 点嵌入层列表 |
not_a_point_embed | nn.Embedding | (1, embed_dim) | ”非点”嵌入(用于填充) |
mask_input_size | tuple | (256, 256) | 掩码输入尺寸 |
mask_downscaling | nn.Sequential | 无 | 掩码下采样模块 |
no_mask_embed | nn.Embedding | (1, embed_dim) | ”无掩码”嵌入 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | embed_dim, image_embedding_size, input_image_size, mask_in_chans=16 | 无 | 初始化提示编码器组件 |
get_dense_pe | 无 | dense_pe: [1, embed_dim, H, W] | 返回稠密位置编码 |
_embed_points | points: [B, P, 2], labels: [B, P], pad: bool | point_embeddings: [B, P, embed_dim] | 嵌入点坐标和标签 |
_embed_boxes | boxes: [B, 4] | box_embeddings: [B, 2, embed_dim] | 嵌入框坐标(左上、右下) |
_embed_masks | masks: [B, 1, mask_input_size[0], mask_input_size[1]] | mask_embeddings: [B, embed_dim, H, W] | 嵌入掩码提示(下采样 + 卷积) |
_get_batch_size | points, boxes, masks | batch_size: int | 从输入中推断批大小 |
_get_device | 无 | device: torch.device | 返回模型设备 |
forward | points=None, boxes=None, masks=None | sparse_embeddings: [B, num_prompts, embed_dim], dense_embeddings: [B, embed_dim, H, W] | 前向传播:编码所有提示类型,返回稀疏和稠密嵌入 |
Hiera
文件路径: sam2/modeling/backbones/hieradet.py
类作用: 分层视觉 Transformer 主干网络,支持多尺度注意力、窗口划分和全局注意力块。用于提取图像的多尺度特征。
属性表格:
| 属性名 | 类型 | 默认值 | 作用描述 |
|---|---|---|---|
window_spec | tuple of tuples | 无 | 各阶段的窗口尺寸规格 |
q_stride | tuple | 无 | 各阶段的查询步长 |
stage_ends | list | 无 | 各阶段结束的块索引 |
q_pool_blocks | list | 无 | 进行查询池化的块索引 |
return_interm_layers | bool | False | 是否返回中间层特征 |
patch_embed | PatchEmbed | 无 | 图像块嵌入层 |
global_att_blocks | list | 无 | 全局注意力块索引 |
window_pos_embed_bkg_spatial_size | tuple | None | 窗口位置编码背景空间尺寸 |
pos_embed | nn.Parameter | (1, C, H, W) | 全局位置编码 |
pos_embed_window | nn.Parameter | (1, C, win_H, win_W) | 窗口位置编码 |
blocks | nn.ModuleList | 无 | 多尺度块列表 |
channel_list | list | 无 | 各阶段输出通道数列表 |
方法表格:
| 方法名 | 参数 | 返回值 | 方法作用 |
|---|---|---|---|
__init__ | window_spec, q_stride, stage_ends, q_pool_blocks, return_interm_layers=False, patch_embed=None, global_att_blocks=(), window_pos_embed_bkg_spatial_size=None | 无 | 初始化 Hiera 主干网络 |
_get_pos_embed | hw: tuple | pos_embed: [1, C, H, W] | 根据空间尺寸获取位置编码 |
forward | x: [B, 3, H, W] | out: dict 或 list of features | 前向传播:提取多尺度特征,可选返回中间层 |
get_layer_id | layer_name: str | layer_id: int | 根据层名获取层索引 |
get_num_layers | 无 | num_layers: int | 返回总层数 |
形状与执行路径总结
- 图像编码:
ImageEncoder.forward-> 多尺度特征 + 位置编码- 输入:
[B, 3, H, W]-> 输出: 多尺度特征列表[B, C, H//s, W//s]
- 输入:
- 记忆融合:
SAM2Base._prepare_memory_conditioned_features->MemoryAttention.forward- 输入: 当前特征
[HW, B, C]+ 记忆 -> 输出: 融合特征[B, C, H, W]
- 输入: 当前特征
- 掩码预测:
SAM2Base._forward_sam_heads->PromptEncoder.forward+MaskDecoder.forward/predict_masks- 输入: 特征
[B, C, H, W]+ 提示 -> 输出: 掩码[B, M, H*4, W*4], IoU[B, M], 对象指针[B, C]
- 输入: 特征
- 记忆写回:
SAM2Base._encode_new_memory->MemoryEncoder.forward- 输入: 特征
[B, C, H, W]+ 掩码[B, 1, H*16, W*16]-> 输出: 记忆特征[B, C, H, W], 位置编码[1, B, C, H, W]
- 输入: 特征
附录:SAM2 核心张量类型详解
在 SAM2 的 Transformer 架构中,存在多种功能的 Token,它们共同完成了从“视觉感知”到“时序记忆”的闭环。
1. Vision Tokens (视觉特征 Token 向量)
- 来源:
ImageEncoder输出,代表图像空间网格上的特征采样。 - 本质: 一个 维特征向量,代表图像在该坐标点的纹理、颜色等高维信息。
- 形状: 常态下为序列
[HW, B, C]。其中每个 的向量即为一个 Token。 - 特性: 携带 2D RoPE。在
MemoryAttention中作为 Query 向量 参与点积运算。
2. Prompt Tokens (提示 Token 向量)
- 来源:
PromptEncoder将用户交互位置编码至嵌入空间。 - 本质:
- 点/框 Token: 为每个交互点生成一个 维位置向量。
- 掩码 Token: 掩码下采样后,每个网格单元也是一个 维描述向量。
- 作用: 在计算相似度时,通过向量空间中的距离来吸引或排斥特定的 Vision Tokens。
3. Memory Tokens (记忆 Token 向量)
- 来源:
MemoryEncoder。 - 本质: 经过掩码加权后的 维视觉记忆向量。
- 作用: 存储物体历史状态的向量集合。
- 位置: 在
MemoryAttention中作为 Key/Value 向量库。
4. Object Pointers (对象指针向量)
- 来源:
MaskDecoder的输出 Token。 - 本质: 对整帧目标的 维语义降维向量。它将整帧物体的信息通过 Attention Pooling 压缩进几个点向量中(通常 16x256)。
- 作用: 作为目标的“向量指纹”,用于跨帧的最高层匹配。
- 特殊处理: 拼接到序列末尾参与矩阵乘法,但不带空间含义。
5. Decoder Queries (解码器查询向量)
- 注意: 这些在严谨术语中更接近 Queries 或 Task Embeddings。
- 来源:
MaskDecoder的初始可学习 Embedding。 - 本质: 它们是进入双向 Transformer 的“初始占位符”。
- 包含:
- Mask Queries: 并不是最终掩码,而是通过注意力机制搜集特征,最终其向量值与特征图做点积来生成掩码。
- IoU Query: 负责汇聚整组特征,最后输入 MLP 回归出一个标量分数。
- Object Score Query: 辅助判断物体是否在当前帧消失。